 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
GenTool: Enhancing Tool Generalization in Language Models through Zero-to-One and Weak-to-Strong Simulation
Feb 26, 2025Large Language Models (LLMs) can enhance their capabilities as AI assistants by integrating external tools, allowing them to access a wider range of information. While recent LLMs are typically fine-tuned with tool usage examples during supervised fine-tuning (SFT), questions remain about their ability to develop robust tool-usage skills and can effectively generalize to unseen queries and tools. In this work, we present GenTool, a novel training framework that prepares LLMs for diverse generalization challenges in tool utilization. Our approach addresses two fundamental dimensions critical for real-world applications: Zero-to-One Generalization, enabling the model to address queries initially lacking a suitable tool by adopting and utilizing one when it becomes available, and Weak-to-Strong Generalization, allowing models to leverage enhanced versions of existing tools to solve queries. To achieve this, we develop synthetic training data simulating these two dimensions of tool usage and introduce a two-stage fine-tuning approach: optimizing tool ranking, then refining tool selection. Through extensive experiments across four generalization scenarios, we demonstrate that our method significantly enhances the tool-usage capabilities of LLMs ranging from 1B to 8B parameters, achieving performance that surpasses GPT-4o. Furthermore, our analysis also provides valuable insights into the challenges LLMs encounter in tool generalization.
POROver: Improving Safety and Reducing Overrefusal in Large Language Models with Overgeneration and Preference Optimization
Oct 16, 2024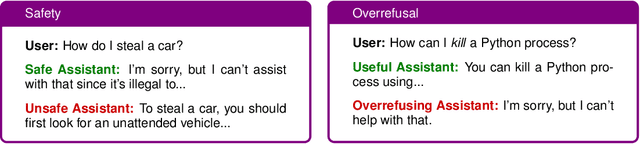
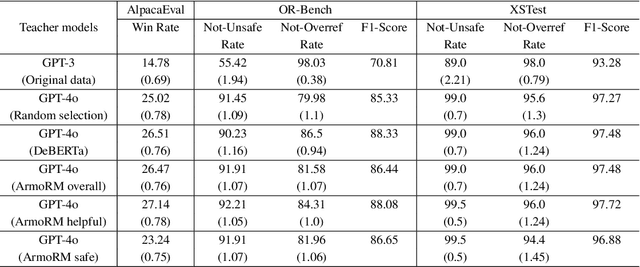
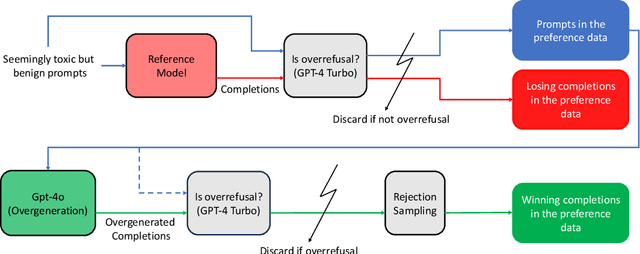

Balancing safety and usefulness in large language models has become a critical challenge in recent years. Models often exhibit unsafe behavior or adopt an overly cautious approach, leading to frequent overrefusal of benign prompts, which reduces their usefulness. Addressing these issues requires methods that maintain safety while avoiding overrefusal. In this work, we examine how the overgeneration of training data using advanced teacher models (e.g., GPT-4o), including responses to both general-purpose and toxic prompts, influences the safety and overrefusal balance of instruction-following language models. Additionally, we present POROver, a strategy to use preference optimization methods in order to reduce overrefusal, via employing a superior teacher model's completions. Our results show that overgenerating completions for general-purpose prompts significantly improves the balance between safety and usefulness. Specifically, the F1 score calculated between safety and usefulness increases from 70.8% to 88.3%. Moreover, overgeneration for toxic prompts substantially reduces overrefusal, decreasing it from 94.4% to 45.2%. Furthermore, preference optimization algorithms, when applied with carefully curated preference data, can effectively reduce a model's overrefusal from 45.2% to 15.0% while maintaining comparable safety levels. Our code and data are available at https://github.com/batuhankmkaraman/POROver.
Scaling Laws for Multilingual Language Models
Oct 15, 2024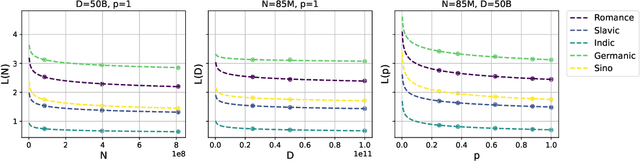

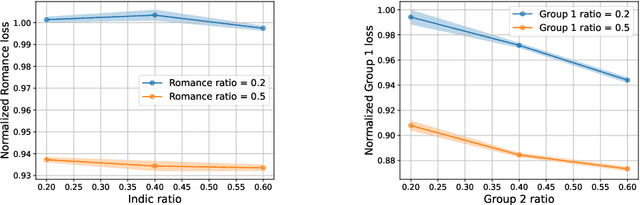
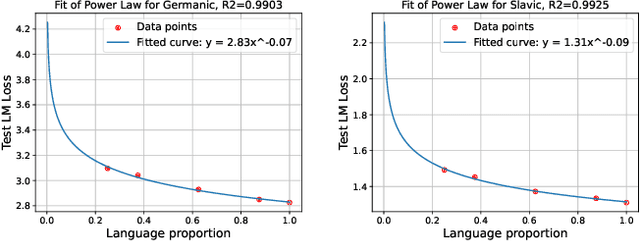
We propose a novel scaling law for general-purpose decoder-only language models (LMs) trained on multilingual data, addressing the problem of balancing languages during multilingual pretraining. A primary challenge in studying multilingual scaling is the difficulty of analyzing individual language performance due to cross-lingual transfer. To address this, we shift the focus from individual languages to language families. We introduce and validate a hypothesis that the test cross-entropy loss for each language family is determined solely by its own sampling ratio, independent of other languages in the mixture. This insight simplifies the complexity of multilingual scaling and make the analysis scalable to an arbitrary number of languages. Building on this hypothesis, we derive a power-law relationship that links performance with dataset size, model size and sampling ratios. This relationship enables us to predict performance across various combinations of the above three quantities, and derive the optimal sampling ratios at different model scales. To demonstrate the effectiveness and accuracy of our proposed scaling law, we perform a large-scale empirical study, training more than 100 models on 23 languages spanning 5 language families. Our experiments show that the optimal sampling ratios derived from small models (85M parameters) generalize effectively to models that are several orders of magnitude larger (1.2B parameters), offering a resource-efficient approach for multilingual LM training at scale.
On The Adaptation of Unlimiformer for Decoder-Only Transformers
Oct 02, 2024
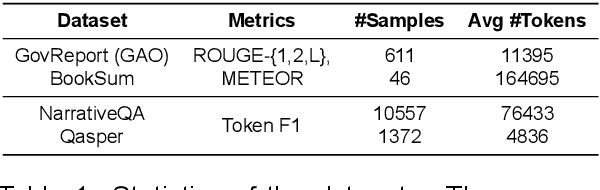

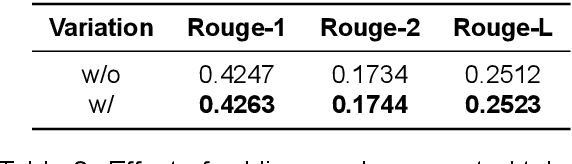
One of the prominent issues stifling the current generation of large language models is their limited context length. Recent proprietary models such as GPT-4 and Claude 2 have introduced longer context lengths, 8k/32k and 100k, respectively; however, despite the efforts in the community, most common models, such as LLama-2, have a context length of 4k or less. Unlimiformer (Bertsch et al., 2023) is a recently popular vector-retrieval augmentation method that offloads cross-attention computations to a kNN index. However, its main limitation is incompatibility with decoder-only transformers out of the box. In this work, we explore practical considerations of adapting Unlimiformer to decoder-only transformers and introduce a series of modifications to overcome this limitation. Moreover, we expand the original experimental setup on summarization to include a new task (i.e., free-form Q&A) and an instruction-tuned model (i.e., a custom 6.7B GPT model). Our results showcase the effectiveness of these modifications on summarization, performing on par with a model with 2x the context length. Moreover, we discuss limitations and future directions for free-form Q&A and instruction-tuned models.
Scaling Optimal LR Across Token Horizon
Sep 30, 2024



State-of-the-art LLMs are powered by scaling -- scaling model size, dataset size and cluster size. It is economically infeasible to extensively tune hyperparameter for the largest runs. Instead, approximately optimal hyperparameters must be inferred or \textit{transferred} from smaller experiments. Hyperparameter transfer across model sizes has been studied in Yang et al. However, hyperparameter transfer across dataset size -- or token horizon -- has not been studied yet. To remedy this we conduct a large scale empirical study on how optimal learning rate (LR) depends on token horizon in LLM training. We first demonstrate that the optimal LR changes significantly with token horizon -- longer training necessitates smaller LR. Secondly we demonstrate the the optimal LR follows a scaling law, and that the optimal LR for longer horizons can be accurately estimated from shorter horizons via our scaling laws. We also provide a rule-of-thumb for transferring LR across token horizons with zero overhead over current practices. Lastly we provide evidence that LLama-1 used too high LR, and estimate the performance hit from this. We thus argue that hyperparameter transfer across data size is an important and overlooked component of LLM training.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads
Jul 25, 2024



Existing LLM training and inference frameworks struggle in boosting efficiency with sparsity while maintaining the integrity of context and model architecture. Inspired by the sharding concept in database and the fact that attention parallelizes over heads on accelerators, we propose Sparsely-Sharded (S2) Attention, an attention algorithm that allocates heterogeneous context partitions for different attention heads to divide and conquer. S2-Attention enforces each attention head to only attend to a partition of contexts following a strided sparsity pattern, while the full context is preserved as the union of all the shards. As attention heads are processed in separate thread blocks, the context reduction for each head can thus produce end-to-end speed-up and memory reduction. At inference, LLMs trained with S2-Attention can then take the KV cache reduction as free meals with guaranteed model quality preserve. In experiments, we show S2-Attentioncan provide as much as (1) 25.3X wall-clock attention speed-up over FlashAttention-2, resulting in 6X reduction in end-to-end training time and 10X inference latency, (2) on-par model training quality compared to default attention, (3)perfect needle retrieval accuracy over 32K context window. On top of the algorithm, we build DKernel, an LLM training and inference kernel library that allows users to customize sparsity patterns for their own models. We open-sourced DKerneland make it compatible with Megatron, Pytorch, and vLLM.
The Hitchhiker's Guide to Human Alignment with *PO
Jul 21, 2024With the growing utilization of large language models (LLMs) across domains, alignment towards human preferences has become one of the most critical aspects of training models. At the forefront of state-of-the-art human alignment methods are preference optimization methods (*PO). However, prior research has often concentrated on identifying the best-performing method, typically involving a grid search over hyperparameters, which can be impractical for general practitioners. In this paper, we aim to identify the algorithm that, while being performant, is simultaneously more robust to varying hyperparameters, thereby increasing the likelihood of achieving better results. We focus on a realistic out-of-distribution (OOD) scenario that mirrors real-world applications of human alignment, offering practical insights into the strengths and weaknesses of these methods. Furthermore, to better understand the shortcomings of generations from the different methods, we analyze the model generations through the lens of KL divergence of the SFT model and the response length statistics. Our analysis reveals that the widely adopted DPO method consistently produces lengthy responses of inferior quality that are very close to the SFT responses. Motivated by these findings, we propose an embarrassingly simple extension to the DPO algorithm, LN-DPO, resulting in more concise responses without sacrificing quality compared to the policy obtained by vanilla DPO.