 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Spiking Neurons for Vision and Language Modeling
Apr 14, 2026Regarded as the third generation of neural networks, Spiking Neural Networks (SNNs) have garnered significant traction due to their biological plausibility and energy efficiency. Recent advancements in large models necessitate spiking neurons capable of high performance, adaptability, and training efficiency. In this work, we first propose a novel functional perspective that provides general guidance for designing the new generation of spiking neurons. Following the insightful guidelines, we propose the Adaptive Spiking Neuron (ASN), which incorporates trainable parameters to learn membrane potential dynamics and enable adaptive firing. ASN adopts an integer training and spike inference paradigm, facilitating efficient SNN training. To further enhance robustness, we propose a specialized variant of ASN, the Normalized Adaptive Spiking Neuron (NASN), which integrates normalization to stabilize training. We evaluate our neuron model on 19 datasets spanning five distinct tasks in both vision and language modalities, demonstrating the effectiveness and versatility of the ASN family. Our ASN family is expected to become the new generation of general-purpose spiking neurons.
Winner-Take-All Spiking Transformer for Language Modeling
Apr 13, 2026Spiking Transformers, which combine the scalability of Transformers with the sparse, energy-efficient property of Spiking Neural Networks (SNNs), have achieved impressive results in neuromorphic and vision tasks and attracted increasing attention. However, existing directly trained spiking transformers primarily focus on vision tasks. For language modeling with spiking transformer, convergence relies heavily on softmax-based spiking self-attention, which incurs high energy costs and poses challenges for neuromorphic deployment. To address this issue, we introduce Winner-Take-All (WTA) mechanisms into spiking transformers and propose two novel softmax-free, spike-driven self-attention modules: WTA Spiking Self-Attention (WSSA) and Causal WTA Spiking Self-Attention (CWSSA). Based on them, we design WTA-based Encoder-only Spiking Transformer (WE-Spikingformer) for masked language modeling and WTA-based Decoder-only Spiking Transformer (WD-Spikingformer) for causal language modeling, systematically exploring softmax-free, spiking-driven Transformer architectures trained end-to-end for natural language processing tasks. Extensive experiments on 16 datasets spanning natural language understanding, question-answering tasks, and commonsense reasoning tasks validate the effectiveness of our approach and highlight the promise of spiking transformers for general language modeling and energy-efficient artificial intelligence.
Hierarchical Zero-Order Optimization for Deep Neural Networks
Feb 11, 2026Zeroth-order (ZO) optimization has long been favored for its biological plausibility and its capacity to handle non-differentiable objectives, yet its computational complexity has historically limited its application in deep neural networks. Challenging the conventional paradigm that gradients propagate layer-by-layer, we propose Hierarchical Zeroth-Order (HZO) optimization, a novel divide-and-conquer strategy that decomposes the depth dimension of the network. We prove that HZO reduces the query complexity from $O(ML^2)$ to $O(ML \log L)$ for a network of width $M$ and depth $L$, representing a significant leap over existing ZO methodologies. Furthermore, we provide a detailed error analysis showing that HZO maintains numerical stability by operating near the unitary limit ($L_{lip} \approx 1$). Extensive evaluations on CIFAR-10 and ImageNet demonstrate that HZO achieves competitive accuracy compared to backpropagation.
BrainFuse: a unified infrastructure integrating realistic biological modeling and core AI methodology
Jan 29, 2026Neuroscience and artificial intelligence represent distinct yet complementary pathways to general intelligence. However, amid the ongoing boom in AI research and applications, the translational synergy between these two fields has grown increasingly elusive-hampered by a widening infrastructural incompatibility: modern AI frameworks lack native support for biophysical realism, while neural simulation tools are poorly suited for gradient-based optimization and neuromorphic hardware deployment. To bridge this gap, we introduce BrainFuse, a unified infrastructure that provides comprehensive support for biophysical neural simulation and gradient-based learning. By addressing algorithmic, computational, and deployment challenges, BrainFuse exhibits three core capabilities: (1) algorithmic integration of detailed neuronal dynamics into a differentiable learning framework; (2) system-level optimization that accelerates customizable ion-channel dynamics by up to 3,000x on GPUs; and (3) scalable computation with highly compatible pipelines for neuromorphic hardware deployment. We demonstrate this full-stack design through both AI and neuroscience tasks, from foundational neuron simulation and functional cylinder modeling to real-world deployment and application scenarios. For neuroscience, BrainFuse supports multiscale biological modeling, enabling the deployment of approximately 38,000 Hodgkin-Huxley neurons with 100 million synapses on a single neuromorphic chip while consuming as low as 1.98 W. For AI, BrainFuse facilitates the synergistic application of realistic biological neuron models, demonstrating enhanced robustness to input noise and improved temporal processing endowed by complex HH dynamics. BrainFuse therefore serves as a foundational engine to facilitate cross-disciplinary research and accelerate the development of next-generation bio-inspired intelligent systems.
SpikCommander: A High-performance Spiking Transformer with Multi-view Learning for Efficient Speech Command Recognition
Nov 13, 2025Spiking neural networks (SNNs) offer a promising path toward energy-efficient speech command recognition (SCR) by leveraging their event-driven processing paradigm. However, existing SNN-based SCR methods often struggle to capture rich temporal dependencies and contextual information from speech due to limited temporal modeling and binary spike-based representations. To address these challenges, we first introduce the multi-view spiking temporal-aware self-attention (MSTASA) module, which combines effective spiking temporal-aware attention with a multi-view learning framework to model complementary temporal dependencies in speech commands. Building on MSTASA, we further propose SpikCommander, a fully spike-driven transformer architecture that integrates MSTASA with a spiking contextual refinement channel MLP (SCR-MLP) to jointly enhance temporal context modeling and channel-wise feature integration. We evaluate our method on three benchmark datasets: the Spiking Heidelberg Dataset (SHD), the Spiking Speech Commands (SSC), and the Google Speech Commands V2 (GSC). Extensive experiments demonstrate that SpikCommander consistently outperforms state-of-the-art (SOTA) SNN approaches with fewer parameters under comparable time steps, highlighting its effectiveness and efficiency for robust speech command recognition.
A Self-Ensemble Inspired Approach for Effective Training of Binary-Weight Spiking Neural Networks
Aug 18, 2025Spiking Neural Networks (SNNs) are a promising approach to low-power applications on neuromorphic hardware due to their energy efficiency. However, training SNNs is challenging because of the non-differentiable spike generation function. To address this issue, the commonly used approach is to adopt the backpropagation through time framework, while assigning the gradient of the non-differentiable function with some surrogates. Similarly, Binary Neural Networks (BNNs) also face the non-differentiability problem and rely on approximating gradients. However, the deep relationship between these two fields and how their training techniques can benefit each other has not been systematically researched. Furthermore, training binary-weight SNNs is even more difficult. In this work, we present a novel perspective on the dynamics of SNNs and their close connection to BNNs through an analysis of the backpropagation process. We demonstrate that training a feedforward SNN can be viewed as training a self-ensemble of a binary-activation neural network with noise injection. Drawing from this new understanding of SNN dynamics, we introduce the Self-Ensemble Inspired training method for (Binary-Weight) SNNs (SEI-BWSNN), which achieves high-performance results with low latency even for the case of the 1-bit weights. Specifically, we leverage a structure of multiple shortcuts and a knowledge distillation-based training technique to improve the training of (binary-weight) SNNs. Notably, by binarizing FFN layers in a Transformer architecture, our approach achieves 82.52% accuracy on ImageNet with only 2 time steps, indicating the effectiveness of our methodology and the potential of binary-weight SNNs.
S$^2$M-Former: Spiking Symmetric Mixing Branchformer for Brain Auditory Attention Detection
Aug 07, 2025



Auditory attention detection (AAD) aims to decode listeners' focus in complex auditory environments from electroencephalography (EEG) recordings, which is crucial for developing neuro-steered hearing devices. Despite recent advancements, EEG-based AAD remains hindered by the absence of synergistic frameworks that can fully leverage complementary EEG features under energy-efficiency constraints. We propose S$^2$M-Former, a novel spiking symmetric mixing framework to address this limitation through two key innovations: i) Presenting a spike-driven symmetric architecture composed of parallel spatial and frequency branches with mirrored modular design, leveraging biologically plausible token-channel mixers to enhance complementary learning across branches; ii) Introducing lightweight 1D token sequences to replace conventional 3D operations, reducing parameters by 14.7$\times$. The brain-inspired spiking architecture further reduces power consumption, achieving a 5.8$\times$ energy reduction compared to recent ANN methods, while also surpassing existing SNN baselines in terms of parameter efficiency and performance. Comprehensive experiments on three AAD benchmarks (KUL, DTU and AV-GC-AAD) across three settings (within-trial, cross-trial and cross-subject) demonstrate that S$^2$M-Former achieves comparable state-of-the-art (SOTA) decoding accuracy, making it a promising low-power, high-performance solution for AAD tasks.
Channel-wise Parallelizable Spiking Neuron with Multiplication-free Dynamics and Large Temporal Receptive Fields
Jan 24, 2025Spiking Neural Networks (SNNs) are distinguished from Artificial Neural Networks (ANNs) for their sophisticated neuronal dynamics and sparse binary activations (spikes) inspired by the biological neural system. Traditional neuron models use iterative step-by-step dynamics, resulting in serial computation and slow training speed of SNNs. Recently, parallelizable spiking neuron models have been proposed to fully utilize the massive parallel computing ability of graphics processing units to accelerate the training of SNNs. However, existing parallelizable spiking neuron models involve dense floating operations and can only achieve high long-term dependencies learning ability with a large order at the cost of huge computational and memory costs. To solve the dilemma of performance and costs, we propose the mul-free channel-wise Parallel Spiking Neuron, which is hardware-friendly and suitable for SNNs' resource-restricted application scenarios. The proposed neuron imports the channel-wise convolution to enhance the learning ability, induces the sawtooth dilations to reduce the neuron order, and employs the bit shift operation to avoid multiplications. The algorithm for design and implementation of acceleration methods is discussed meticulously. Our methods are validated in neuromorphic Spiking Heidelberg Digits voices, sequential CIFAR images, and neuromorphic DVS-Lip vision datasets, achieving the best accuracy among SNNs. Training speed results demonstrate the effectiveness of our acceleration methods, providing a practical reference for future research.
Efficient Speech Command Recognition Leveraging Spiking Neural Network and Curriculum Learning-based Knowledge Distillation
Dec 17, 2024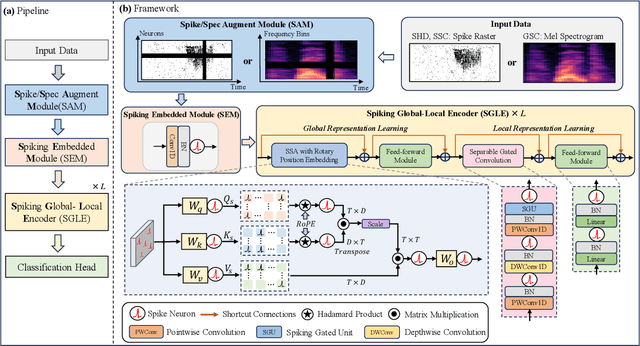
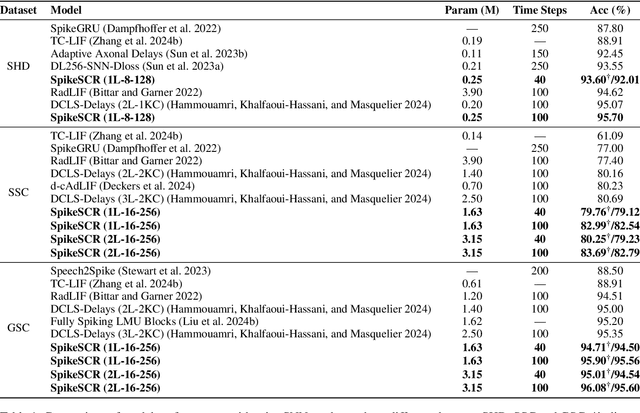
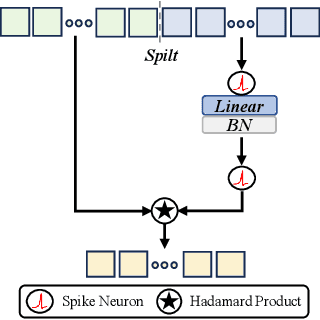

The intrinsic dynamics and event-driven nature of spiking neural networks (SNNs) make them excel in processing temporal information by naturally utilizing embedded time sequences as time steps. Recent studies adopting this approach have demonstrated SNNs' effectiveness in speech command recognition, achieving high performance by employing large time steps for long time sequences. However, the large time steps lead to increased deployment burdens for edge computing applications. Thus, it is important to balance high performance and low energy consumption when detecting temporal patterns in edge devices. Our solution comprises two key components. 1). We propose a high-performance fully spike-driven framework termed SpikeSCR, characterized by a global-local hybrid structure for efficient representation learning, which exhibits long-term learning capabilities with extended time steps. 2). To further fully embrace low energy consumption, we propose an effective knowledge distillation method based on curriculum learning (KDCL), where valuable representations learned from the easy curriculum are progressively transferred to the hard curriculum with minor loss, striking a trade-off between power efficiency and high performance. We evaluate our method on three benchmark datasets: the Spiking Heidelberg Dataset (SHD), the Spiking Speech Commands (SSC), and the Google Speech Commands (GSC) V2. Our experimental results demonstrate that SpikeSCR outperforms current state-of-the-art (SOTA) methods across these three datasets with the same time steps. Furthermore, by executing KDCL, we reduce the number of time steps by 60% and decrease energy consumption by 54.8% while maintaining comparable performance to recent SOTA results. Therefore, this work offers valuable insights for tackling temporal processing challenges with long time sequences in edge neuromorphic computing systems.
A High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024
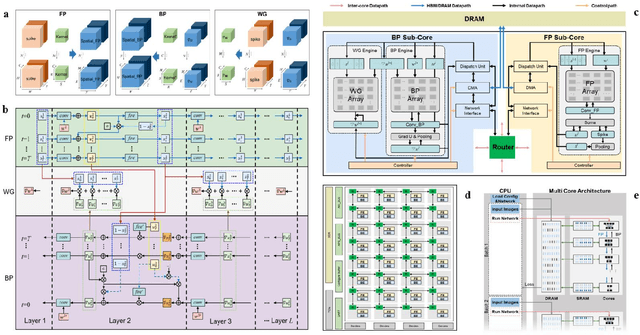
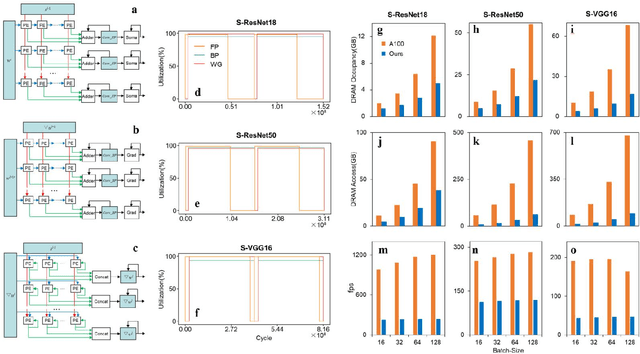
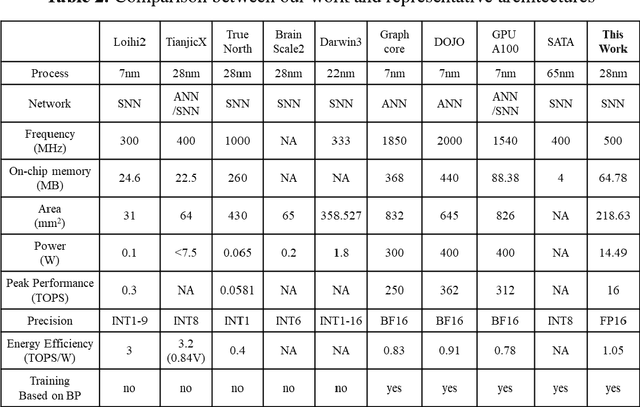
There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.