 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Sycophancy: Negation-Based Gaslighting in Video Large Language Models
Apr 20, 2026Video Large Language Models (Vid-LLMs) have demonstrated remarkable performance in video understanding tasks, yet their robustness under conversational interaction remains largely underexplored. In this paper, we identify spatiotemporal sycophancy, a failure mode in which Vid-LLMs retract initially correct, visually grounded judgments and conform to misleading user feedback under negation-based gaslighting. Rather than merely changing their answers, the models often fabricate unsupported temporal or spatial explanations to justify incorrect revisions. To systematically investigate this phenomenon, we propose a negation-based gaslighting evaluation framework and introduce GasVideo-1000, a curated benchmark designed to probe spatiotemporal sycophancy with clear visual grounding and temporal reasoning requirements. We evaluate a broad range of state-of-the-art open-source and proprietary Vid-LLMs across diverse video understanding tasks. Extensive experiments reveal that vulnerability to negation-based gaslighting is pervasive and severe, even among models with strong baseline performance. While prompt-level grounding constraints can partially mitigate this behavior, they do not reliably prevent hallucinated justifications or belief reversal. Our results indicate that current Vid-LLMs lack robust mechanisms for maintaining grounded spatiotemporal beliefs under adversarial conversational feedback.
Predicting Future Utility: Global Combinatorial Optimization for Task-Agnostic KV Cache Eviction
Feb 09, 2026Given the quadratic complexity of attention, KV cache eviction is vital to accelerate model inference. Current KV cache eviction methods typically rely on instantaneous heuristic metrics, implicitly assuming that score magnitudes are consistent proxies for importance across all heads. However, this overlooks the heterogeneity in predictive fidelity across attention heads. While certain heads prioritize the instantaneous contribution of tokens, others are dedicated to capturing long-horizon utility. In this paper, we propose that optimal budget allocation should be governed by the marginal utility in preserving long-term semantic information. Based on this insight, we propose LU-KV, a novel framework that optimizes head-level budget allocation through a convex-hull relaxation and a marginal-utility-based greedy solver to achieve near-optimal precision. Furthermore, we implement a data-driven offline profiling protocol to facilitate the practical deployment of LU-KV. Extensive evaluations on LongBench and RULER benchmarks demonstrate that LU-KV achieves an 80% reduction in KV cache size with minimal performance degradation, while simultaneously reducing inference latency and GPU memory footprint.
Implicit Label Augmentation on Partially Annotated Clips via Temporally-Adaptive Features Learning
May 24, 2019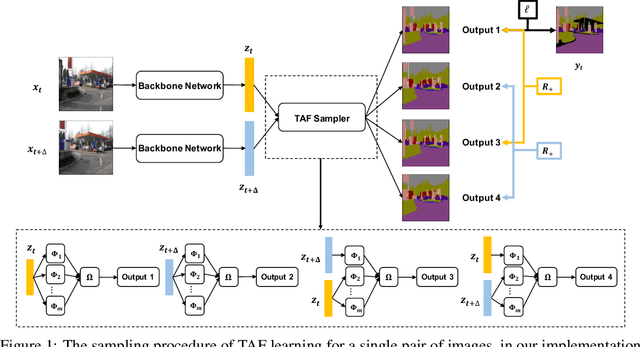
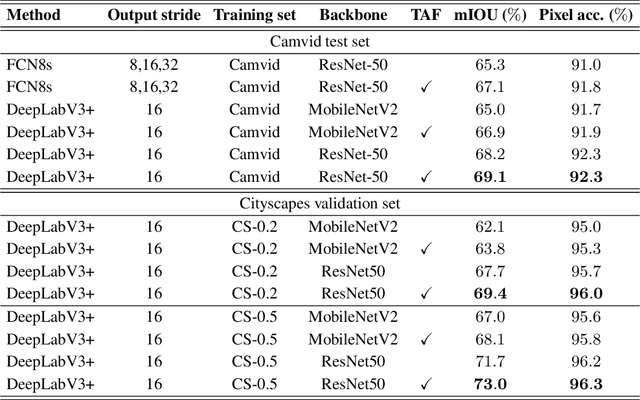
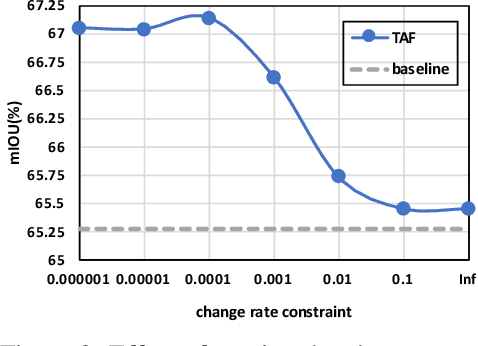
Partially annotated clips contain rich temporal contexts that can complement the sparse key frame annotations in providing supervision for model training. We present a novel paradigm called Temporally-Adaptive Features (TAF) learning that can utilize such data to learn better single frame models. By imposing distinct temporal change rate constraints on different factors in the model, TAF enables learning from unlabeled frames using context to enhance model accuracy. TAF generalizes "slow feature" learning and we present much stronger empirical evidence than prior works, showing convincing gains for the challenging semantic segmentation task over a variety of architecture designs and on two popular datasets. TAF can be interpreted as an implicit label augmentation method but is a more principled formulation compared to existing explicit augmentation techniques. Our work thus connects two promising methods that utilize partially annotated clips for single frame model training and can inspire future explorations in this direction.
Efficient Video Understanding via Layered Multi Frame-Rate Analysis
Nov 24, 2018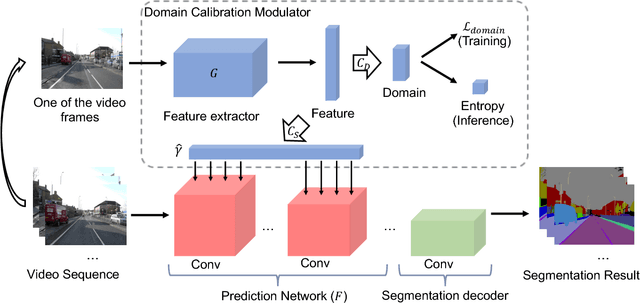
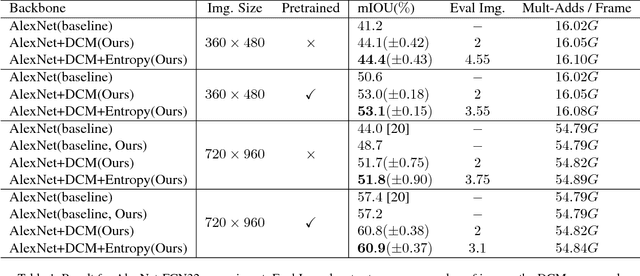
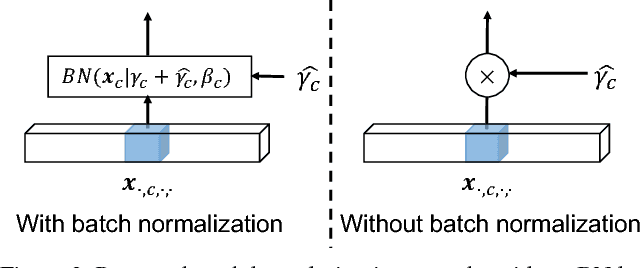
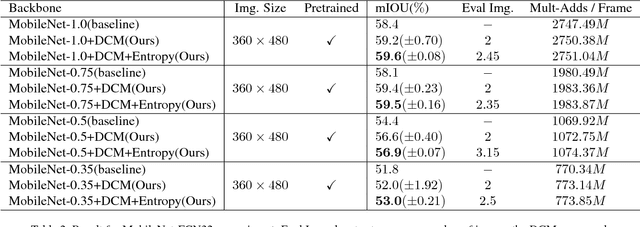
One of the greatest challenges in the design of a real-time perception system for autonomous driving vehicles and drones is the conflicting requirement of safety (high prediction accuracy) and efficiency. Traditional approaches use a single frame rate for the entire system. Motivated by the observation that the lack of robustness against environmental factors is the major weakness of compact ConvNet architectures, we propose a dual frame-rate system that brings in the best of both worlds: A modulator stream that executes an expensive models robust to environmental factors at a low frame rate to extract slowly changing features describing the environment, and a prediction stream that executes a light-weight model at real-time to extract transient signals that describes particularities of the current frame. The advantage of our design is validated by our extensive empirical study, showing that our solution leads to consistent improvements using a variety of backbone architecture choice and input resolutions. These findings suggest multiple frame-rate systems as a promising direction in designing efficient perception for autonomous agents.