 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing OpenTitan's Potential: a Silicon-Ready Embedded Secure Element for Root of Trust and Cryptographic Offloading
Jun 17, 2024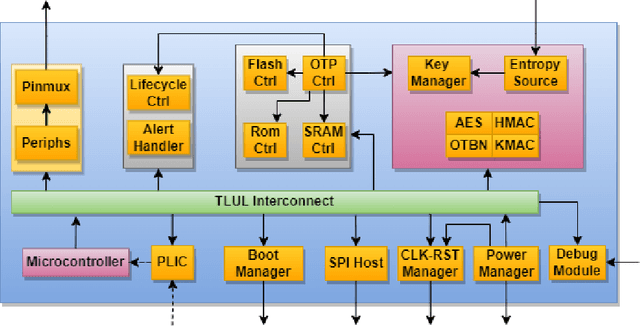

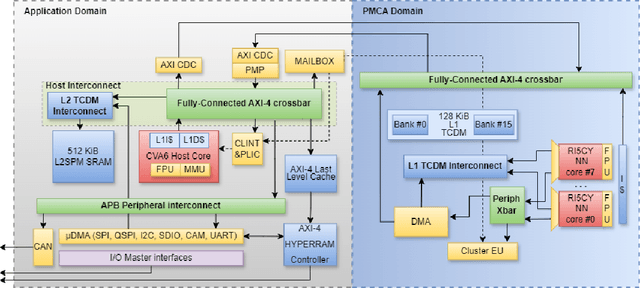
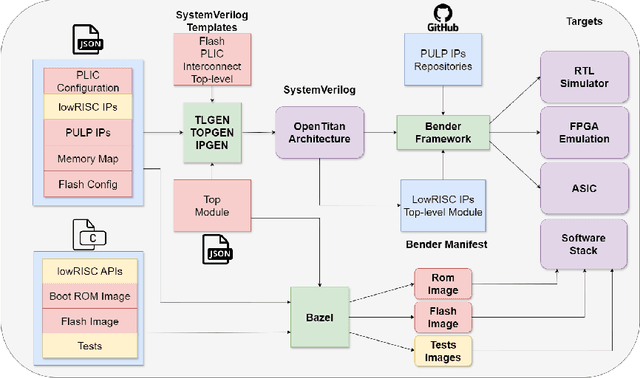
The rapid advancement and exploration of open-hardware RISC-V platforms are driving significant changes in sectors like autonomous vehicles, smart-city infrastructure, and medical devices. OpenTitan stands out as a groundbreaking open-source RISC-V design with a comprehensive security toolkit as a standalone system-on-chip (SoC). OpenTitan includes Earl Grey, a fully implemented and silicon-proven SoC, and Darjeeling, announced but not yet fully implemented. Earl Grey targets standalone SoC implementations, while Darjeeling is for integrable implementations. The literature lacks a silicon-ready embedded implementation of an open-source Root of Trust, despite lowRISC's efforts on Darjeeling. We address the limitations of existing implementations by optimizing data transfer latency between memory and cryptographic accelerators to prevent under-utilization and ensure efficient task acceleration. Our contributions include a comprehensive methodology for integrating custom extensions and IPs into the Earl Grey architecture, architectural enhancements for system-level integration, support for varied boot modes, and improved data movement across the platform. These advancements facilitate deploying OpenTitan in broader SoCs, even without specific technology-dependent IPs, providing a deployment-ready research vehicle for the community. We integrated the extended Earl Grey architecture into a reference architecture in a 22nm FDX technology node, benchmarking the enhanced architecture's performance. The results show significant improvements in cryptographic processing speed, achieving up to 2.7x speedup for SHA-256/HMAC and 1.6x for AES accelerators compared to the baseline Earl Grey architecture.
A Survey on Design Methodologies for Accelerating Deep Learning on Heterogeneous Architectures
Nov 29, 2023
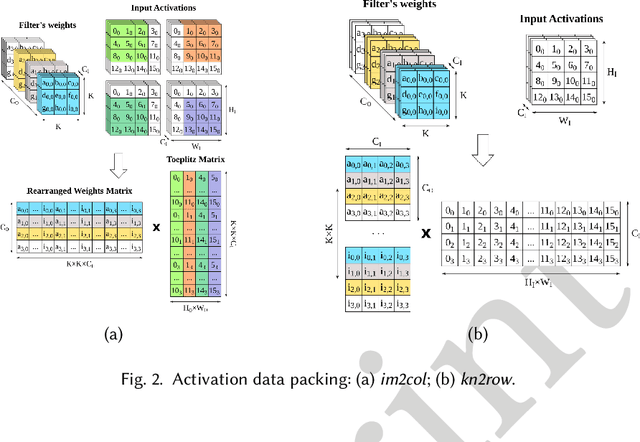
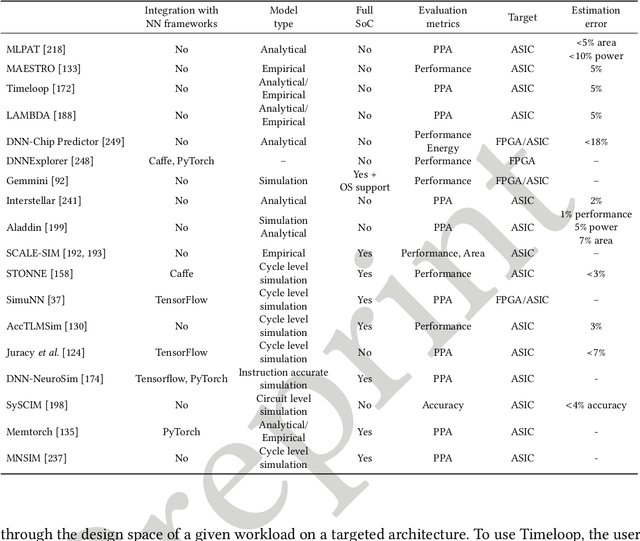

In recent years, the field of Deep Learning has seen many disruptive and impactful advancements. Given the increasing complexity of deep neural networks, the need for efficient hardware accelerators has become more and more pressing to design heterogeneous HPC platforms. The design of Deep Learning accelerators requires a multidisciplinary approach, combining expertise from several areas, spanning from computer architecture to approximate computing, computational models, and machine learning algorithms. Several methodologies and tools have been proposed to design accelerators for Deep Learning, including hardware-software co-design approaches, high-level synthesis methods, specific customized compilers, and methodologies for design space exploration, modeling, and simulation. These methodologies aim to maximize the exploitable parallelism and minimize data movement to achieve high performance and energy efficiency. This survey provides a holistic review of the most influential design methodologies and EDA tools proposed in recent years to implement Deep Learning accelerators, offering the reader a wide perspective in this rapidly evolving field. In particular, this work complements the previous survey proposed by the same authors in [203], which focuses on Deep Learning hardware accelerators for heterogeneous HPC platforms.
Source Code Classification for Energy Efficiency in Parallel Ultra Low-Power Microcontrollers
Dec 12, 2020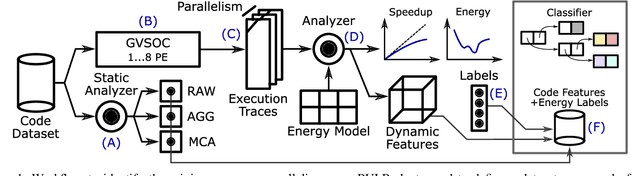
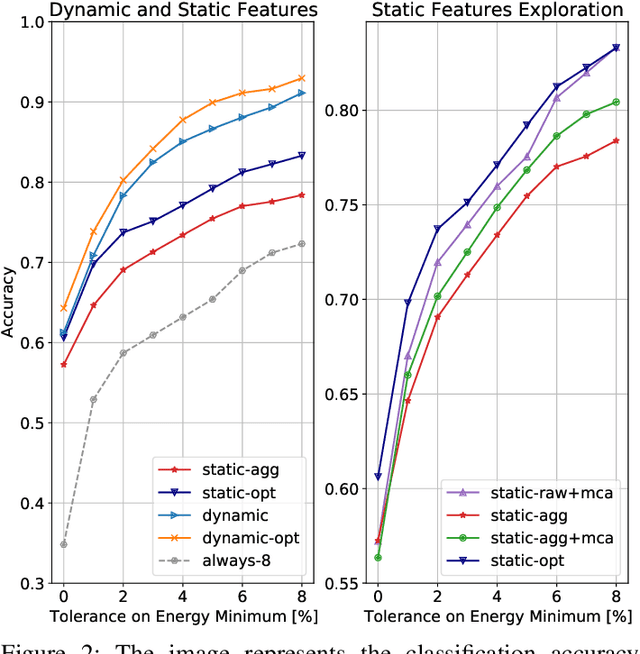
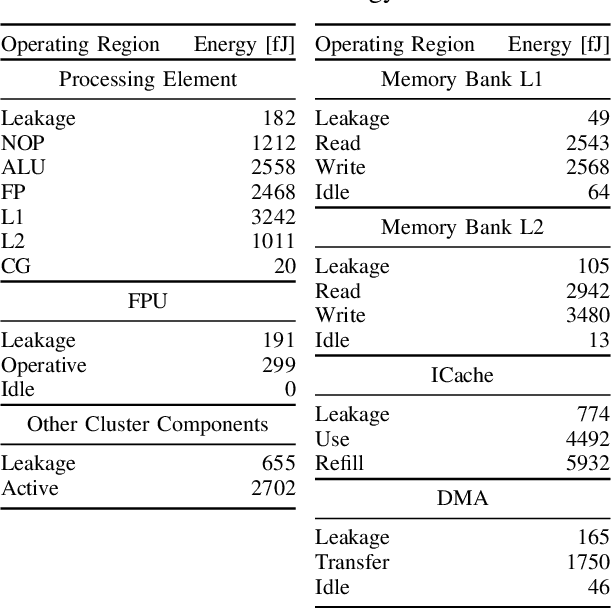

The analysis of source code through machine learning techniques is an increasingly explored research topic aiming at increasing smartness in the software toolchain to exploit modern architectures in the best possible way. In the case of low-power, parallel embedded architectures, this means finding the configuration, for instance in terms of the number of cores, leading to minimum energy consumption. Depending on the kernel to be executed, the energy optimal scaling configuration is not trivial. While recent work has focused on general-purpose systems to learn and predict the best execution target in terms of the execution time of a snippet of code or kernel (e.g. offload OpenCL kernel on multicore CPU or GPU), in this work we focus on static compile-time features to assess if they can be successfully used to predict the minimum energy configuration on PULP, an ultra-low-power architecture featuring an on-chip cluster of RISC-V processors. Experiments show that using machine learning models on the source code to select the best energy scaling configuration automatically is viable and has the potential to be used in the context of automatic system configuration for energy minimisation.