 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Transformers: SwiftKey's Differential Privacy Implementation
May 08, 2025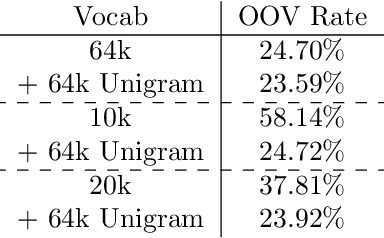
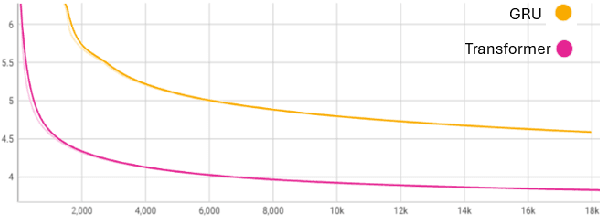
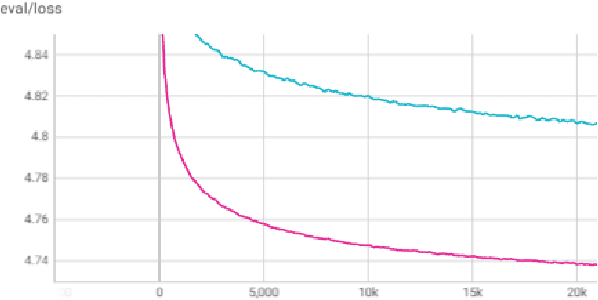
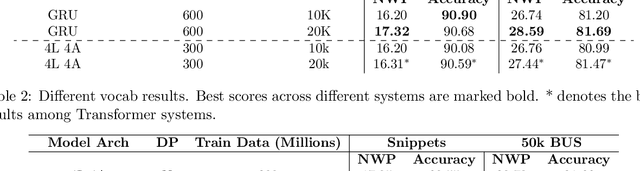
In this paper we train a transformer using differential privacy (DP) for language modeling in SwiftKey. We run multiple experiments to balance the trade-off between the model size, run-time speed and accuracy. We show that we get small and consistent gains in the next-word-prediction and accuracy with graceful increase in memory and speed compared to the production GRU. This is obtained by scaling down a GPT2 architecture to fit the required size and a two stage training process that builds a seed model on general data and DP finetunes it on typing data. The transformer is integrated using ONNX offering both flexibility and efficiency.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Simply Trainable Nearest Neighbour Machine Translation with GPU Inference
Jul 29, 2024Nearest neighbor machine translation is a successful approach for fast domain adaption, which interpolates the pre-trained transformers with domain-specific token-level k-nearest-neighbor (kNN) retrieval without retraining. Despite kNN MT's success, searching large reference corpus and fixed interpolation between the kNN and pre-trained model led to computational complexity and translation quality challenges. Among other papers, Dai et al. proposed methods to obtain a small number of reference samples dynamically for which they introduced a distance-aware interpolation method using an equation that includes free parameters. This paper proposes a simply trainable nearest neighbor machine translation and carry out inference experiments on GPU. Similar to Dai et al., we first adaptively construct a small datastore for each input sentence. Second, we train a single-layer network for the interpolation coefficient between the knnMT and pre-trained result to automatically interpolate in different domains. Experimental results on different domains show that our proposed method either improves or sometimes maintain the translation quality of methods in Dai et al. while being automatic. In addition, our GPU inference results demonstrate that knnMT can be integrated into GPUs with a drop of only 5% in terms of speed.