 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern-Aware Diffusion Synthesis of fMRI/dMRI with Tissue and Microstructural Refinement
Nov 07, 2025Magnetic resonance imaging (MRI), especially functional MRI (fMRI) and diffusion MRI (dMRI), is essential for studying neurodegenerative diseases. However, missing modalities pose a major barrier to their clinical use. Although GAN- and diffusion model-based approaches have shown some promise in modality completion, they remain limited in fMRI-dMRI synthesis due to (1) significant BOLD vs. diffusion-weighted signal differences between fMRI and dMRI in time/gradient axis, and (2) inadequate integration of disease-related neuroanatomical patterns during generation. To address these challenges, we propose PDS, introducing two key innovations: (1) a pattern-aware dual-modal 3D diffusion framework for cross-modality learning, and (2) a tissue refinement network integrated with a efficient microstructure refinement to maintain structural fidelity and fine details. Evaluated on OASIS-3, ADNI, and in-house datasets, our method achieves state-of-the-art results, with PSNR/SSIM scores of 29.83 dB/90.84\% for fMRI synthesis (+1.54 dB/+4.12\% over baselines) and 30.00 dB/77.55\% for dMRI synthesis (+1.02 dB/+2.2\%). In clinical validation, the synthesized data show strong diagnostic performance, achieving 67.92\%/66.02\%/64.15\% accuracy (NC vs. MCI vs. AD) in hybrid real-synthetic experiments. Code is available in \href{https://github.com/SXR3015/PDS}{PDS GitHub Repository}
BrainCSD: A Hierarchical Consistency-Driven MoE Foundation Model for Unified Connectome Synthesis and Multitask Brain Trait Prediction
Nov 07, 2025Functional and structural connectivity (FC/SC) are key multimodal biomarkers for brain analysis, yet their clinical utility is hindered by costly acquisition, complex preprocessing, and frequent missing modalities. Existing foundation models either process single modalities or lack explicit mechanisms for cross-modal and cross-scale consistency. We propose BrainCSD, a hierarchical mixture-of-experts (MoE) foundation model that jointly synthesizes FC/SC biomarkers and supports downstream decoding tasks (diagnosis and prediction). BrainCSD features three neuroanatomically grounded components: (1) a ROI-specific MoE that aligns regional activations from canonical networks (e.g., DMN, FPN) with a global atlas via contrastive consistency; (2) a Encoding-Activation MOE that models dynamic cross-time/gradient dependencies in fMRI/dMRI; and (3) a network-aware refinement MoE that enforces structural priors and symmetry at individual and population levels. Evaluated on the datasets under complete and missing-modality settings, BrainCSD achieves SOTA results: 95.6\% accuracy for MCI vs. CN classification without FC, low synthesis error (FC RMSE: 0.038; SC RMSE: 0.006), brain age prediction (MAE: 4.04 years), and MMSE score estimation (MAE: 1.72 points). Code is available in \href{https://github.com/SXR3015/BrainCSD}{BrainCSD}
S$^2$M-Former: Spiking Symmetric Mixing Branchformer for Brain Auditory Attention Detection
Aug 07, 2025



Auditory attention detection (AAD) aims to decode listeners' focus in complex auditory environments from electroencephalography (EEG) recordings, which is crucial for developing neuro-steered hearing devices. Despite recent advancements, EEG-based AAD remains hindered by the absence of synergistic frameworks that can fully leverage complementary EEG features under energy-efficiency constraints. We propose S$^2$M-Former, a novel spiking symmetric mixing framework to address this limitation through two key innovations: i) Presenting a spike-driven symmetric architecture composed of parallel spatial and frequency branches with mirrored modular design, leveraging biologically plausible token-channel mixers to enhance complementary learning across branches; ii) Introducing lightweight 1D token sequences to replace conventional 3D operations, reducing parameters by 14.7$\times$. The brain-inspired spiking architecture further reduces power consumption, achieving a 5.8$\times$ energy reduction compared to recent ANN methods, while also surpassing existing SNN baselines in terms of parameter efficiency and performance. Comprehensive experiments on three AAD benchmarks (KUL, DTU and AV-GC-AAD) across three settings (within-trial, cross-trial and cross-subject) demonstrate that S$^2$M-Former achieves comparable state-of-the-art (SOTA) decoding accuracy, making it a promising low-power, high-performance solution for AAD tasks.
AQuilt: Weaving Logic and Self-Inspection into Low-Cost, High-Relevance Data Synthesis for Specialist LLMs
Jul 24, 2025Despite the impressive performance of large language models (LLMs) in general domains, they often underperform in specialized domains. Existing approaches typically rely on data synthesis methods and yield promising results by using unlabeled data to capture domain-specific features. However, these methods either incur high computational costs or suffer from performance limitations, while also demonstrating insufficient generalization across different tasks. To address these challenges, we propose AQuilt, a framework for constructing instruction-tuning data for any specialized domains from corresponding unlabeled data, including Answer, Question, Unlabeled data, Inspection, Logic, and Task type. By incorporating logic and inspection, we encourage reasoning processes and self-inspection to enhance model performance. Moreover, customizable task instructions enable high-quality data generation for any task. As a result, we construct a dataset of 703k examples to train a powerful data synthesis model. Experiments show that AQuilt is comparable to DeepSeek-V3 while utilizing just 17% of the production cost. Further analysis demonstrates that our generated data exhibits higher relevance to downstream tasks. Source code, models, and scripts are available at https://github.com/Krueske/AQuilt.
EEG-ReMinD: Enhancing Neurodegenerative EEG Decoding through Self-Supervised State Reconstruction-Primed Riemannian Dynamics
Jan 14, 2025



The development of EEG decoding algorithms confronts challenges such as data sparsity, subject variability, and the need for precise annotations, all of which are vital for advancing brain-computer interfaces and enhancing the diagnosis of diseases. To address these issues, we propose a novel two-stage approach named Self-Supervised State Reconstruction-Primed Riemannian Dynamics (EEG-ReMinD) , which mitigates reliance on supervised learning and integrates inherent geometric features. This approach efficiently handles EEG data corruptions and reduces the dependency on labels. EEG-ReMinD utilizes self-supervised and geometric learning techniques, along with an attention mechanism, to analyze the temporal dynamics of EEG features within the framework of Riemannian geometry, referred to as Riemannian dynamics. Comparative analyses on both intact and corrupted datasets from two different neurodegenerative disorders underscore the enhanced performance of EEG-ReMinD.
Efficient Speech Command Recognition Leveraging Spiking Neural Network and Curriculum Learning-based Knowledge Distillation
Dec 17, 2024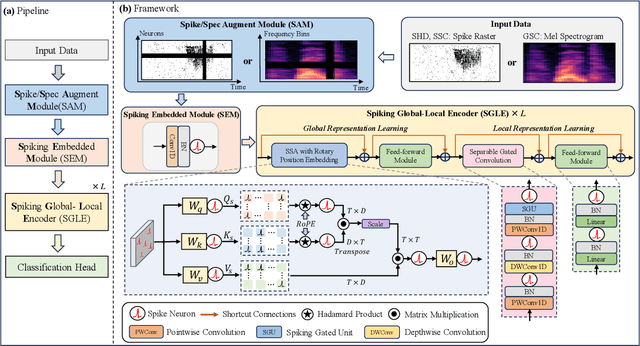
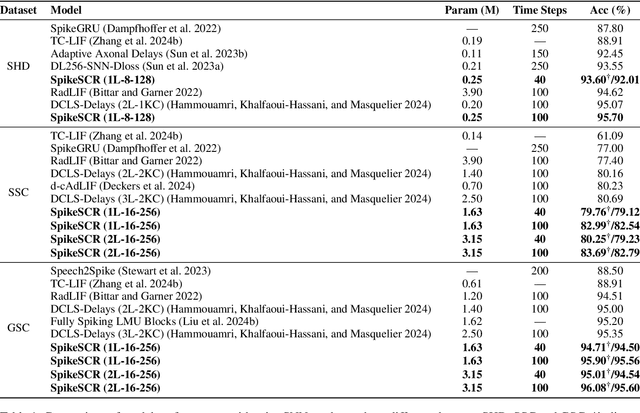
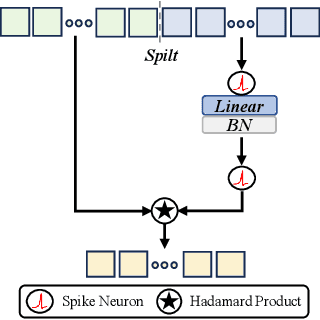

The intrinsic dynamics and event-driven nature of spiking neural networks (SNNs) make them excel in processing temporal information by naturally utilizing embedded time sequences as time steps. Recent studies adopting this approach have demonstrated SNNs' effectiveness in speech command recognition, achieving high performance by employing large time steps for long time sequences. However, the large time steps lead to increased deployment burdens for edge computing applications. Thus, it is important to balance high performance and low energy consumption when detecting temporal patterns in edge devices. Our solution comprises two key components. 1). We propose a high-performance fully spike-driven framework termed SpikeSCR, characterized by a global-local hybrid structure for efficient representation learning, which exhibits long-term learning capabilities with extended time steps. 2). To further fully embrace low energy consumption, we propose an effective knowledge distillation method based on curriculum learning (KDCL), where valuable representations learned from the easy curriculum are progressively transferred to the hard curriculum with minor loss, striking a trade-off between power efficiency and high performance. We evaluate our method on three benchmark datasets: the Spiking Heidelberg Dataset (SHD), the Spiking Speech Commands (SSC), and the Google Speech Commands (GSC) V2. Our experimental results demonstrate that SpikeSCR outperforms current state-of-the-art (SOTA) methods across these three datasets with the same time steps. Furthermore, by executing KDCL, we reduce the number of time steps by 60% and decrease energy consumption by 54.8% while maintaining comparable performance to recent SOTA results. Therefore, this work offers valuable insights for tackling temporal processing challenges with long time sequences in edge neuromorphic computing systems.
BrainECHO: Semantic Brain Signal Decoding through Vector-Quantized Spectrogram Reconstruction for Whisper-Enhanced Text Generation
Oct 19, 2024Recent advances in decoding language from brain signals (EEG and MEG) have been significantly driven by pre-trained language models, leading to remarkable progress on publicly available non-invasive EEG/MEG datasets. However, previous works predominantly utilize teacher forcing during text generation, leading to significant performance drops without its use. A fundamental issue is the inability to establish a unified feature space correlating textual data with the corresponding evoked brain signals. Although some recent studies attempt to mitigate this gap using an audio-text pre-trained model, Whisper, which is favored for its signal input modality, they still largely overlook the inherent differences between audio signals and brain signals in directly applying Whisper to decode brain signals. To address these limitations, we propose a new multi-stage strategy for semantic brain signal decoding via vEctor-quantized speCtrogram reconstruction for WHisper-enhanced text generatiOn, termed BrainECHO. Specifically, BrainECHO successively conducts: 1) Discrete autoencoding of the audio spectrogram; 2) Brain-audio latent space alignment; and 3) Semantic text generation via Whisper finetuning. Through this autoencoding--alignment--finetuning process, BrainECHO outperforms state-of-the-art methods under the same data split settings on two widely accepted resources: the EEG dataset (Brennan) and the MEG dataset (GWilliams). The innovation of BrainECHO, coupled with its robustness and superiority at the sentence, session, and subject-independent levels across public datasets, underscores its significance for language-based brain-computer interfaces.
Semantic-Guided Multimodal Sentiment Decoding with Adversarial Temporal-Invariant Learning
Sep 11, 2024



Multimodal sentiment analysis aims to learn representations from different modalities to identify human emotions. However, existing works often neglect the frame-level redundancy inherent in continuous time series, resulting in incomplete modality representations with noise. To address this issue, we propose temporal-invariant learning for the first time, which constrains the distributional variations over time steps to effectively capture long-term temporal dynamics, thus enhancing the quality of the representations and the robustness of the model. To fully exploit the rich semantic information in textual knowledge, we propose a semantic-guided fusion module. By evaluating the correlations between different modalities, this module facilitates cross-modal interactions gated by modality-invariant representations. Furthermore, we introduce a modality discriminator to disentangle modality-invariant and modality-specific subspaces. Experimental results on two public datasets demonstrate the superiority of our model. Our code is available at https://github.com/X-G-Y/SATI.
Robust Temporal-Invariant Learning in Multimodal Disentanglement
Aug 30, 2024Multimodal sentiment recognition aims to learn representations from different modalities to identify human emotions. However, previous works does not suppresses the frame-level redundancy inherent in continuous time series, resulting in incomplete modality representations with noise. To address this issue, we propose the Temporal-invariant learning, which minimizes the distributional differences between time steps to effectively capture smoother time series patterns, thereby enhancing the quality of the representations and robustness of the model. To fully exploit the rich semantic information in textual knowledge, we propose a Text-Driven Fusion Module (TDFM). To guide cross-modal interactions, TDFM evaluates the correlations between different modality through modality-invariant representations. Furthermore, we introduce a modality discriminator to disentangle modality-invariant and modality-specific subspaces. Experimental results on two public datasets demonstrate the superiority of our model.
EEG-MACS: Manifold Attention and Confidence Stratification for EEG-based Cross-Center Brain Disease Diagnosis under Unreliable Annotations
Apr 29, 2024



Cross-center data heterogeneity and annotation unreliability significantly challenge the intelligent diagnosis of diseases using brain signals. A notable example is the EEG-based diagnosis of neurodegenerative diseases, which features subtler abnormal neural dynamics typically observed in small-group settings. To advance this area, in this work, we introduce a transferable framework employing Manifold Attention and Confidence Stratification (MACS) to diagnose neurodegenerative disorders based on EEG signals sourced from four centers with unreliable annotations. The MACS framework's effectiveness stems from these features: 1) The Augmentor generates various EEG-represented brain variants to enrich the data space; 2) The Switcher enhances the feature space for trusted samples and reduces overfitting on incorrectly labeled samples; 3) The Encoder uses the Riemannian manifold and Euclidean metrics to capture spatiotemporal variations and dynamic synchronization in EEG; 4) The Projector, equipped with dual heads, monitors consistency across multiple brain variants and ensures diagnostic accuracy; 5) The Stratifier adaptively stratifies learned samples by confidence levels throughout the training process; 6) Forward and backpropagation in MACS are constrained by confidence stratification to stabilize the learning system amid unreliable annotations. Our subject-independent experiments, conducted on both neurocognitive and movement disorders using cross-center corpora, have demonstrated superior performance compared to existing related algorithms. This work not only improves EEG-based diagnostics for cross-center and small-setting brain diseases but also offers insights into extending MACS techniques to other data analyses, tackling data heterogeneity and annotation unreliability in multimedia and multimodal content understanding.