 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsTALL: Context-aware Instructional Task Assistance with Multi-modal Large Language Models
Jan 21, 2025



The improved competence of generative models can help building multi-modal virtual assistants that leverage modalities beyond language. By observing humans performing multi-step tasks, one can build assistants that have situational awareness of actions and tasks being performed, enabling them to cater assistance based on this understanding. In this paper, we develop a Context-aware Instructional Task Assistant with Multi-modal Large Language Models (InsTALL) that leverages an online visual stream (e.g. a user's screen share or video recording) and responds in real-time to user queries related to the task at hand. To enable useful assistance, InsTALL 1) trains a multi-modal model on task videos and paired textual data, and 2) automatically extracts task graph from video data and leverages it at training and inference time. We show InsTALL achieves state-of-the-art performance across proposed sub-tasks considered for multimodal activity understanding -- task recognition (TR), action recognition (AR), next action prediction (AP), and plan prediction (PP) -- and outperforms existing baselines on two novel sub-tasks related to automatic error identification.
Multi-Objective Alignment of Large Language Models Through Hypervolume Maximization
Dec 06, 2024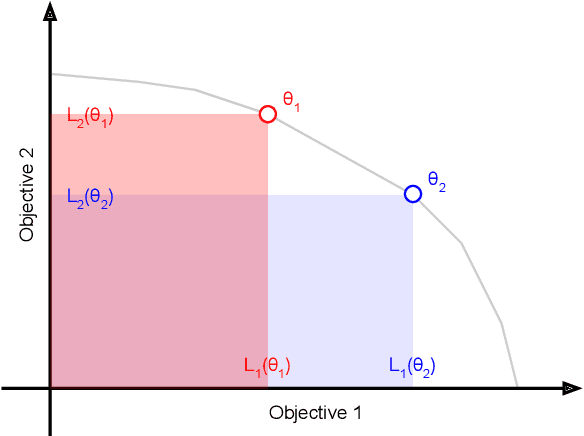


Multi-objective alignment from human feedback (MOAHF) in large language models (LLMs) is a challenging problem as human preferences are complex, multifaceted, and often conflicting. Recent works on MOAHF considered a-priori multi-objective optimization (MOO), where human preferences are known at training or inference time. In contrast, when human preferences are unknown or difficult to quantify, a natural approach is to cover the Pareto front by multiple diverse solutions. We propose an algorithm HaM for learning diverse LLM policies that maximizes their hypervolume. This is the first application of a-posteriori MOO to MOAHF. HaM is computationally and space efficient, and empirically superior across objectives such as harmlessness, helpfulness, humor, faithfulness, and hallucination, on various datasets.
SeRA: Self-Reviewing and Alignment of Large Language Models using Implicit Reward Margins
Oct 12, 2024Direct alignment algorithms (DAAs), such as direct preference optimization (DPO), have become popular alternatives for Reinforcement Learning from Human Feedback (RLHF) due to their simplicity, efficiency, and stability. However, the preferences used in DAAs are usually collected before the alignment training begins and remain unchanged (off-policy). This can lead to two problems where the policy model (1) picks up on spurious correlations in the dataset (as opposed to learning the intended alignment expressed in the human preference labels), and (2) overfits to feedback on off-policy trajectories that have less likelihood of being generated by an updated policy model. To address these issues, we introduce Self-Reviewing and Alignment (SeRA), a cost-efficient and effective method that can be readily combined with existing DAAs. SeRA comprises of two components: (1) sample selection using implicit reward margins, which helps alleviate over-fitting to some undesired features, and (2) preference bootstrapping using implicit rewards to augment preference data with updated policy models in a cost-efficient manner. Extensive experimentation, including some on instruction-following tasks, demonstrate the effectiveness and generality of SeRA in training LLMs on offline preference datasets with DAAs.
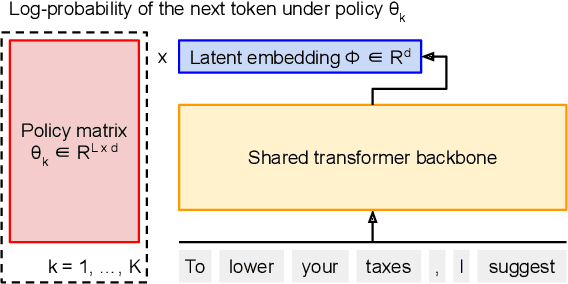
FLAP: Flow Adhering Planning with Constrained Decoding in LLMs
Mar 09, 2024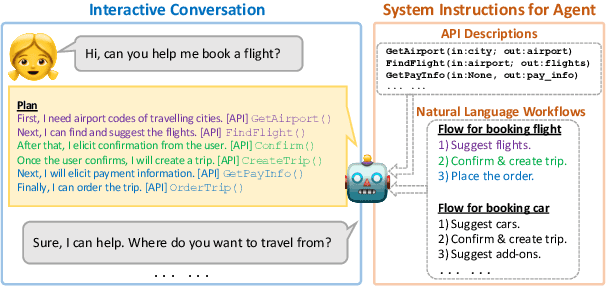
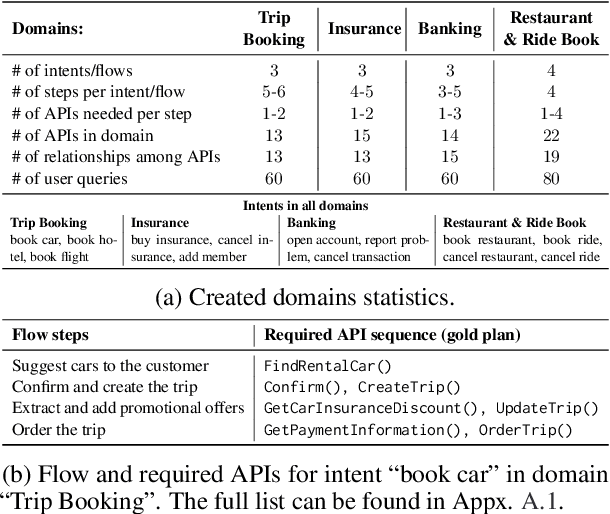
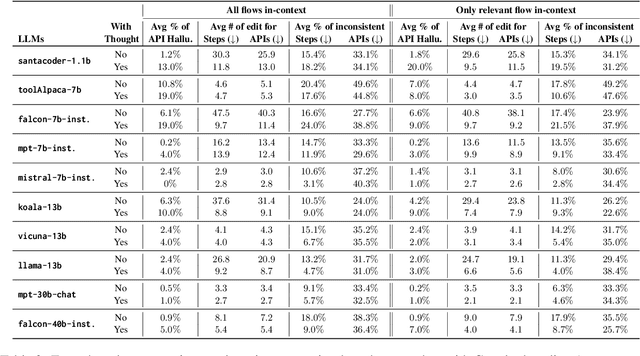
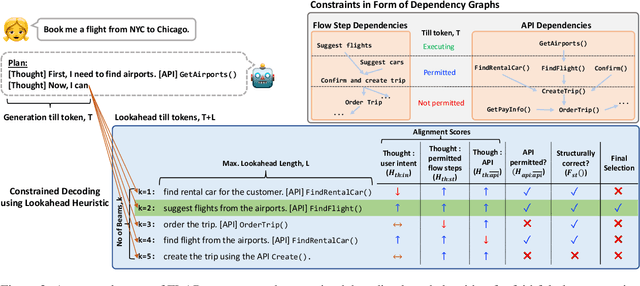
Planning is a crucial task for agents in task oriented dialogs (TODs). Human agents typically resolve user issues by following predefined workflows, decomposing workflow steps into actionable items, and performing actions by executing APIs in order; all of which require reasoning and planning. With the recent advances in LLMs, there have been increasing attempts to use LLMs for task planning and API usage. However, the faithfulness of the plans to predefined workflows and API dependencies, is not guaranteed with LLMs because of their bias towards pretraining data. Moreover, in real life, workflows are custom-defined and prone to change, hence, quickly adapting agents to the changes is desirable. In this paper, we study faithful planning in TODs to resolve user intents by following predefined flows and preserving API dependencies. We propose a constrained decoding algorithm based on lookahead heuristic for faithful planning. Our algorithm alleviates the need for finetuning LLMs using domain specific data, outperforms other decoding and prompting-based baselines, and applying our algorithm on smaller LLMs (7B) we achieve comparable performance to larger LLMs (30B-40B).
Can Your Model Tell a Negation from an Implicature? Unravelling Challenges With Intent Encoders
Mar 07, 2024



Conversational systems often rely on embedding models for intent classification and intent clustering tasks. The advent of Large Language Models (LLMs), which enable instructional embeddings allowing one to adjust semantics over the embedding space using prompts, are being viewed as a panacea for these downstream conversational tasks. However, traditional evaluation benchmarks rely solely on task metrics that don't particularly measure gaps related to semantic understanding. Thus, we propose an intent semantic toolkit that gives a more holistic view of intent embedding models by considering three tasks -- (1) intent classification, (2) intent clustering, and (3) a novel triplet task. The triplet task gauges the model's understanding of two semantic concepts paramount in real-world conversational systems -- negation and implicature. We observe that current embedding models fare poorly in semantic understanding of these concepts. To address this, we propose a pre-training approach to improve the embedding model by leveraging augmentation with data generated by an auto-regressive model and a contrastive loss term. Our approach improves the semantic understanding of the intent embedding model on the aforementioned linguistic dimensions while slightly effecting their performance on downstream task metrics.
DeAL: Decoding-time Alignment for Large Language Models
Feb 05, 2024



Large Language Models (LLMs) are nowadays expected to generate content aligned with human preferences. Current work focuses on alignment at model training time, through techniques such as Reinforcement Learning with Human Feedback (RLHF). However, it is unclear if such methods are an effective choice to teach alignment objectives to the model. First, the inability to incorporate multiple, custom rewards and reliance on a model developer's view of universal and static principles are key limitations. Second, the residual gaps in model training and the reliability of such approaches are also questionable (e.g. susceptibility to jail-breaking even after safety training). To address these, we propose DeAL, a framework that allows the user to customize reward functions and enables Decoding-time Alignment of LLMs (DeAL). At its core, we view decoding as a heuristic-guided search process and facilitate the use of a wide variety of alignment objectives. Our experiments with programmatic constraints such as keyword and length constraints (studied widely in the pre-LLM era) and abstract objectives such as harmlessness and helpfulness (proposed in the post-LLM era) show that we can DeAL with fine-grained trade-offs, improve adherence to alignment objectives, and address residual gaps in LLMs. Lastly, while DeAL can be effectively paired with RLHF and prompting techniques, its generality makes decoding slower, an optimization we leave for future work.
Measuring and Mitigating Constraint Violations of In-Context Learning for Utterance-to-API Semantic Parsing
May 24, 2023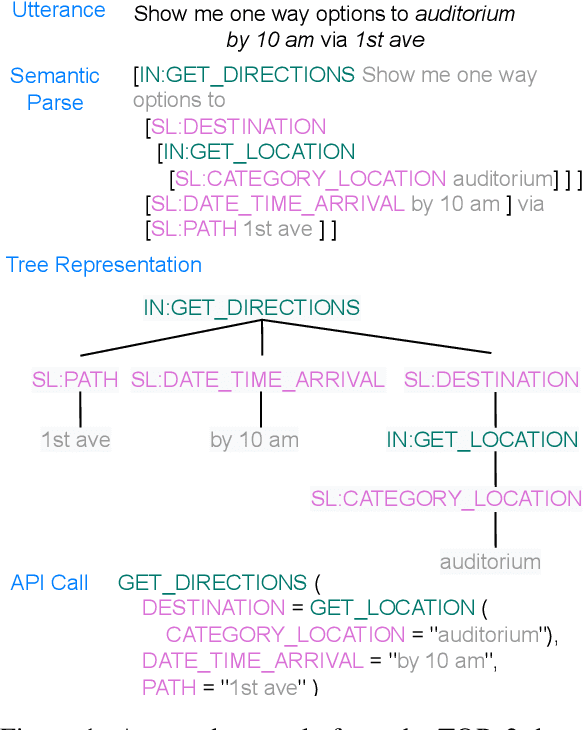
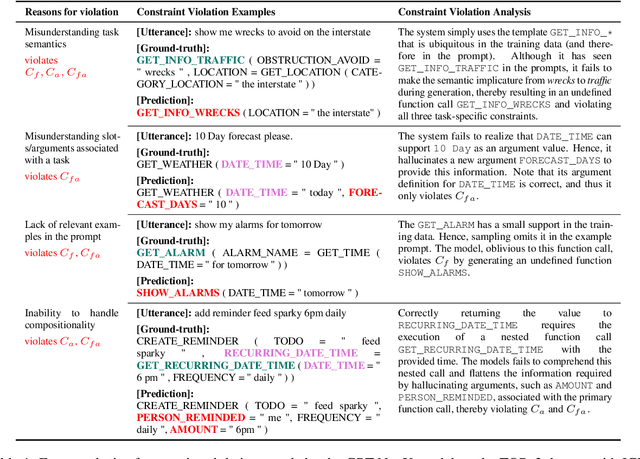
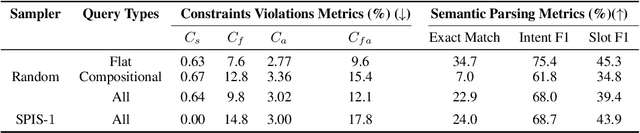
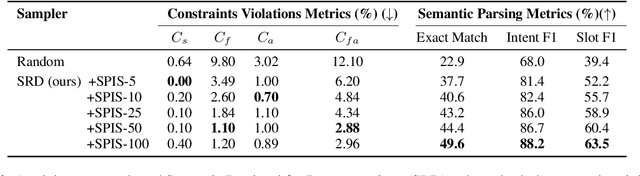
In executable task-oriented semantic parsing, the system aims to translate users' utterances in natural language to machine-interpretable programs (API calls) that can be executed according to pre-defined API specifications. With the popularity of Large Language Models (LLMs), in-context learning offers a strong baseline for such scenarios, especially in data-limited regimes. However, LLMs are known to hallucinate and therefore pose a formidable challenge in constraining generated content. Thus, it remains uncertain if LLMs can effectively perform task-oriented utterance-to-API generation where respecting API's structural and task-specific constraints is crucial. In this work, we seek to measure, analyze and mitigate such constraints violations. First, we identify the categories of various constraints in obtaining API-semantics from task-oriented utterances, and define fine-grained metrics that complement traditional ones. Second, we leverage these metrics to conduct a detailed error analysis of constraints violations seen in state-of-the-art LLMs, which motivates us to investigate two mitigation strategies: Semantic-Retrieval of Demonstrations (SRD) and API-aware Constrained Decoding (API-CD). Our experiments show that these strategies are effective at reducing constraints violations and improving the quality of the generated API calls, but require careful consideration given their implementation complexity and latency.
Parameter and Data Efficient Continual Pre-training for Robustness to Dialectal Variance in Arabic
Nov 08, 2022The use of multilingual language models for tasks in low and high-resource languages has been a success story in deep learning. In recent times, Arabic has been receiving widespread attention on account of its dialectal variance. While prior research studies have tried to adapt these multilingual models for dialectal variants of Arabic, it still remains a challenging problem owing to the lack of sufficient monolingual dialectal data and parallel translation data of such dialectal variants. It remains an open problem on whether the limited dialectical data can be used to improve the models trained in Arabic on its dialectal variants. First, we show that multilingual-BERT (mBERT) incrementally pretrained on Arabic monolingual data takes less training time and yields comparable accuracy when compared to our custom monolingual Arabic model and beat existing models (by an avg metric of +$6.41$). We then explore two continual pre-training methods -- (1) using small amounts of dialectical data for continual finetuning and (2) parallel Arabic to English data and a Translation Language Modeling loss function. We show that both approaches help improve performance on dialectal classification tasks ($+4.64$ avg. gain) when used on monolingual models.
Robustification of Multilingual Language Models to Real-world Noise with Robust Contrastive Pretraining
Oct 10, 2022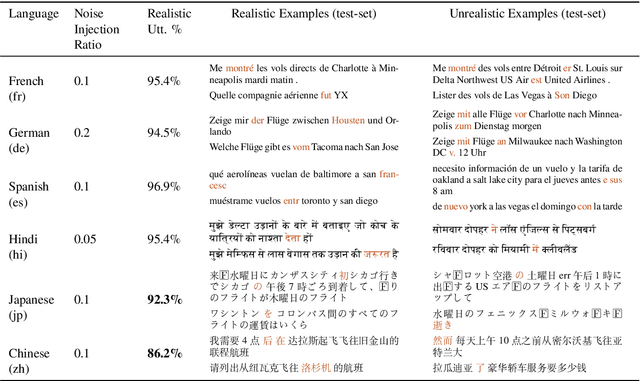
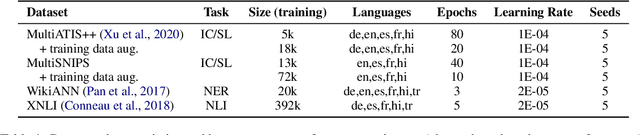
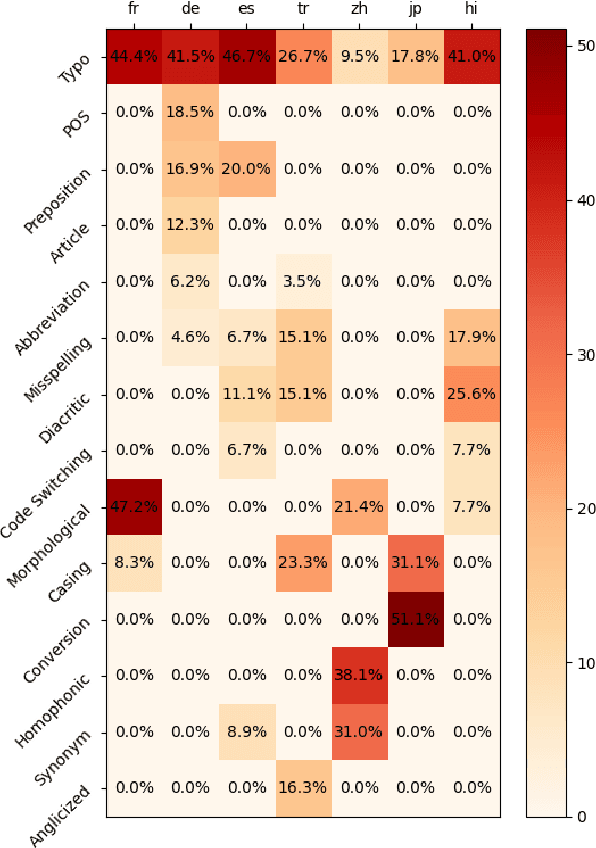
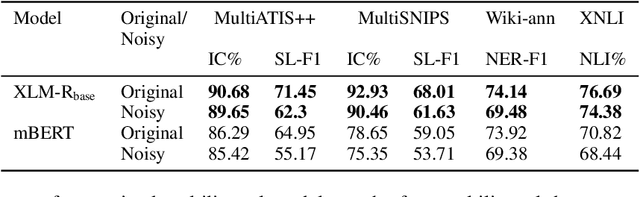
Advances in neural modeling have achieved state-of-the-art (SOTA) results on public natural language processing (NLP) benchmarks, at times surpassing human performance. However, there is a gap between public benchmarks and real-world applications where noise such as typos or grammatical mistakes is abundant, resulting in degraded performance. Unfortunately, works that assess the robustness of neural models on noisy data and suggest improvements are limited to the English language. Upon analyzing noise in different languages, we observe that noise types vary across languages and thus require their own investigation. Thus, to benchmark the performance of pretrained multilingual models, we construct noisy datasets covering five languages and four NLP tasks. We see a gap in performance between clean and noisy data. After investigating ways to boost the zero-shot cross-lingual robustness of multilingual pretrained models, we propose Robust Contrastive Pretraining (RCP). RCP combines data augmentation with a contrastive loss term at the pretraining stage and achieves large improvements on noisy (& original test data) across two sentence-level classification (+3.2%) and two sequence-labeling (+10 F1-score) multilingual tasks.
On the Robustness of Goal Oriented Dialogue Systems to Real-world Noise
Apr 14, 2021
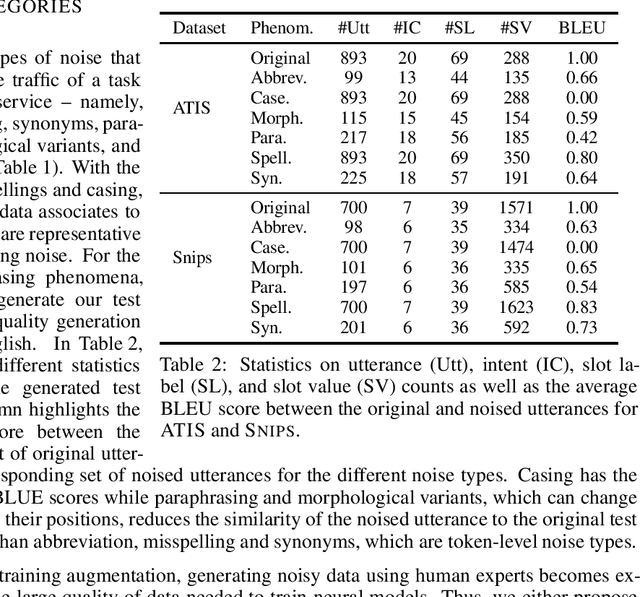
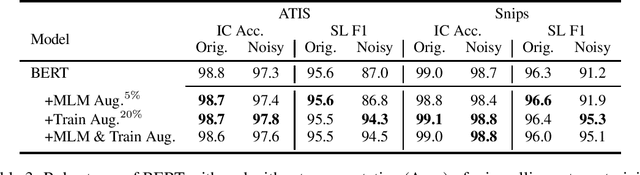
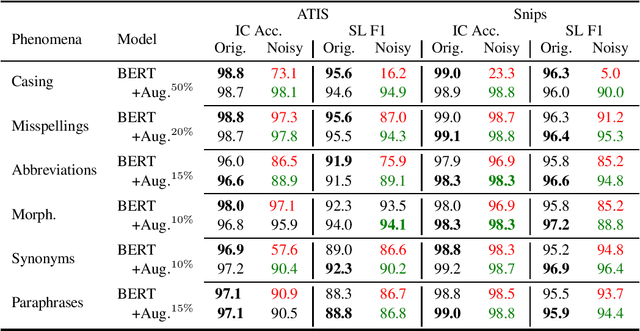
Goal oriented dialogue systems, that interact in real-word environments, often encounter noisy data. In this work, we investigate how robust goal oriented dialogue systems are to noisy data. Specifically, our analysis considers intent classification (IC) and slot labeling (SL) models that form the basis of most dialogue systems. We collect a test-suite for six common phenomena found in live human-to-bot conversations (abbreviations, casing, misspellings, morphological variants, paraphrases, and synonyms) and show that these phenomena can degrade the IC/SL performance of state-of-the-art BERT based models. Through the use of synthetic data augmentation, we are improve IC/SL model's robustness to real-world noise by +11.5 for IC and +17.3 points for SL on average across noise types. We make our suite of noisy test data public to enable further research into the robustness of dialog systems.