 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Conversational Theme Detection Track at DSTC 12
Aug 26, 2025Conversational analytics has been on the forefront of transformation driven by the advances in Speech and Natural Language Processing techniques. Rapid adoption of Large Language Models (LLMs) in the analytics field has taken the problems that can be automated to a new level of complexity and scale. In this paper, we introduce Theme Detection as a critical task in conversational analytics, aimed at automatically identifying and categorizing topics within conversations. This process can significantly reduce the manual effort involved in analyzing expansive dialogs, particularly in domains like customer support or sales. Unlike traditional dialog intent detection, which often relies on a fixed set of intents for downstream system logic, themes are intended as a direct, user-facing summary of the conversation's core inquiry. This distinction allows for greater flexibility in theme surface forms and user-specific customizations. We pose Controllable Conversational Theme Detection problem as a public competition track at Dialog System Technology Challenge (DSTC) 12 -- it is framed as joint clustering and theme labeling of dialog utterances, with the distinctive aspect being controllability of the resulting theme clusters' granularity achieved via the provided user preference data. We give an overview of the problem, the associated dataset and the evaluation metrics, both automatic and human. Finally, we discuss the participant teams' submissions and provide insights from those. The track materials (data and code) are openly available in the GitHub repository.
Faithful, Unfaithful or Ambiguous? Multi-Agent Debate with Initial Stance for Summary Evaluation
Feb 12, 2025Faithfulness evaluators based on large language models (LLMs) are often fooled by the fluency of the text and struggle with identifying errors in the summaries. We propose an approach to summary faithfulness evaluation in which multiple LLM-based agents are assigned initial stances (regardless of what their belief might be) and forced to come up with a reason to justify the imposed belief, thus engaging in a multi-round debate to reach an agreement. The uniformly distributed initial assignments result in a greater diversity of stances leading to more meaningful debates and ultimately more errors identified. Furthermore, by analyzing the recent faithfulness evaluation datasets, we observe that naturally, it is not always the case for a summary to be either faithful to the source document or not. We therefore introduce a new dimension, ambiguity, and a detailed taxonomy to identify such special cases. Experiments demonstrate our approach can help identify ambiguities, and have even a stronger performance on non-ambiguous summaries.
Controllable Contextualized Image Captioning: Directing the Visual Narrative through User-Defined Highlights
Jul 16, 2024Contextualized Image Captioning (CIC) evolves traditional image captioning into a more complex domain, necessitating the ability for multimodal reasoning. It aims to generate image captions given specific contextual information. This paper further introduces a novel domain of Controllable Contextualized Image Captioning (Ctrl-CIC). Unlike CIC, which solely relies on broad context, Ctrl-CIC accentuates a user-defined highlight, compelling the model to tailor captions that resonate with the highlighted aspects of the context. We present two approaches, Prompting-based Controller (P-Ctrl) and Recalibration-based Controller (R-Ctrl), to generate focused captions. P-Ctrl conditions the model generation on highlight by prepending captions with highlight-driven prefixes, whereas R-Ctrl tunes the model to selectively recalibrate the encoder embeddings for highlighted tokens. Additionally, we design a GPT-4V empowered evaluator to assess the quality of the controlled captions alongside standard assessment methods. Extensive experimental results demonstrate the efficient and effective controllability of our method, charting a new direction in achieving user-adaptive image captioning. Code is available at https://github.com/ShunqiM/Ctrl-CIC .
Fine-grained, Multi-dimensional Summarization Evaluation with LLMs
Jul 09, 2024



Automated evaluation is crucial for streamlining text summarization benchmarking and model development, given the costly and time-consuming nature of human evaluation. Traditional methods like ROUGE do not correlate well with human judgment, while recently proposed LLM-based metrics provide only summary-level assessment using Likert-scale scores. This limits deeper model analysis, e.g., we can only assign one hallucination score at the summary level, while at the sentence level, we can count sentences containing hallucinations. To remedy those limitations, we propose FineSurE, a fine-grained evaluator specifically tailored for the summarization task using large language models (LLMs). It also employs completeness and conciseness criteria, in addition to faithfulness, enabling multi-dimensional assessment. We compare various open-source and proprietary LLMs as backbones for FineSurE. In addition, we conduct extensive benchmarking of FineSurE against SOTA methods including NLI-, QA-, and LLM-based methods, showing improved performance especially on the completeness and conciseness dimensions. The code is available at https://github.com/DISL-Lab/FineSurE-ACL24.
FineSurE: Fine-grained Summarization Evaluation using LLMs
Jul 01, 2024Automated evaluation is crucial for streamlining text summarization benchmarking and model development, given the costly and time-consuming nature of human evaluation. Traditional methods like ROUGE do not correlate well with human judgment, while recently proposed LLM-based metrics provide only summary-level assessment using Likert-scale scores. This limits deeper model analysis, e.g., we can only assign one hallucination score at the summary level, while at the sentence level, we can count sentences containing hallucinations. To remedy those limitations, we propose FineSurE, a fine-grained evaluator specifically tailored for the summarization task using large language models (LLMs). It also employs completeness and conciseness criteria, in addition to faithfulness, enabling multi-dimensional assessment. We compare various open-source and proprietary LLMs as backbones for FineSurE. In addition, we conduct extensive benchmarking of FineSurE against SOTA methods including NLI-, QA-, and LLM-based methods, showing improved performance especially on the completeness and conciseness dimensions. The code is available at https://github.com/DISL-Lab/FineSurE-ACL24.
CERET: Cost-Effective Extrinsic Refinement for Text Generation
Jun 08, 2024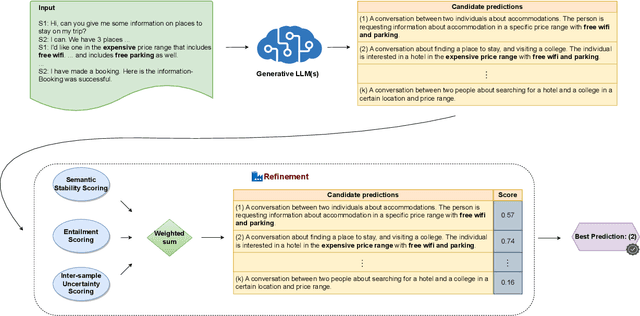

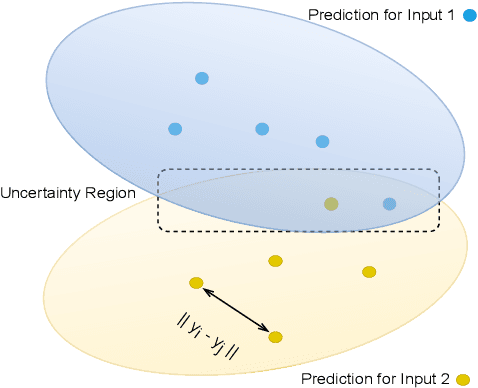
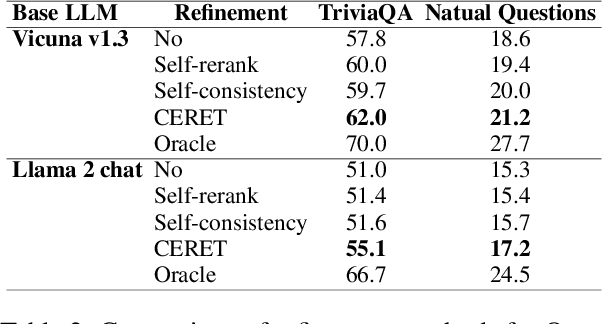
Large Language Models (LLMs) are powerful models for generation tasks, but they may not generate good quality outputs in their first attempt. Apart from model fine-tuning, existing approaches to improve prediction accuracy and quality typically involve LLM self-improvement / self-reflection that incorporate feedback from models themselves. Despite their effectiveness, these methods are hindered by their high computational cost and lack of scalability. In this work, we propose CERET, a method for refining text generations by considering semantic stability, entailment and inter-sample uncertainty measures. Experimental results show that CERET outperforms Self-consistency and Self-rerank baselines consistently under various task setups, by ~1.6% in Rouge-1 for abstractive summarization and ~3.5% in hit rate for question answering. Compared to LLM Self-rerank method, our approach only requires 9.4% of its latency and is more cost-effective.
Can Your Model Tell a Negation from an Implicature? Unravelling Challenges With Intent Encoders
Mar 07, 2024



Conversational systems often rely on embedding models for intent classification and intent clustering tasks. The advent of Large Language Models (LLMs), which enable instructional embeddings allowing one to adjust semantics over the embedding space using prompts, are being viewed as a panacea for these downstream conversational tasks. However, traditional evaluation benchmarks rely solely on task metrics that don't particularly measure gaps related to semantic understanding. Thus, we propose an intent semantic toolkit that gives a more holistic view of intent embedding models by considering three tasks -- (1) intent classification, (2) intent clustering, and (3) a novel triplet task. The triplet task gauges the model's understanding of two semantic concepts paramount in real-world conversational systems -- negation and implicature. We observe that current embedding models fare poorly in semantic understanding of these concepts. To address this, we propose a pre-training approach to improve the embedding model by leveraging augmentation with data generated by an auto-regressive model and a contrastive loss term. Our approach improves the semantic understanding of the intent embedding model on the aforementioned linguistic dimensions while slightly effecting their performance on downstream task metrics.
Semi-Supervised Dialogue Abstractive Summarization via High-Quality Pseudolabel Selection
Mar 06, 2024



Semi-supervised dialogue summarization (SSDS) leverages model-generated summaries to reduce reliance on human-labeled data and improve the performance of summarization models. While addressing label noise, previous works on semi-supervised learning primarily focus on natural language understanding tasks, assuming each sample has a unique label. However, these methods are not directly applicable to SSDS, as it is a generative task, and each dialogue can be summarized in different ways. In this work, we propose a novel scoring approach, SiCF, which encapsulates three primary dimensions of summarization model quality: Semantic invariance (indicative of model confidence), Coverage (factual recall), and Faithfulness (factual precision). Using the SiCF score, we select unlabeled dialogues with high-quality generated summaries to train summarization models. Comprehensive experiments on three public datasets demonstrate the effectiveness of SiCF scores in uncertainty estimation and semi-supervised learning for dialogue summarization tasks. Our code is available at \url{https://github.com/amazon-science/summarization-sicf-score}.
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024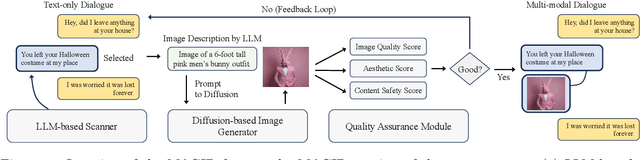



Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
Feb 20, 2024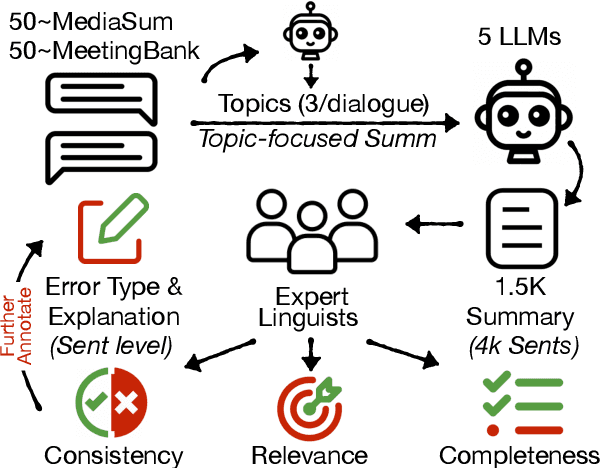


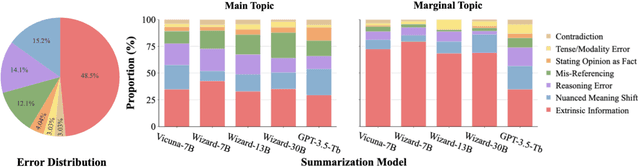
Single document news summarization has seen substantial progress on faithfulness in recent years, driven by research on the evaluation of factual consistency, or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human annotations of the factual consistency of these summaries along with detailed explanations of factually inconsistent sentences. Our analysis shows that existing LLMs hallucinate significant amounts of factual errors in the dialogue domain, regardless of the model's size. On the other hand, when LLMs, including GPT-4, serve as binary factual evaluators, they perform poorly and can be outperformed by prevailing state-of-the-art specialized factuality evaluation metrics. Finally, we conducted an analysis of hallucination types with a curated error taxonomy. We find that there are diverse errors and error distributions in model-generated summaries and that non-LLM based metrics can capture all error types better than LLM-based evaluators.