 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSibylSense: Adaptive Rubric Learning via Memory Tuning and Adversarial Probing
Feb 24, 2026Designing aligned and robust rewards for open-ended generation remains a key barrier to RL post-training. Rubrics provide structured, interpretable supervision, but scaling rubric construction is difficult: expert rubrics are costly, prompted rubrics are often superficial or inconsistent, and fixed-pool discriminative rubrics can saturate and drift, enabling reward hacking. We present SibylSense, an inference-time learning approach that adapts a frozen rubric generator through a tunable memory bank of validated rubric items. Memory is updated via verifier-based item rewards measured by reference-candidate answer discriminative gaps from a handful of examples. SibylSense alternates memory tuning with a rubric-adversarial policy update that produces rubric-satisfying candidate answers, shrinking discriminative gaps and driving the rubric generator to capture new quality dimensions. Experiments on two open-ended tasks show that SibylSense yields more discriminative rubrics and improves downstream RL performance over static and non-adaptive baselines.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025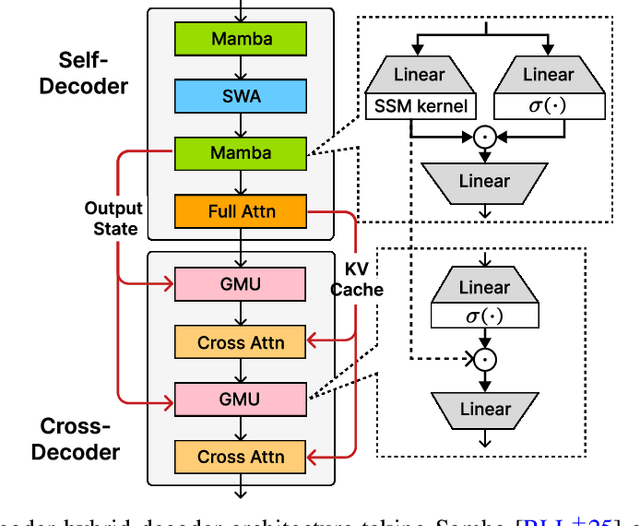
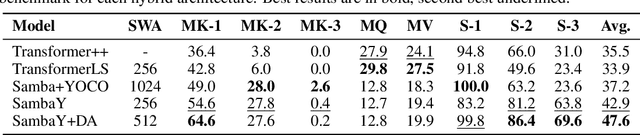
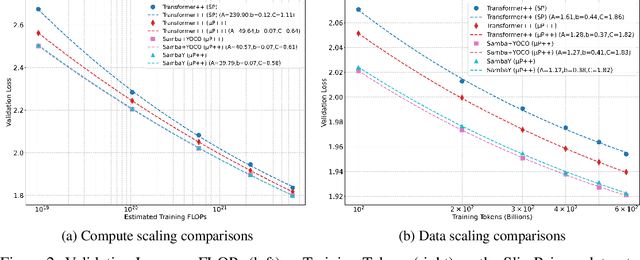
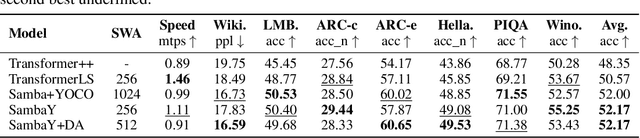
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Hybrid Generative-Retrieval Transformers for Dialogue Domain Adaptation
Mar 06, 2020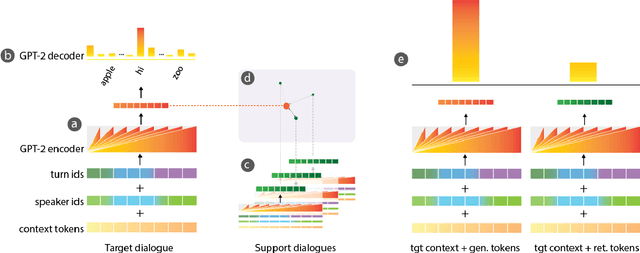

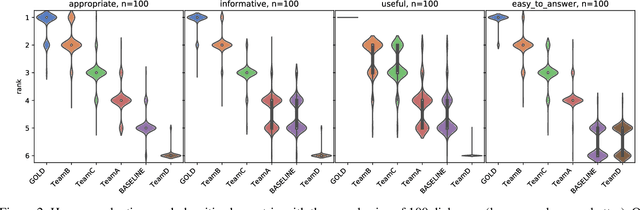
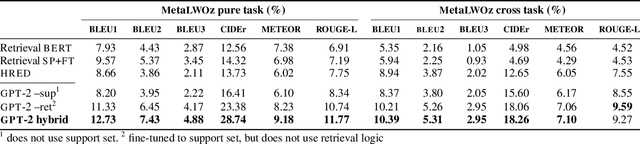
Domain adaptation has recently become a key problem in dialogue systems research. Deep learning, while being the preferred technique for modeling such systems, works best given massive training data. However, in the real-world scenario, such resources aren't available for every new domain, so the ability to train with a few dialogue examples can be considered essential. Pre-training on large data sources and adapting to the target data has become the standard method for few-shot problems within the deep learning framework. In this paper, we present the winning entry at the fast domain adaptation task of DSTC8, a hybrid generative-retrieval model based on GPT-2 fine-tuned to the multi-domain MetaLWOz dataset. Robust and diverse in response generation, our model uses retrieval logic as a fallback, being SoTA on MetaLWOz in human evaluation (>4% improvement over the 2nd place system) and attaining competitive generalization performance in adaptation to the unseen MultiWOZ dataset.
The Eighth Dialog System Technology Challenge
Nov 14, 2019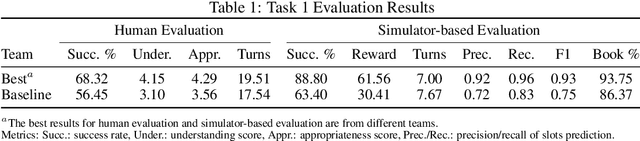
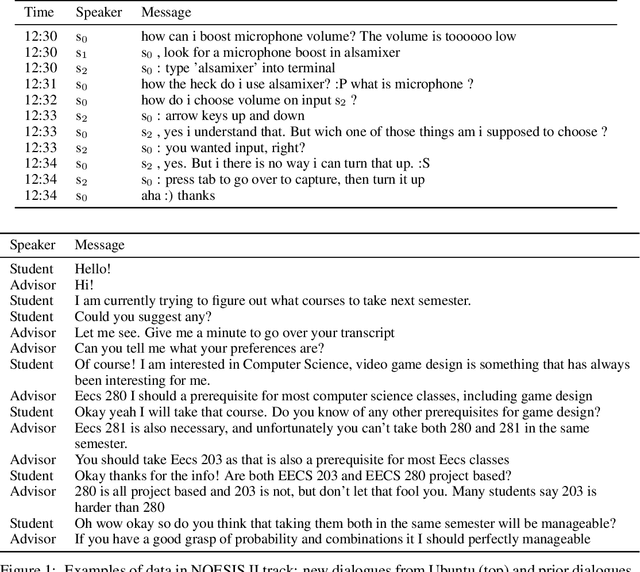
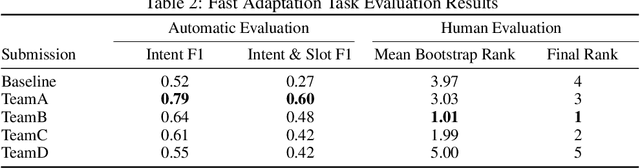
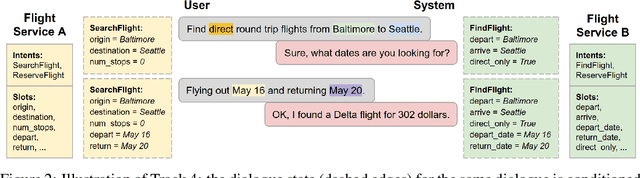
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Feb 22, 2018


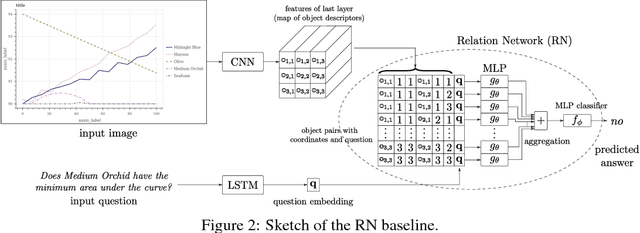
We introduce FigureQA, a visual reasoning corpus of over one million question-answer pairs grounded in over 100,000 images. The images are synthetic, scientific-style figures from five classes: line plots, dot-line plots, vertical and horizontal bar graphs, and pie charts. We formulate our reasoning task by generating questions from 15 templates; questions concern various relationships between plot elements and examine characteristics like the maximum, the minimum, area-under-the-curve, smoothness, and intersection. To resolve, such questions often require reference to multiple plot elements and synthesis of information distributed spatially throughout a figure. To facilitate the training of machine learning systems, the corpus also includes side data that can be used to formulate auxiliary objectives. In particular, we provide the numerical data used to generate each figure as well as bounding-box annotations for all plot elements. We study the proposed visual reasoning task by training several models, including the recently proposed Relation Network as a strong baseline. Preliminary results indicate that the task poses a significant machine learning challenge. We envision FigureQA as a first step towards developing models that can intuitively recognize patterns from visual representations of data.