 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Alignment of Large Language Models Through Hypervolume Maximization
Paper and Code
Dec 06, 2024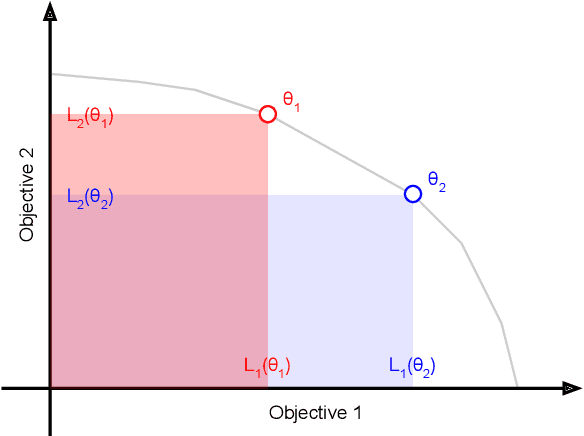

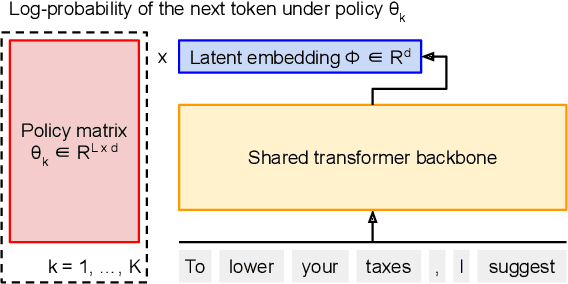

Multi-objective alignment from human feedback (MOAHF) in large language models (LLMs) is a challenging problem as human preferences are complex, multifaceted, and often conflicting. Recent works on MOAHF considered a-priori multi-objective optimization (MOO), where human preferences are known at training or inference time. In contrast, when human preferences are unknown or difficult to quantify, a natural approach is to cover the Pareto front by multiple diverse solutions. We propose an algorithm HaM for learning diverse LLM policies that maximizes their hypervolume. This is the first application of a-posteriori MOO to MOAHF. HaM is computationally and space efficient, and empirically superior across objectives such as harmlessness, helpfulness, humor, faithfulness, and hallucination, on various datasets.