 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Bayesian Learning over Graphs
May 24, 2019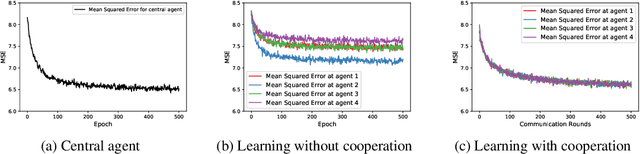
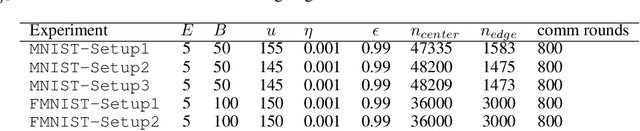
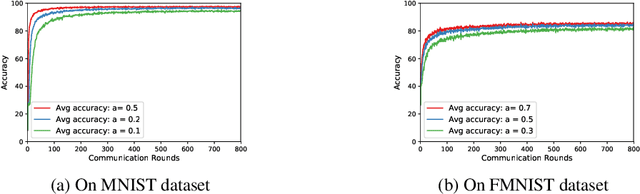

We propose a decentralized learning algorithm over a general social network. The algorithm leaves the training data distributed on the mobile devices while utilizing a peer to peer model aggregation method. The proposed algorithm allows agents with local data to learn a shared model explaining the global training data in a decentralized fashion. The proposed algorithm can be viewed as a Bayesian and peer-to-peer variant of federated learning in which each agent keeps a "posterior probability distribution" over a global model parameters. The agent update its "posterior" based on 1) the local training data and 2) the asynchronous communication and model aggregation with their 1-hop neighbors. This Bayesian formulation allows for a systematic treatment of model aggregation over any arbitrary connected graph. Furthermore, it provides strong analytic guarantees on converge in the realizable case as well as a closed form characterization of the rate of convergence. We also show that our methodology can be combined with efficient Bayesian inference techniques to train Bayesian neural networks in a decentralized manner. By empirical studies we show that our theoretical analysis can guide the design of network/social interactions and data partitioning to achieve convergence.
Implicit Label Augmentation on Partially Annotated Clips via Temporally-Adaptive Features Learning
May 24, 2019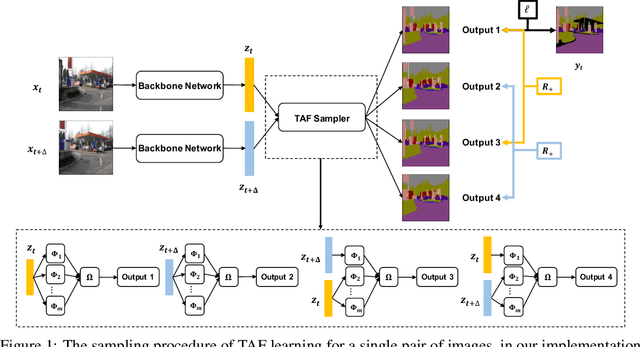
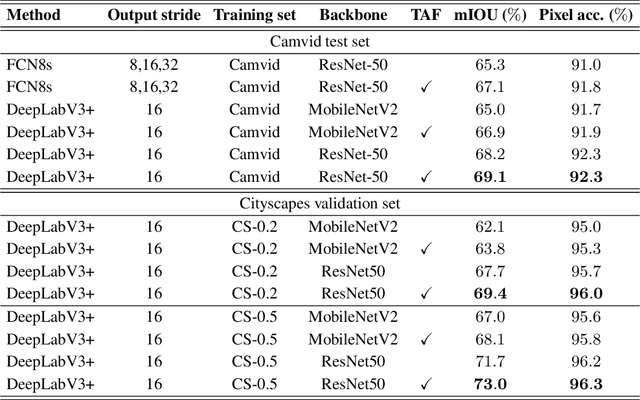
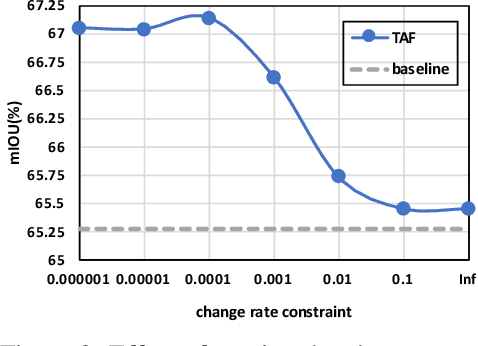
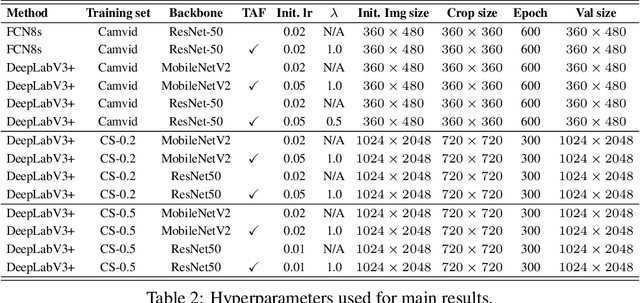
Partially annotated clips contain rich temporal contexts that can complement the sparse key frame annotations in providing supervision for model training. We present a novel paradigm called Temporally-Adaptive Features (TAF) learning that can utilize such data to learn better single frame models. By imposing distinct temporal change rate constraints on different factors in the model, TAF enables learning from unlabeled frames using context to enhance model accuracy. TAF generalizes "slow feature" learning and we present much stronger empirical evidence than prior works, showing convincing gains for the challenging semantic segmentation task over a variety of architecture designs and on two popular datasets. TAF can be interpreted as an implicit label augmentation method but is a more principled formulation compared to existing explicit augmentation techniques. Our work thus connects two promising methods that utilize partially annotated clips for single frame model training and can inspire future explorations in this direction.
SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception
Dec 13, 2018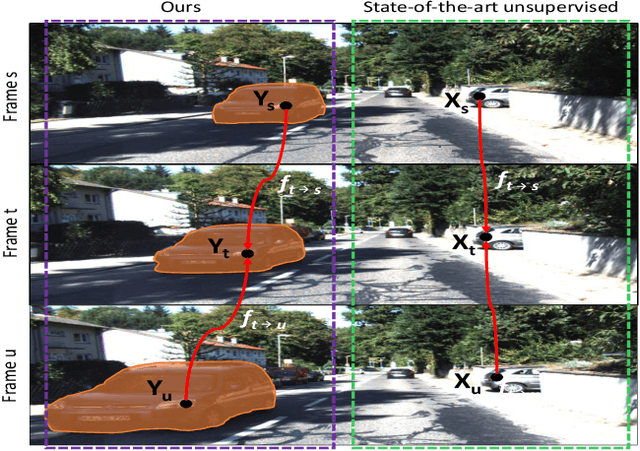
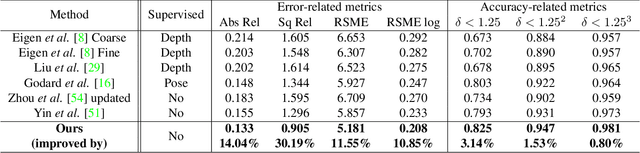
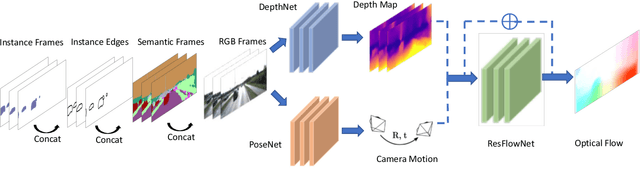
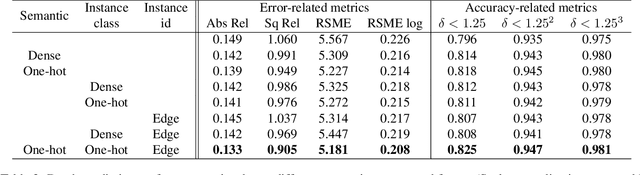
Unsupervised learning for visual perception of 3D geometry is of great interest to autonomous systems. Recent works on unsupervised learning have made considerable progress on geometry perception; however, they perform poorly on dynamic objects and scenarios with dark and noisy environments. In contrast, supervised learning algorithms, which are robust, require large labeled geometric data-set. This paper introduces SIGNet, a novel framework that provides robust geometry perception without requiring geometrically informative labels. Specifically, SIGNet integrates semantic information to make unsupervised robust geometric predictions for dynamic objects in low lighting and noisy environments. SIGNet is shown to improve upon the state of art unsupervised learning for geometry perception by 30% (in squared relative error for depth prediction). In particular, SIGNet improves the dynamic object class performance by 39% in depth prediction and 29% in flow prediction.
Efficient Video Understanding via Layered Multi Frame-Rate Analysis
Nov 24, 2018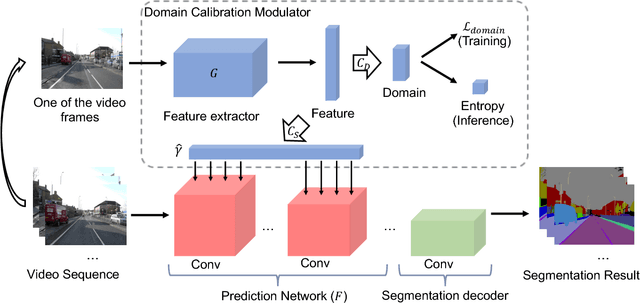
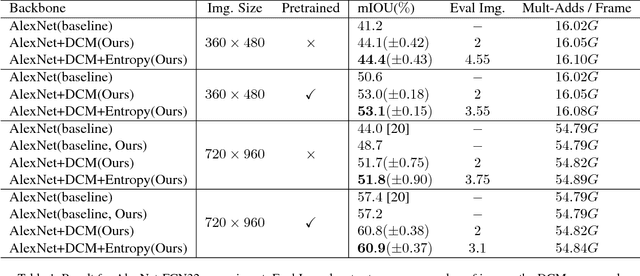
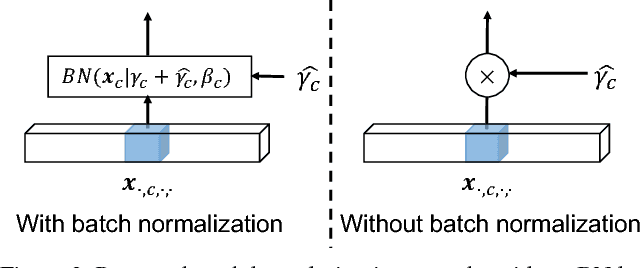
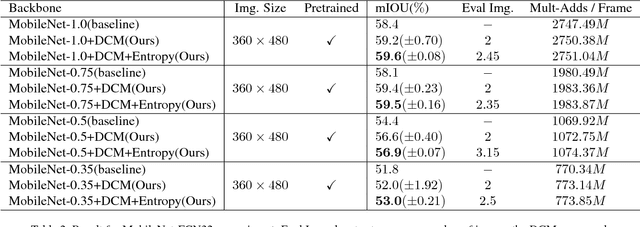
One of the greatest challenges in the design of a real-time perception system for autonomous driving vehicles and drones is the conflicting requirement of safety (high prediction accuracy) and efficiency. Traditional approaches use a single frame rate for the entire system. Motivated by the observation that the lack of robustness against environmental factors is the major weakness of compact ConvNet architectures, we propose a dual frame-rate system that brings in the best of both worlds: A modulator stream that executes an expensive models robust to environmental factors at a low frame rate to extract slowly changing features describing the environment, and a prediction stream that executes a light-weight model at real-time to extract transient signals that describes particularities of the current frame. The advantage of our design is validated by our extensive empirical study, showing that our solution leads to consistent improvements using a variety of backbone architecture choice and input resolutions. These findings suggest multiple frame-rate systems as a promising direction in designing efficient perception for autonomous agents.
Fully-adaptive Feature Sharing in Multi-Task Networks with Applications in Person Attribute Classification
Nov 16, 2016
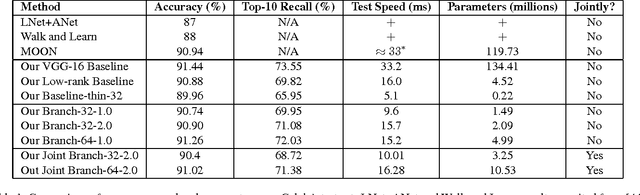

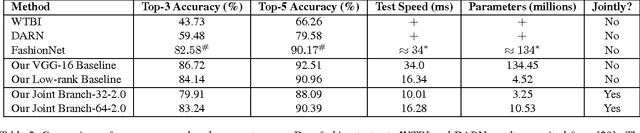
Multi-task learning aims to improve generalization performance of multiple prediction tasks by appropriately sharing relevant information across them. In the context of deep neural networks, this idea is often realized by hand-designed network architectures with layers that are shared across tasks and branches that encode task-specific features. However, the space of possible multi-task deep architectures is combinatorially large and often the final architecture is arrived at by manual exploration of this space subject to designer's bias, which can be both error-prone and tedious. In this work, we propose a principled approach for designing compact multi-task deep learning architectures. Our approach starts with a thin network and dynamically widens it in a greedy manner during training using a novel criterion that promotes grouping of similar tasks together. Our Extensive evaluation on person attributes classification tasks involving facial and clothing attributes suggests that the models produced by the proposed method are fast, compact and can closely match or exceed the state-of-the-art accuracy from strong baselines by much more expensive models.
S3Pool: Pooling with Stochastic Spatial Sampling
Nov 16, 2016
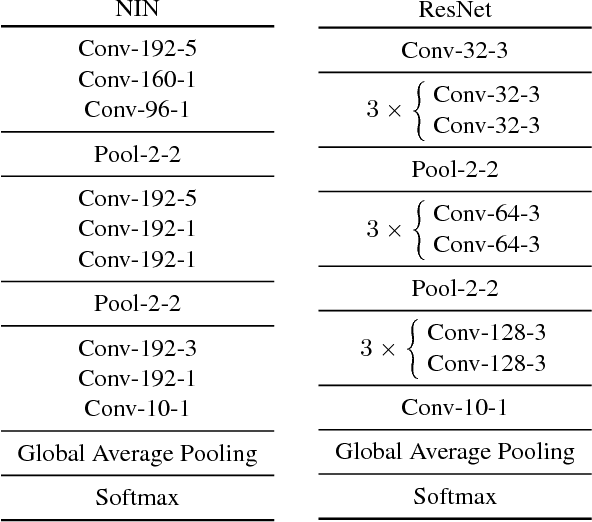
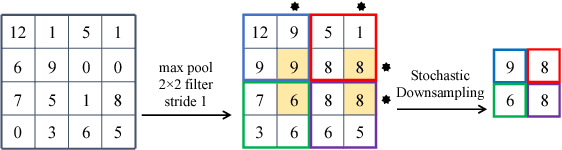
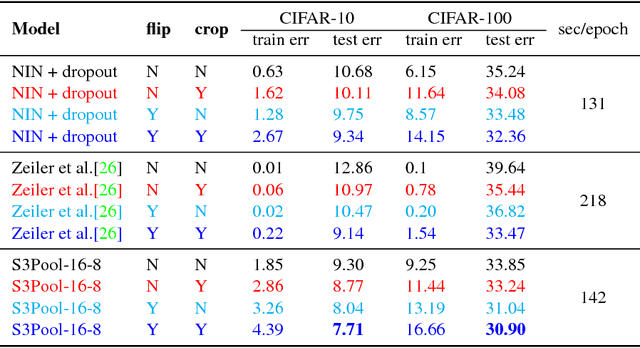
Feature pooling layers (e.g., max pooling) in convolutional neural networks (CNNs) serve the dual purpose of providing increasingly abstract representations as well as yielding computational savings in subsequent convolutional layers. We view the pooling operation in CNNs as a two-step procedure: first, a pooling window (e.g., $2\times 2$) slides over the feature map with stride one which leaves the spatial resolution intact, and second, downsampling is performed by selecting one pixel from each non-overlapping pooling window in an often uniform and deterministic (e.g., top-left) manner. Our starting point in this work is the observation that this regularly spaced downsampling arising from non-overlapping windows, although intuitive from a signal processing perspective (which has the goal of signal reconstruction), is not necessarily optimal for \emph{learning} (where the goal is to generalize). We study this aspect and propose a novel pooling strategy with stochastic spatial sampling (S3Pool), where the regular downsampling is replaced by a more general stochastic version. We observe that this general stochasticity acts as a strong regularizer, and can also be seen as doing implicit data augmentation by introducing distortions in the feature maps. We further introduce a mechanism to control the amount of distortion to suit different datasets and architectures. To demonstrate the effectiveness of the proposed approach, we perform extensive experiments on several popular image classification benchmarks, observing excellent improvements over baseline models. Experimental code is available at https://github.com/Shuangfei/s3pool.
Adaptive Object Detection Using Adjacency and Zoom Prediction
Apr 11, 2016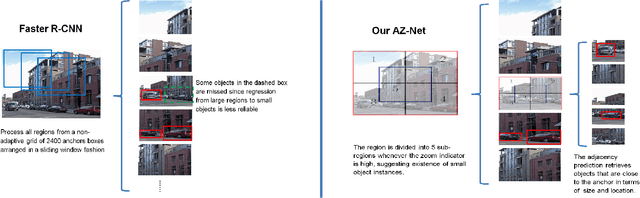

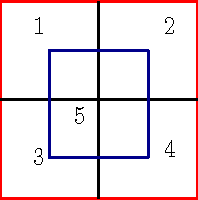

State-of-the-art object detection systems rely on an accurate set of region proposals. Several recent methods use a neural network architecture to hypothesize promising object locations. While these approaches are computationally efficient, they rely on fixed image regions as anchors for predictions. In this paper we propose to use a search strategy that adaptively directs computational resources to sub-regions likely to contain objects. Compared to methods based on fixed anchor locations, our approach naturally adapts to cases where object instances are sparse and small. Our approach is comparable in terms of accuracy to the state-of-the-art Faster R-CNN approach while using two orders of magnitude fewer anchors on average. Code is publicly available.
Efficient Object Detection for High Resolution Images
Oct 05, 2015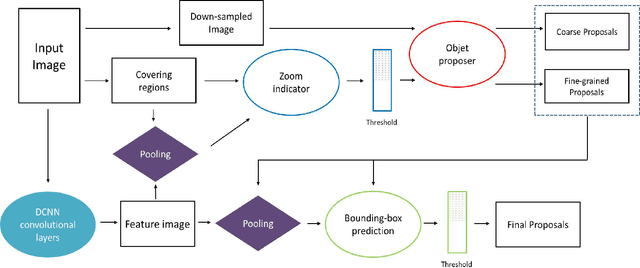
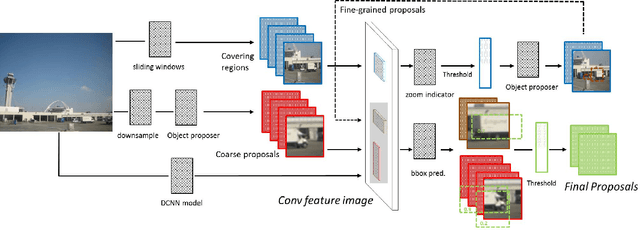
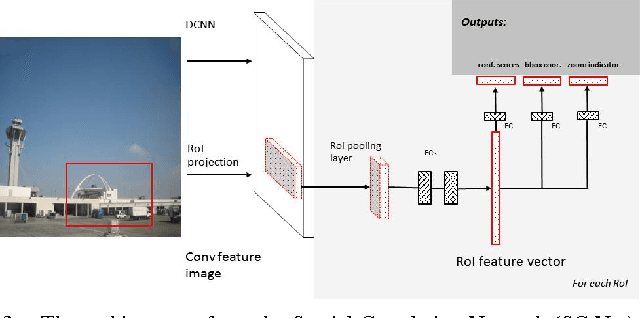

Efficient generation of high-quality object proposals is an essential step in state-of-the-art object detection systems based on deep convolutional neural networks (DCNN) features. Current object proposal algorithms are computationally inefficient in processing high resolution images containing small objects, which makes them the bottleneck in object detection systems. In this paper we present effective methods to detect objects for high resolution images. We combine two complementary strategies. The first approach is to predict bounding boxes based on adjacent visual features. The second approach uses high level image features to guide a two-step search process that adaptively focuses on regions that are likely to contain small objects. We extract features required for the two strategies by utilizing a pre-trained DCNN model known as AlexNet. We demonstrate the effectiveness of our algorithm by showing its performance on a high-resolution image subset of the SUN 2012 object detection dataset.