 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCERET: Cost-Effective Extrinsic Refinement for Text Generation
Paper and Code
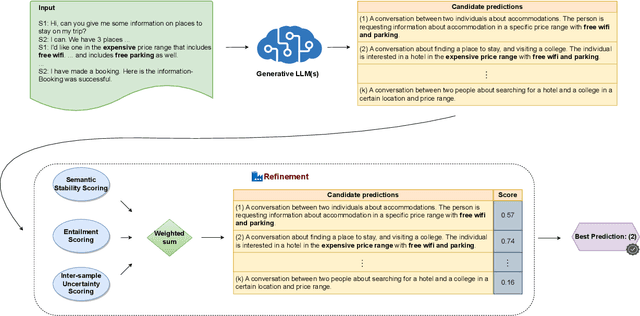

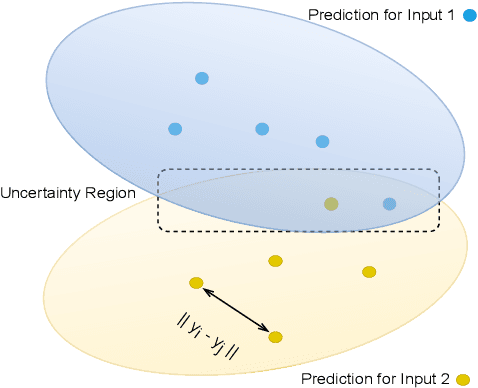
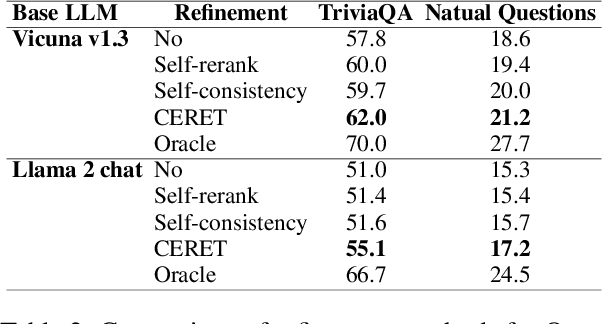
Large Language Models (LLMs) are powerful models for generation tasks, but they may not generate good quality outputs in their first attempt. Apart from model fine-tuning, existing approaches to improve prediction accuracy and quality typically involve LLM self-improvement / self-reflection that incorporate feedback from models themselves. Despite their effectiveness, these methods are hindered by their high computational cost and lack of scalability. In this work, we propose CERET, a method for refining text generations by considering semantic stability, entailment and inter-sample uncertainty measures. Experimental results show that CERET outperforms Self-consistency and Self-rerank baselines consistently under various task setups, by ~1.6% in Rouge-1 for abstractive summarization and ~3.5% in hit rate for question answering. Compared to LLM Self-rerank method, our approach only requires 9.4% of its latency and is more cost-effective.