 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
GenTool: Enhancing Tool Generalization in Language Models through Zero-to-One and Weak-to-Strong Simulation
Feb 26, 2025Large Language Models (LLMs) can enhance their capabilities as AI assistants by integrating external tools, allowing them to access a wider range of information. While recent LLMs are typically fine-tuned with tool usage examples during supervised fine-tuning (SFT), questions remain about their ability to develop robust tool-usage skills and can effectively generalize to unseen queries and tools. In this work, we present GenTool, a novel training framework that prepares LLMs for diverse generalization challenges in tool utilization. Our approach addresses two fundamental dimensions critical for real-world applications: Zero-to-One Generalization, enabling the model to address queries initially lacking a suitable tool by adopting and utilizing one when it becomes available, and Weak-to-Strong Generalization, allowing models to leverage enhanced versions of existing tools to solve queries. To achieve this, we develop synthetic training data simulating these two dimensions of tool usage and introduce a two-stage fine-tuning approach: optimizing tool ranking, then refining tool selection. Through extensive experiments across four generalization scenarios, we demonstrate that our method significantly enhances the tool-usage capabilities of LLMs ranging from 1B to 8B parameters, achieving performance that surpasses GPT-4o. Furthermore, our analysis also provides valuable insights into the challenges LLMs encounter in tool generalization.
A High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024
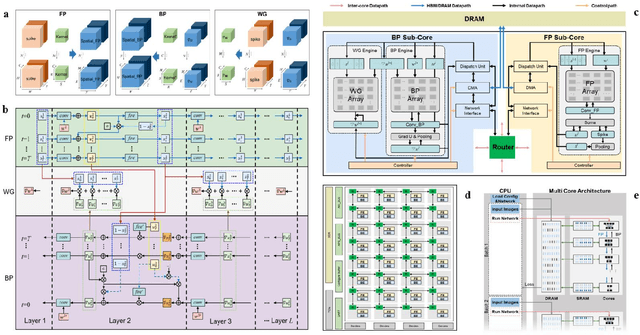
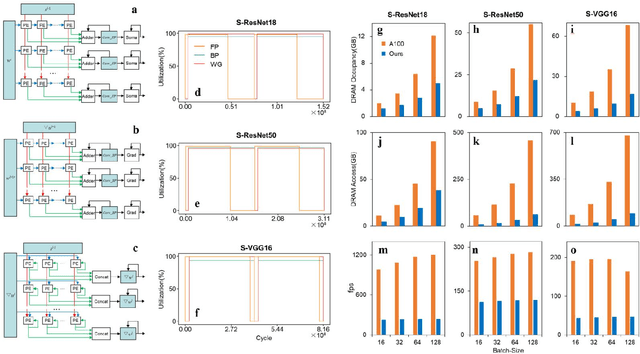
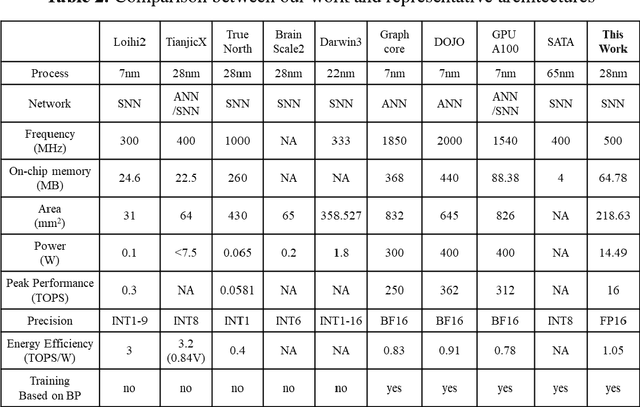
There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Interpretable User Satisfaction Estimation for Conversational Systems with Large Language Models
Mar 19, 2024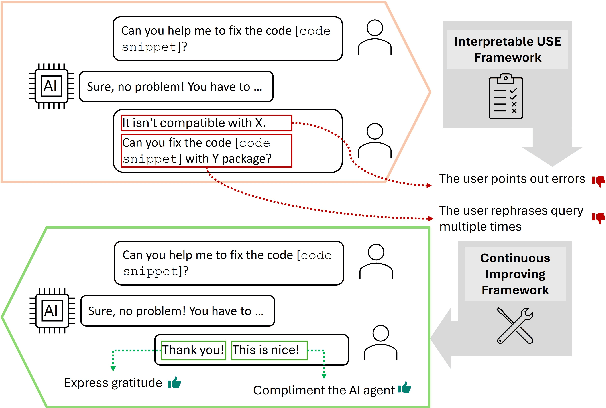
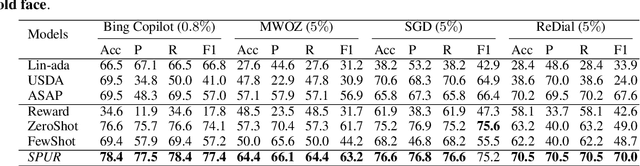
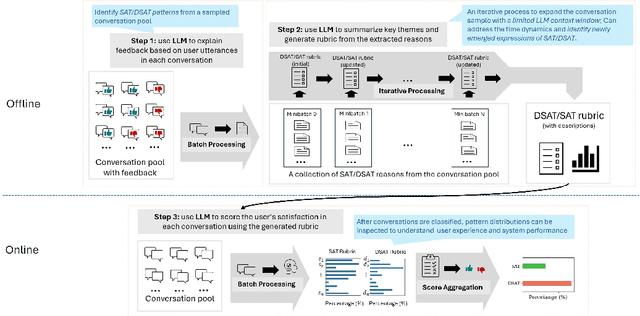
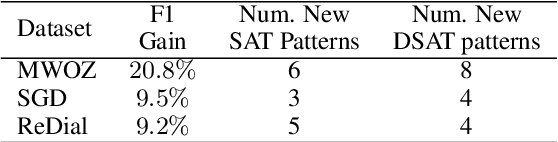
Accurate and interpretable user satisfaction estimation (USE) is critical for understanding, evaluating, and continuously improving conversational systems. Users express their satisfaction or dissatisfaction with diverse conversational patterns in both general-purpose (ChatGPT and Bing Copilot) and task-oriented (customer service chatbot) conversational systems. Existing approaches based on featurized ML models or text embeddings fall short in extracting generalizable patterns and are hard to interpret. In this work, we show that LLMs can extract interpretable signals of user satisfaction from their natural language utterances more effectively than embedding-based approaches. Moreover, an LLM can be tailored for USE via an iterative prompting framework using supervision from labeled examples. The resulting method, Supervised Prompting for User satisfaction Rubrics (SPUR), not only has higher accuracy but is more interpretable as it scores user satisfaction via learned rubrics with a detailed breakdown.
Improving Generalization via Attribute Selection on Out-of-the-box Data
Jul 26, 2019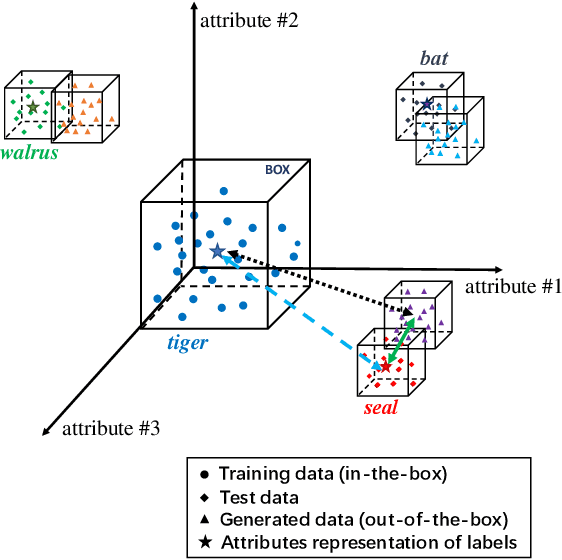
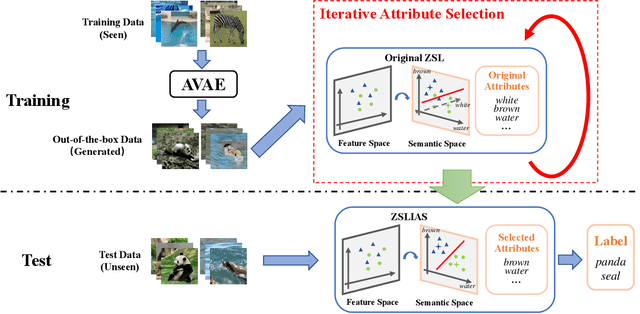
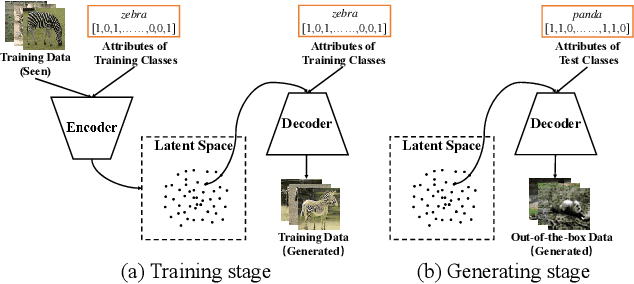

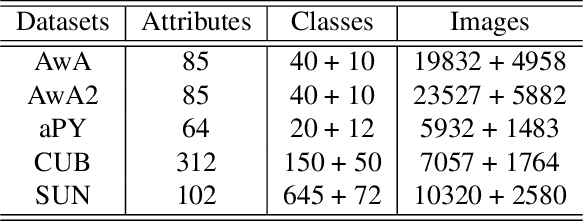
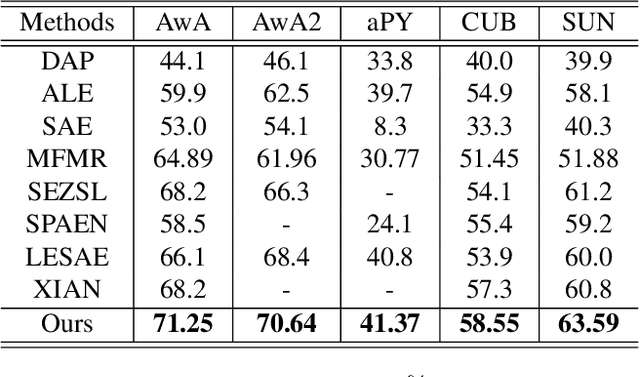
Zero-shot learning (ZSL) aims to recognize unseen objects (test classes) given some other seen objects (training classes), by sharing information of attributes between different objects. Attributes are artificially annotated for objects and are treated equally in recent ZSL tasks. However, some inferior attributes with poor predictability or poor discriminability may have negative impact on the ZSL system performance. This paper first derives a generalization error bound for ZSL tasks. Our theoretical analysis verifies that selecting key attributes set can improve the generalization performance of the original ZSL model which uses all the attributes. Unfortunately, previous attribute selection methods are conducted based on the seen data, their selected attributes have poor generalization capability to the unseen data, which is unavailable in training stage for ZSL tasks. Inspired by learning from pseudo relevance feedback, this paper introduces the out-of-the-box data, which is pseudo data generated by an attribute-guided generative model, to mimic the unseen data. After that, we present an iterative attribute selection (IAS) strategy which iteratively selects key attributes based on the out-of-the-box data. Since the distribution of the generated out-of-the-box data is similar to the test data, the key attributes selected by IAS can be effectively generalized to test data. Extensive experiments demonstrate that IAS can significantly improve existing attribute-based ZSL methods and achieve state-of-the-art performance.
Learning Image-Specific Attributes by Hyperbolic Neighborhood Graph Propagation
May 25, 2019

As a kind of semantic representation of visual object descriptions, attributes are widely used in various computer vision tasks. In most of existing attribute-based research, class-specific attributes (CSA), which are class-level annotations, are usually adopted due to its low annotation cost for each class instead of each individual image. However, class-specific attributes are usually noisy because of annotation errors and diversity of individual images. Therefore, it is desirable to obtain image-specific attributes (ISA), which are image-level annotations, from the original class-specific attributes. In this paper, we propose to learn image-specific attributes by graph-based attribute propagation. Considering the intrinsic property of hyperbolic geometry that its distance expands exponentially, hyperbolic neighborhood graph (HNG) is constructed to characterize the relationship between samples. Based on HNG, we define neighborhood consistency for each sample to identify inconsistent samples. Subsequently, inconsistent samples are refined based on their neighbors in HNG. Extensive experiments on five benchmark datasets demonstrate the significant superiority of the learned image-specific attributes over the original class-specific attributes in the zero-shot object classification task.
Target-Independent Active Learning via Distribution-Splitting
Sep 28, 2018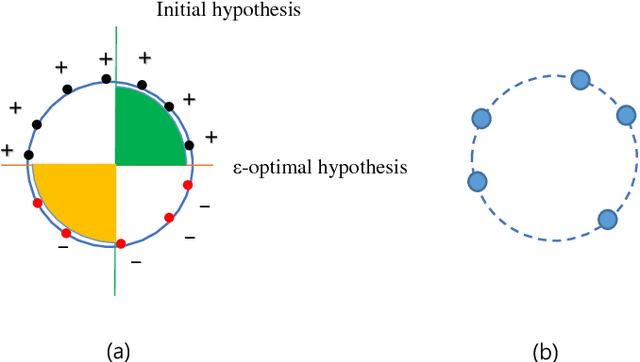
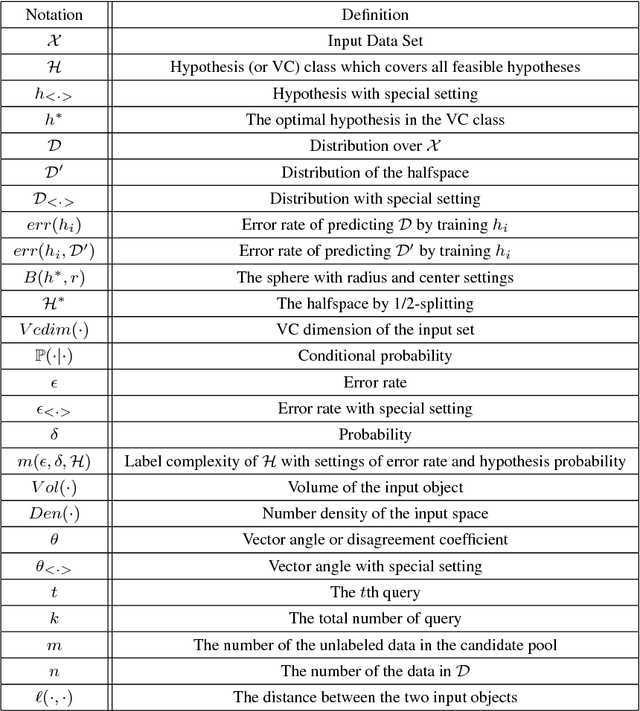
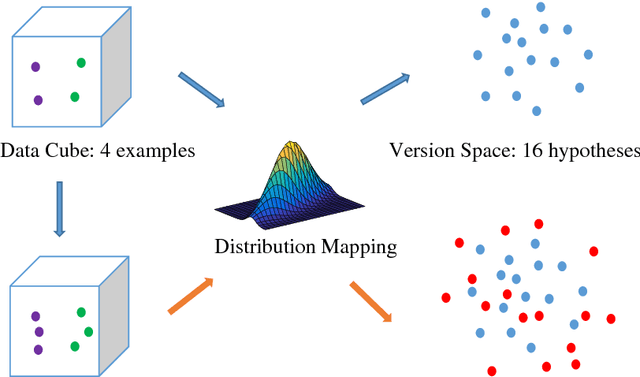
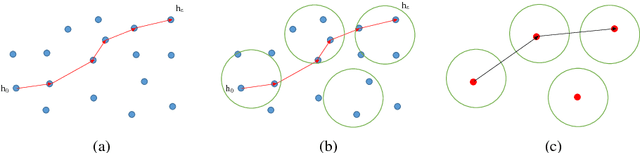
To reduce the label complexity in Agnostic Active Learning (A^2 algorithm), volume-splitting splits the hypothesis edges to reduce the Vapnik-Chervonenkis (VC) dimension in version space. However, the effectiveness of volume-splitting critically depends on the initial hypothesis and this problem is also known as target-dependent label complexity gap. This paper attempts to minimize this gap by introducing a novel notion of number density which provides a more natural and direct way to describe the hypothesis distribution than volume. By discovering the connections between hypothesis and input distribution, we map the volume of version space into the number density and propose a target-independent distribution-splitting strategy with the following advantages: 1) provide theoretical guarantees on reducing label complexity and error rate as volume-splitting; 2) break the curse of initial hypothesis; 3) provide model guidance for a target-independent AL algorithm in real AL tasks. With these guarantees, for AL application, we then split the input distribution into more near-optimal spheres and develop an application algorithm called Distribution-based A^2 (DA^2). Experiments further verify the effectiveness of the halving and querying abilities of DA^2. Contributions of this paper are as follows.
Zero-shot Learning with Complementary Attributes
Apr 17, 2018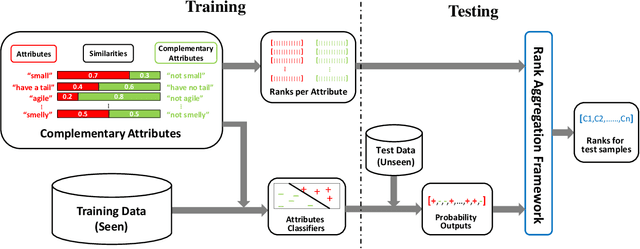


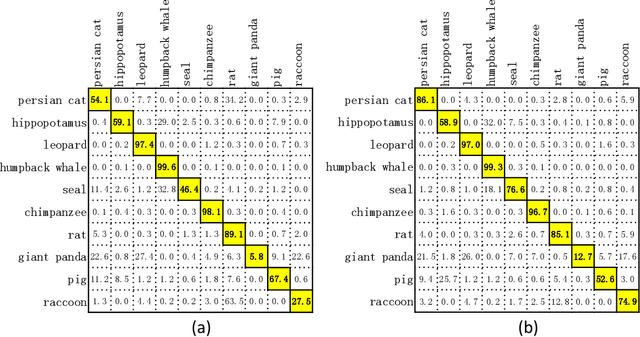
Zero-shot learning (ZSL) aims to recognize unseen objects using disjoint seen objects via attributes to transfer semantic information from training data to testing data. The generalization performance of ZSL is governed by the attributes, which represent the relatedness between the seen classes and the unseen classes. In this paper, we propose a novel ZSL method using complementary attributes as a supplement to the original attributes. We first expand attributes with their complementary form, and then pre-train classifiers for both original attributes and complementary attributes using training data. After ranking classes for each attribute, we use rank aggregation framework to calculate the optimized rank among testing classes of which the highest order is assigned as the label of testing sample. We empirically demonstrate that complementary attributes have an effective improvement for ZSL models. Experimental results show that our approach outperforms state-of-the-art methods on standard ZSL datasets.