 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Metrics also Disagree in the Low Scoring Range: Revisiting Summarization Evaluation Metrics
Nov 08, 2020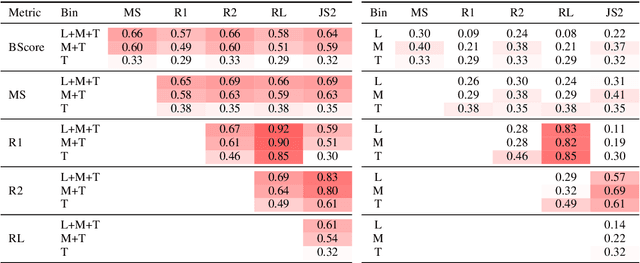


In text summarization, evaluating the efficacy of automatic metrics without human judgments has become recently popular. One exemplar work concludes that automatic metrics strongly disagree when ranking high-scoring summaries. In this paper, we revisit their experiments and find that their observations stem from the fact that metrics disagree in ranking summaries from any narrow scoring range. We hypothesize that this may be because summaries are similar to each other in a narrow scoring range and are thus, difficult to rank. Apart from the width of the scoring range of summaries, we analyze three other properties that impact inter-metric agreement - Ease of Summarization, Abstractiveness, and Coverage. To encourage reproducible research, we make all our analysis code and data publicly available.
Re-evaluating Evaluation in Text Summarization
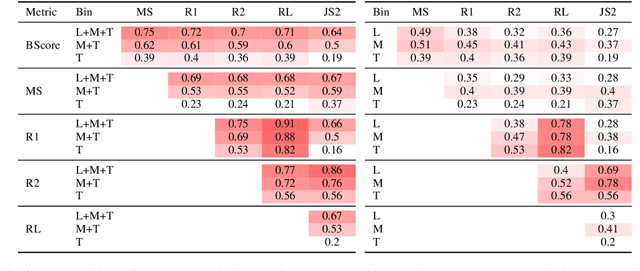
Oct 14, 2020


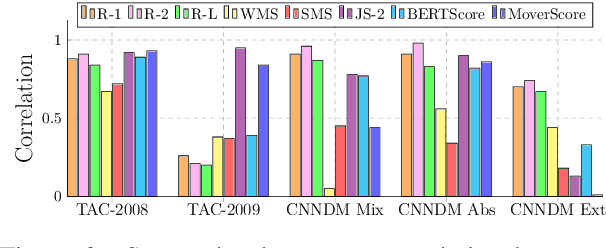
Automated evaluation metrics as a stand-in for manual evaluation are an essential part of the development of text-generation tasks such as text summarization. However, while the field has progressed, our standard metrics have not -- for nearly 20 years ROUGE has been the standard evaluation in most summarization papers. In this paper, we make an attempt to re-evaluate the evaluation method for text summarization: assessing the reliability of automatic metrics using top-scoring system outputs, both abstractive and extractive, on recently popular datasets for both system-level and summary-level evaluation settings. We find that conclusions about evaluation metrics on older datasets do not necessarily hold on modern datasets and systems.