 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Goal Oriented Dialogue Systems to Real-world Noise
Apr 14, 2021
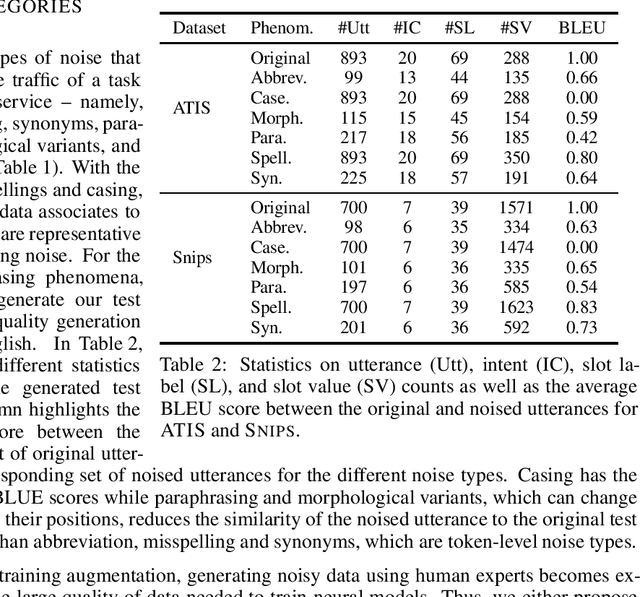
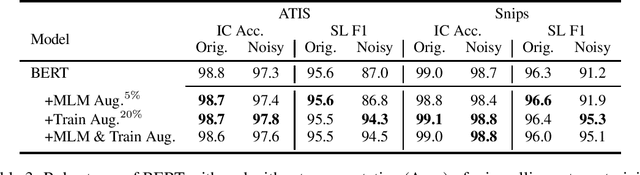
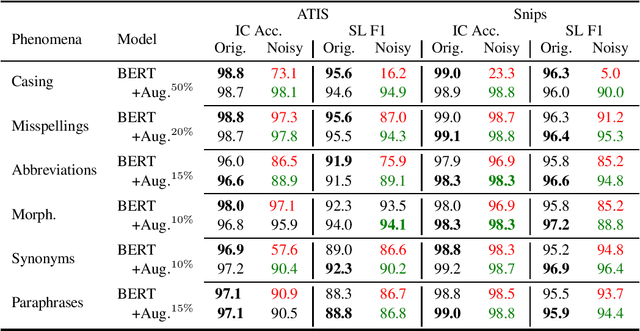
Goal oriented dialogue systems, that interact in real-word environments, often encounter noisy data. In this work, we investigate how robust goal oriented dialogue systems are to noisy data. Specifically, our analysis considers intent classification (IC) and slot labeling (SL) models that form the basis of most dialogue systems. We collect a test-suite for six common phenomena found in live human-to-bot conversations (abbreviations, casing, misspellings, morphological variants, paraphrases, and synonyms) and show that these phenomena can degrade the IC/SL performance of state-of-the-art BERT based models. Through the use of synthetic data augmentation, we are improve IC/SL model's robustness to real-world noise by +11.5 for IC and +17.3 points for SL on average across noise types. We make our suite of noisy test data public to enable further research into the robustness of dialog systems.