 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
A Survey on Design Methodologies for Accelerating Deep Learning on Heterogeneous Architectures
Nov 29, 2023
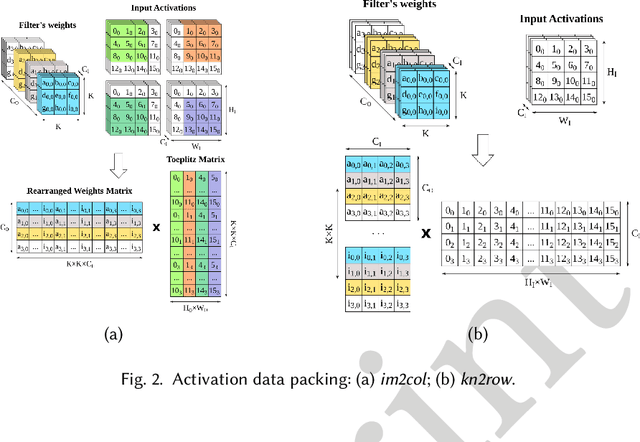
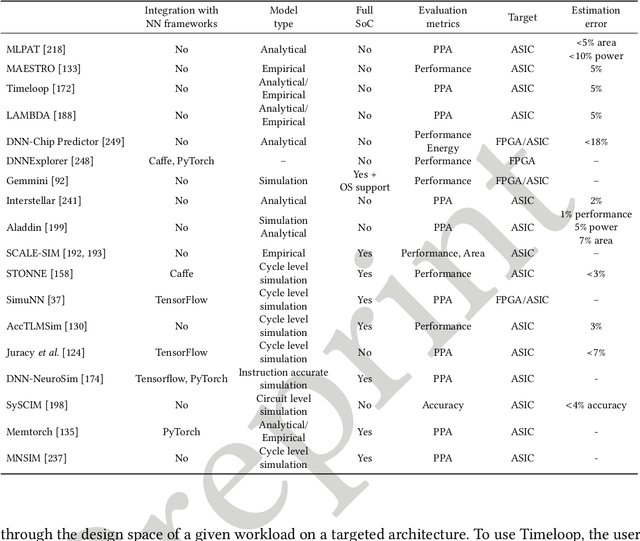

In recent years, the field of Deep Learning has seen many disruptive and impactful advancements. Given the increasing complexity of deep neural networks, the need for efficient hardware accelerators has become more and more pressing to design heterogeneous HPC platforms. The design of Deep Learning accelerators requires a multidisciplinary approach, combining expertise from several areas, spanning from computer architecture to approximate computing, computational models, and machine learning algorithms. Several methodologies and tools have been proposed to design accelerators for Deep Learning, including hardware-software co-design approaches, high-level synthesis methods, specific customized compilers, and methodologies for design space exploration, modeling, and simulation. These methodologies aim to maximize the exploitable parallelism and minimize data movement to achieve high performance and energy efficiency. This survey provides a holistic review of the most influential design methodologies and EDA tools proposed in recent years to implement Deep Learning accelerators, offering the reader a wide perspective in this rapidly evolving field. In particular, this work complements the previous survey proposed by the same authors in [203], which focuses on Deep Learning hardware accelerators for heterogeneous HPC platforms.
A Survey on Deep Learning Hardware Accelerators for Heterogeneous HPC Platforms
Jun 27, 2023



Recent trends in deep learning (DL) imposed hardware accelerators as the most viable solution for several classes of high-performance computing (HPC) applications such as image classification, computer vision, and speech recognition. This survey summarizes and classifies the most recent advances in designing DL accelerators suitable to reach the performance requirements of HPC applications. In particular, it highlights the most advanced approaches to support deep learning accelerations including not only GPU and TPU-based accelerators but also design-specific hardware accelerators such as FPGA-based and ASIC-based accelerators, Neural Processing Units, open hardware RISC-V-based accelerators and co-processors. The survey also describes accelerators based on emerging memory technologies and computing paradigms, such as 3D-stacked Processor-In-Memory, non-volatile memories (mainly, Resistive RAM and Phase Change Memories) to implement in-memory computing, Neuromorphic Processing Units, and accelerators based on Multi-Chip Modules. The survey classifies the most influential architectures and technologies proposed in the last years, with the purpose of offering the reader a comprehensive perspective in the rapidly evolving field of deep learning. Finally, it provides some insights into future challenges in DL accelerators such as quantum accelerators and photonics.
Binary stochasticity enabled highly efficient neuromorphic deep learning achieves better-than-software accuracy
Apr 25, 2023Deep learning needs high-precision handling of forwarding signals, backpropagating errors, and updating weights. This is inherently required by the learning algorithm since the gradient descent learning rule relies on the chain product of partial derivatives. However, it is challenging to implement deep learning in hardware systems that use noisy analog memristors as artificial synapses, as well as not being biologically plausible. Memristor-based implementations generally result in an excessive cost of neuronal circuits and stringent demands for idealized synaptic devices. Here, we demonstrate that the requirement for high precision is not necessary and that more efficient deep learning can be achieved when this requirement is lifted. We propose a binary stochastic learning algorithm that modifies all elementary neural network operations, by introducing (i) stochastic binarization of both the forwarding signals and the activation function derivatives, (ii) signed binarization of the backpropagating errors, and (iii) step-wised weight updates. Through an extensive hybrid approach of software simulation and hardware experiments, we find that binary stochastic deep learning systems can provide better performance than the software-based benchmarks using the high-precision learning algorithm. Also, the binary stochastic algorithm strongly simplifies the neural network operations in hardware, resulting in an improvement of the energy efficiency for the multiply-and-accumulate operations by more than three orders of magnitudes.
Tutorial: Analog Matrix Computing (AMC) with Crosspoint Resistive Memory Arrays
May 12, 2022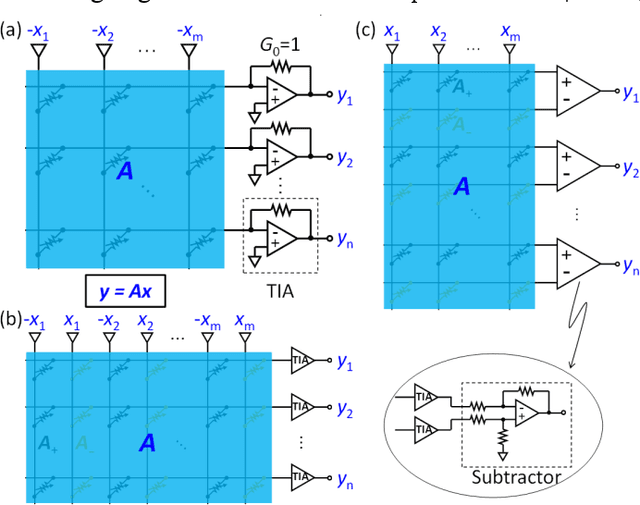
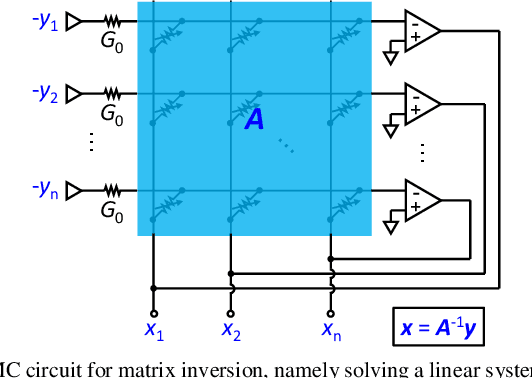
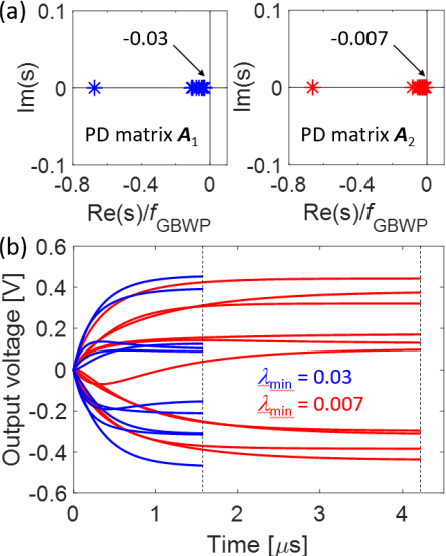
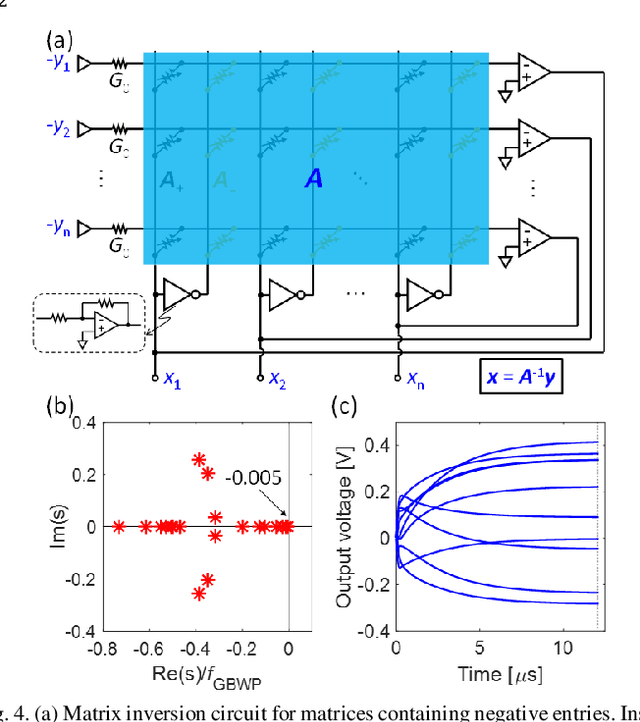
Matrix computation is ubiquitous in modern scientific and engineering fields. Due to the high computational complexity in conventional digital computers, matrix computation represents a heavy workload in many data-intensive applications, e.g., machine learning, scientific computing, and wireless communications. For fast, efficient matrix computations, analog computing with resistive memory arrays has been proven to be a promising solution. In this Tutorial, we present analog matrix computing (AMC) circuits based on crosspoint resistive memory arrays. AMC circuits are able to carry out basic matrix computations, including matrix multiplication, matrix inversion, pseudoinverse and eigenvector computation, all with one single operation. We describe the main design principles of the AMC circuits, such as local/global or negative/positive feedback configurations, with/without external inputs. Mapping strategies for matrices containing negative values will be presented. The underlying requirements for circuit stability will be described via the transfer function analysis, which also defines time complexity of the circuits towards steady-state results. Lastly, typical applications, challenges, and future trends of AMC circuits will be discussed.
One-step regression and classification with crosspoint resistive memory arrays
May 05, 2020Machine learning has been getting a large attention in the recent years, as a tool to process big data generated by ubiquitous sensors in our daily life. High speed, low energy computing machines are in demand to enable real-time artificial intelligence at the edge, i.e., without the support of a remote frame server in the cloud. Such requirements challenge the complementary metal-oxide-semiconductor (CMOS) technology, which is limited by the Moore's law approaching its end and the communication bottleneck in conventional computing architecture. Novel computing concepts, architectures and devices are thus strongly needed to accelerate data-intensive applications. Here we show a crosspoint resistive memory circuit with feedback configuration can execute linear regression and logistic regression in just one step by computing the pseudoinverse matrix of the data within the memory. The most elementary learning operation, that is the regression of a sequence of data and the classification of a set of data, can thus be executed in one single computational step by the novel technology. One-step learning is further supported by simulations of the prediction of the cost of a house in Boston and the training of a 2-layer neural network for MNIST digit recognition. The results are all obtained in one computational step, thanks to the physical, parallel, and analog computing within the crosspoint array.
* 24 pages, 4 figures