 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Alignment of Large Language Models Through Hypervolume Maximization
Dec 06, 2024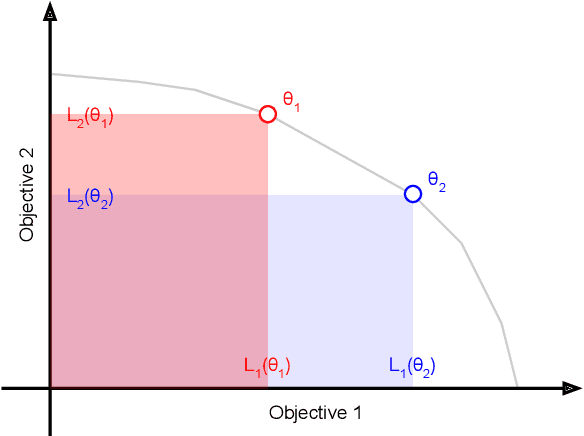

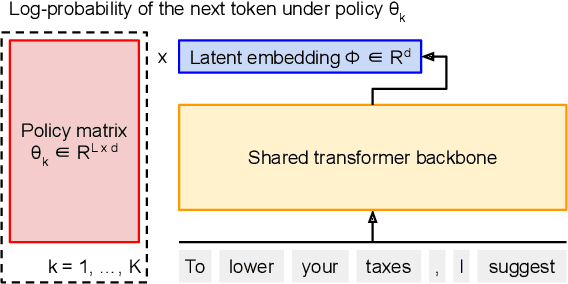

Multi-objective alignment from human feedback (MOAHF) in large language models (LLMs) is a challenging problem as human preferences are complex, multifaceted, and often conflicting. Recent works on MOAHF considered a-priori multi-objective optimization (MOO), where human preferences are known at training or inference time. In contrast, when human preferences are unknown or difficult to quantify, a natural approach is to cover the Pareto front by multiple diverse solutions. We propose an algorithm HaM for learning diverse LLM policies that maximizes their hypervolume. This is the first application of a-posteriori MOO to MOAHF. HaM is computationally and space efficient, and empirically superior across objectives such as harmlessness, helpfulness, humor, faithfulness, and hallucination, on various datasets.
Optimal Design for Human Feedback
Apr 22, 2024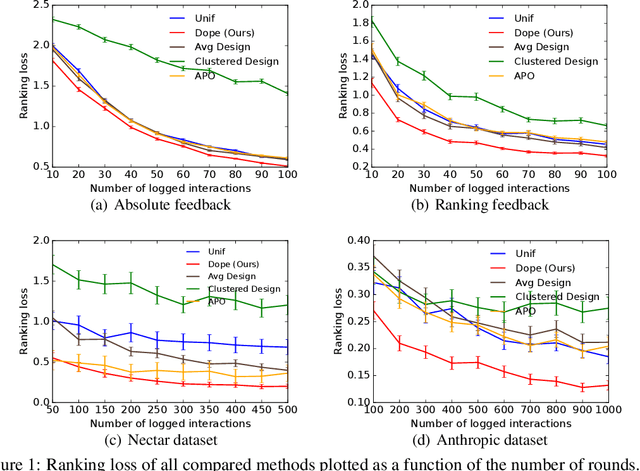


Learning of preference models from human feedback has been central to recent advances in artificial intelligence. Motivated by this progress, and the cost of obtaining high-quality human annotations, we study the problem of data collection for learning preference models. The key idea in our work is to generalize optimal designs, a tool for computing efficient data logging policies, to ranked lists. To show the generality of our ideas, we study both absolute and relative feedback on items in the list. We design efficient algorithms for both settings and analyze them. We prove that our preference model estimators improve with more data and so does the ranking error under the estimators. Finally, we experiment with several synthetic and real-world datasets to show the statistical efficiency of our algorithms.
Experimental Design for Active Transductive Inference in Large Language Models
Apr 12, 2024



Transduction, the ability to include query-specific examples in the prompt at inference time, is one of the emergent abilities of large language models (LLMs). In this work, we propose a framework for adaptive prompt design called active transductive inference (ATI). We design the LLM prompt by adaptively choosing few-shot examples for a given inference query. The examples are initially unlabeled and we query the user to label the most informative ones, which maximally reduces the uncertainty in the LLM prediction. We propose two algorithms, GO and SAL, which differ in how the few-shot examples are chosen. We analyze these algorithms in linear models: first GO and then use its equivalence with SAL. We experiment with many different tasks and show that GO and SAL outperform other methods for choosing few-shot examples in the LLM prompt at inference time.
Fixed-Budget Best-Arm Identification with Heterogeneous Reward Variances
Jun 13, 2023We study the problem of best-arm identification (BAI) in the fixed-budget setting with heterogeneous reward variances. We propose two variance-adaptive BAI algorithms for this setting: SHVar for known reward variances and SHAdaVar for unknown reward variances. Our algorithms rely on non-uniform budget allocations among the arms where the arms with higher reward variances are pulled more often than those with lower variances. The main algorithmic novelty is in the design of SHAdaVar, which allocates budget greedily based on overestimating the unknown reward variances. We bound probabilities of misidentifying the best arms in both SHVar and SHAdaVar. Our analyses rely on novel lower bounds on the number of pulls of an arm that do not require closed-form solutions to the budget allocation problem. Since one of our budget allocation problems is analogous to the optimal experiment design with unknown variances, we believe that our results are of a broad interest. Our experiments validate our theory, and show that SHVar and SHAdaVar outperform algorithms from prior works with analytical guarantees.
Partner-Aware Algorithms in Decentralized Cooperative Bandit Teams
Oct 02, 2021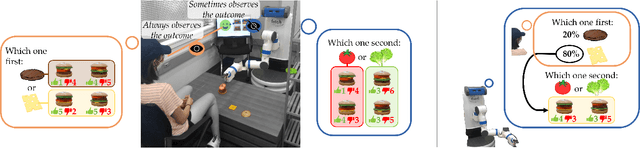
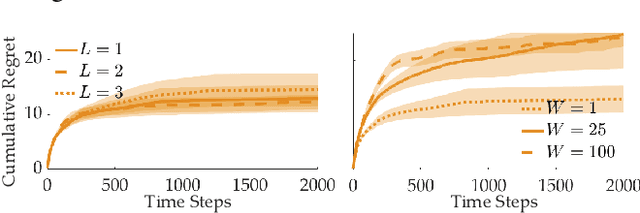
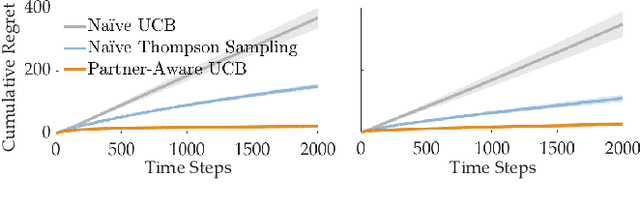
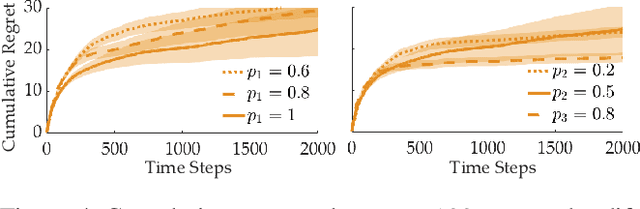
When humans collaborate with each other, they often make decisions by observing others and considering the consequences that their actions may have on the entire team, instead of greedily doing what is best for just themselves. We would like our AI agents to effectively collaborate in a similar way by capturing a model of their partners. In this work, we propose and analyze a decentralized Multi-Armed Bandit (MAB) problem with coupled rewards as an abstraction of more general multi-agent collaboration. We demonstrate that na\"ive extensions of single-agent optimal MAB algorithms fail when applied for decentralized bandit teams. Instead, we propose a Partner-Aware strategy for joint sequential decision-making that extends the well-known single-agent Upper Confidence Bound algorithm. We analytically show that our proposed strategy achieves logarithmic regret, and provide extensive experiments involving human-AI and human-robot collaboration to validate our theoretical findings. Our results show that the proposed partner-aware strategy outperforms other known methods, and our human subject studies suggest humans prefer to collaborate with AI agents implementing our partner-aware strategy.
Bayesian Algorithms for Decentralized Stochastic Bandits
Oct 28, 2020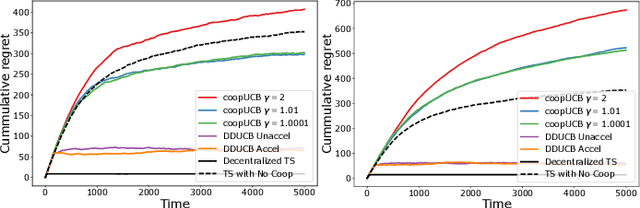
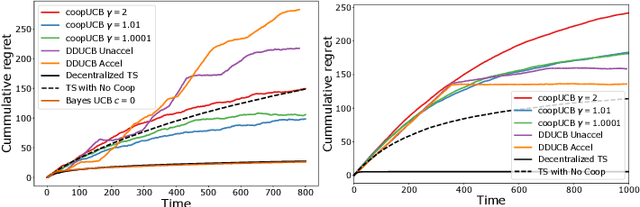
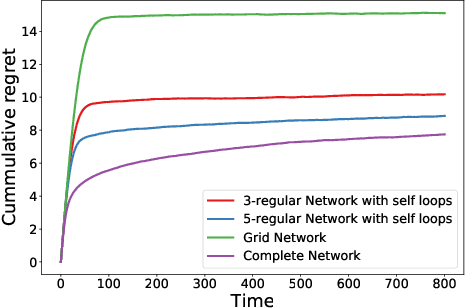
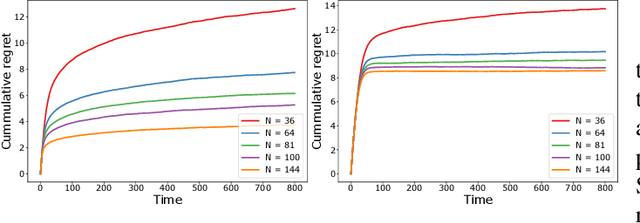
We study a decentralized cooperative multi-agent multi-armed bandit problem with $K$ arms and $N$ agents connected over a network. In our model, each arm's reward distribution is same for all agents, and rewards are drawn independently across agents and over time steps. In each round, agents choose an arm to play and subsequently send a message to their neighbors. The goal is to minimize cumulative regret averaged over the entire network. We propose a decentralized Bayesian multi-armed bandit framework that extends single-agent Bayesian bandit algorithms to the decentralized setting. Specifically, we study an information assimilation algorithm that can be combined with existing Bayesian algorithms, and using this, we propose a decentralized Thompson Sampling algorithm and decentralized Bayes-UCB algorithm. We analyze the decentralized Thompson Sampling algorithm under Bernoulli rewards and establish a problem-dependent upper bound on the cumulative regret. We show that regret incurred scales logarithmically over the time horizon with constants that match those of an optimal centralized agent with access to all observations across the network. Our analysis also characterizes the cumulative regret in terms of the network structure. Through extensive numerical studies, we show that our extensions of Thompson Sampling and Bayes-UCB incur lesser cumulative regret than the state-of-art algorithms inspired by the Upper Confidence Bound algorithm. We implement our proposed decentralized Thompson Sampling under gossip protocol, and over time-varying networks, where each communication link has a fixed probability of failure.
Decentralized Bayesian Learning over Graphs
May 24, 2019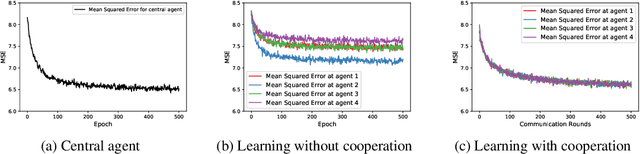
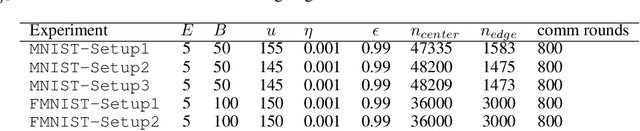
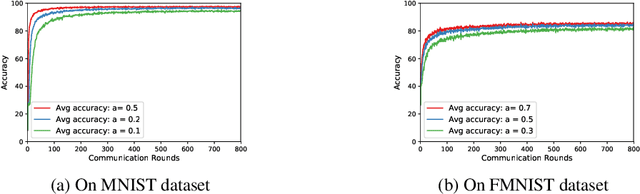

We propose a decentralized learning algorithm over a general social network. The algorithm leaves the training data distributed on the mobile devices while utilizing a peer to peer model aggregation method. The proposed algorithm allows agents with local data to learn a shared model explaining the global training data in a decentralized fashion. The proposed algorithm can be viewed as a Bayesian and peer-to-peer variant of federated learning in which each agent keeps a "posterior probability distribution" over a global model parameters. The agent update its "posterior" based on 1) the local training data and 2) the asynchronous communication and model aggregation with their 1-hop neighbors. This Bayesian formulation allows for a systematic treatment of model aggregation over any arbitrary connected graph. Furthermore, it provides strong analytic guarantees on converge in the realizable case as well as a closed form characterization of the rate of convergence. We also show that our methodology can be combined with efficient Bayesian inference techniques to train Bayesian neural networks in a decentralized manner. By empirical studies we show that our theoretical analysis can guide the design of network/social interactions and data partitioning to achieve convergence.
Peer-to-peer Federated Learning on Graphs
Jan 31, 2019
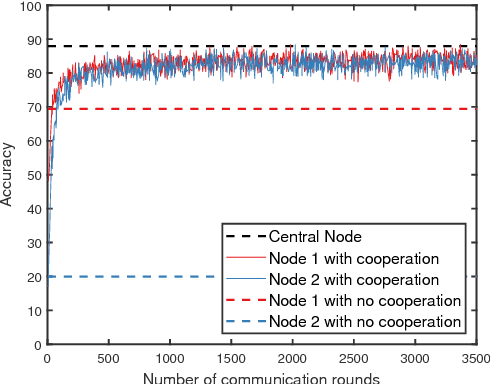
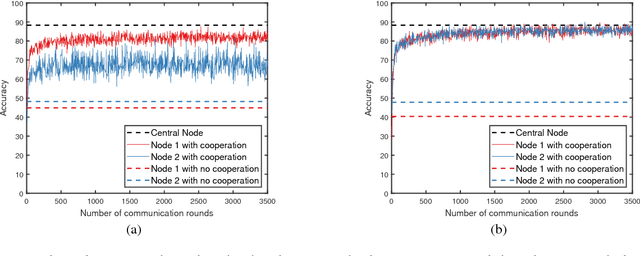

We consider the problem of training a machine learning model over a network of nodes in a fully decentralized framework. The nodes take a Bayesian-like approach via the introduction of a belief over the model parameter space. We propose a distributed learning algorithm in which nodes update their belief by aggregate information from their one-hop neighbors to learn a model that best fits the observations over the entire network. In addition, we also obtain sufficient conditions to ensure that the probability of error is small for every node in the network. We discuss approximations required for applying this algorithm to train Deep Neural Networks (DNNs). Experiments on training linear regression model and on training a DNN show that the proposed learning rule algorithm provides a significant improvement in the accuracy compared to the case where nodes learn without cooperation.
Automatic Grammar Augmentation for Robust Voice Command Recognition
Nov 14, 2018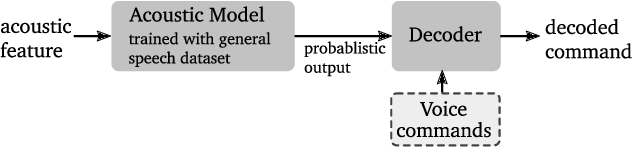


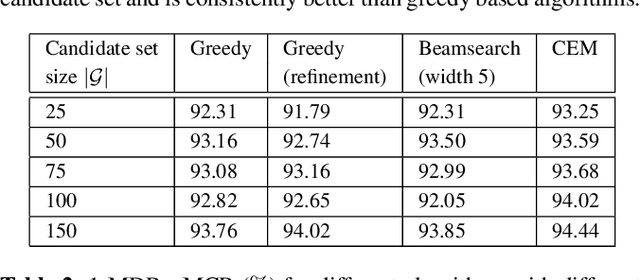
This paper proposes a novel pipeline for automatic grammar augmentation that provides a significant improvement in the voice command recognition accuracy for systems with small footprint acoustic model (AM). The improvement is achieved by augmenting the user-defined voice command set, also called grammar set, with alternate grammar expressions. For a given grammar set, a set of potential grammar expressions (candidate set) for augmentation is constructed from an AM-specific statistical pronunciation dictionary that captures the consistent patterns and errors in the decoding of AM induced by variations in pronunciation, pitch, tempo, accent, ambiguous spellings, and noise conditions. Using this candidate set, greedy optimization based and cross-entropy-method (CEM) based algorithms are considered to search for an augmented grammar set with improved recognition accuracy utilizing a command-specific dataset. Our experiments show that the proposed pipeline along with algorithms considered in this paper significantly reduce the mis-detection and mis-classification rate without increasing the false-alarm rate. Experiments also demonstrate the consistent superior performance of CEM method over greedy-based algorithms.