 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case for Hypergraphs to Model and Map SNNs on Neuromorphic Hardware
Jan 22, 2026Executing Spiking Neural Networks (SNNs) on neuromorphic hardware poses the problem of mapping neurons to cores. SNNs operate by propagating spikes between neurons that form a graph through synapses. Neuromorphic hardware mimics them through a network-on-chip, transmitting spikes, and a mesh of cores, each managing several neurons. Its operational cost is tied to spike movement and active cores. A mapping comprises two tasks: partitioning the SNN's graph to fit inside cores and placement of each partition on the hardware mesh. Both are NP-hard problems, and as SNNs and hardware scale towards billions of neurons, they become increasingly difficult to tackle effectively. In this work, we propose to raise the abstraction of SNNs from graphs to hypergraphs, redesigning mapping techniques accordingly. The resulting model faithfully captures the replication of spikes inside cores by exposing the notion of hyperedge co-membership between neurons. We further show that the overlap and locality of hyperedges strongly correlate with high-quality mappings, making these properties instrumental in devising mapping algorithms. By exploiting them directly, grouping neurons through shared hyperedges, communication traffic and hardware resource usage can be reduced be yond what just contracting individual connections attains. To substantiate this insight, we consider several partitioning and placement algorithms, some newly devised, others adapted from literature, and compare them over progressively larger and bio-plausible SNNs. Our results show that hypergraph based techniques can achieve better mappings than the state-of-the-art at several execution time regimes. Based on these observations, we identify a promising selection of algorithms to achieve effective mappings at any scale.
A Survey on Design Methodologies for Accelerating Deep Learning on Heterogeneous Architectures
Nov 29, 2023
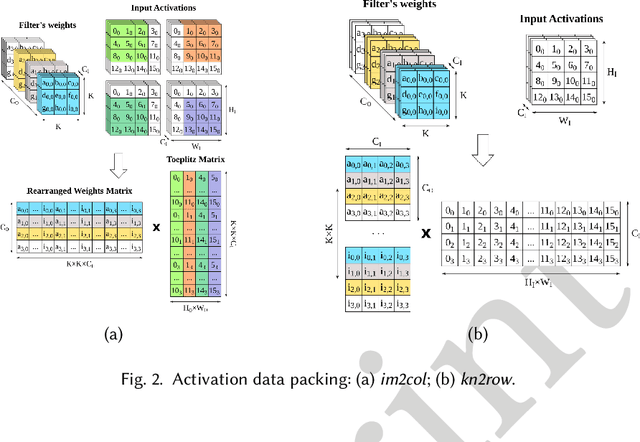
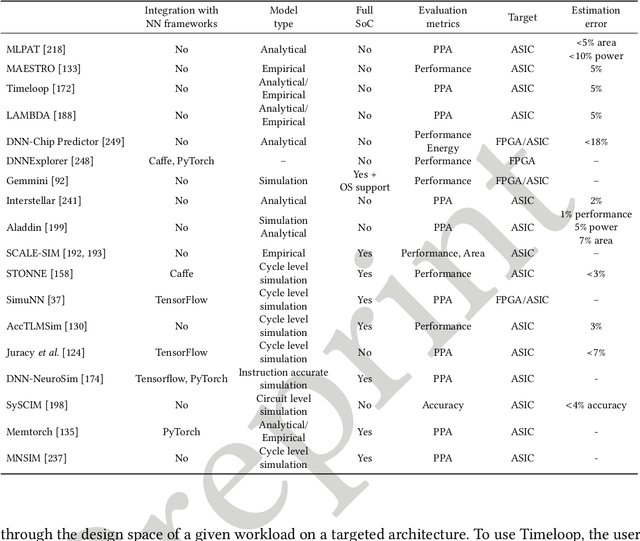

In recent years, the field of Deep Learning has seen many disruptive and impactful advancements. Given the increasing complexity of deep neural networks, the need for efficient hardware accelerators has become more and more pressing to design heterogeneous HPC platforms. The design of Deep Learning accelerators requires a multidisciplinary approach, combining expertise from several areas, spanning from computer architecture to approximate computing, computational models, and machine learning algorithms. Several methodologies and tools have been proposed to design accelerators for Deep Learning, including hardware-software co-design approaches, high-level synthesis methods, specific customized compilers, and methodologies for design space exploration, modeling, and simulation. These methodologies aim to maximize the exploitable parallelism and minimize data movement to achieve high performance and energy efficiency. This survey provides a holistic review of the most influential design methodologies and EDA tools proposed in recent years to implement Deep Learning accelerators, offering the reader a wide perspective in this rapidly evolving field. In particular, this work complements the previous survey proposed by the same authors in [203], which focuses on Deep Learning hardware accelerators for heterogeneous HPC platforms.
A Survey on Deep Learning Hardware Accelerators for Heterogeneous HPC Platforms
Jun 27, 2023



Recent trends in deep learning (DL) imposed hardware accelerators as the most viable solution for several classes of high-performance computing (HPC) applications such as image classification, computer vision, and speech recognition. This survey summarizes and classifies the most recent advances in designing DL accelerators suitable to reach the performance requirements of HPC applications. In particular, it highlights the most advanced approaches to support deep learning accelerations including not only GPU and TPU-based accelerators but also design-specific hardware accelerators such as FPGA-based and ASIC-based accelerators, Neural Processing Units, open hardware RISC-V-based accelerators and co-processors. The survey also describes accelerators based on emerging memory technologies and computing paradigms, such as 3D-stacked Processor-In-Memory, non-volatile memories (mainly, Resistive RAM and Phase Change Memories) to implement in-memory computing, Neuromorphic Processing Units, and accelerators based on Multi-Chip Modules. The survey classifies the most influential architectures and technologies proposed in the last years, with the purpose of offering the reader a comprehensive perspective in the rapidly evolving field of deep learning. Finally, it provides some insights into future challenges in DL accelerators such as quantum accelerators and photonics.
A Survey on Compiler Autotuning using Machine Learning
Sep 03, 2018

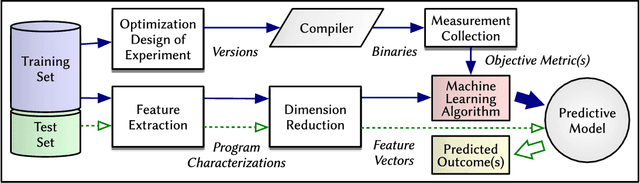
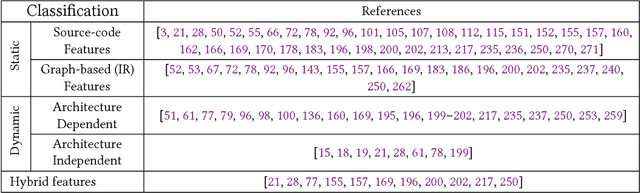
Since the mid-1990s, researchers have been trying to use machine-learning based approaches to solve a number of different compiler optimization problems. These techniques primarily enhance the quality of the obtained results and, more importantly, make it feasible to tackle two main compiler optimization problems: optimization selection (choosing which optimizations to apply) and phase-ordering (choosing the order of applying optimizations). The compiler optimization space continues to grow due to the advancement of applications, increasing number of compiler optimizations, and new target architectures. Generic optimization passes in compilers cannot fully leverage newly introduced optimizations and, therefore, cannot keep up with the pace of increasing options. This survey summarizes and classifies the recent advances in using machine learning for the compiler optimization field, particularly on the two major problems of (1) selecting the best optimizations and (2) the phase-ordering of optimizations. The survey highlights the approaches taken so far, the obtained results, the fine-grain classification among different approaches and finally, the influential papers of the field.