 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Affinity Matching for Few-Shot Segmentation
Jul 17, 2023



Few-Shot Segmentation (FSS) aims to segment the novel class images with a few annotated samples. In this paper, we propose a dense affinity matching (DAM) framework to exploit the support-query interaction by densely capturing both the pixel-to-pixel and pixel-to-patch relations in each support-query pair with the bidirectional 3D convolutions. Different from the existing methods that remove the support background, we design a hysteretic spatial filtering module (HSFM) to filter the background-related query features and retain the foreground-related query features with the assistance of the support background, which is beneficial for eliminating interference objects in the query background. We comprehensively evaluate our DAM on ten benchmarks under cross-category, cross-dataset, and cross-domain FSS tasks. Experimental results demonstrate that DAM performs very competitively under different settings with only 0.68M parameters, especially under cross-domain FSS tasks, showing its effectiveness and efficiency.
Multi-Context Interaction Network for Few-Shot Segmentation
Mar 11, 2023



Few-Shot Segmentation (FSS) is challenging for limited support images and large intra-class appearance discrepancies. Due to the huge difference between support and query samples, most existing approaches focus on extracting high-level representations of the same layers for support-query correlations but neglect the shift issue between different layers and scales. In this paper, we propose a Multi-Context Interaction Network (MCINet) to remedy this issue by fully exploiting and interacting with the multi-scale contextual information contained in the support-query pairs. Specifically, MCINet improves FSS from the perspectives of boosting the query representations by incorporating the low-level structural information from another query branch into the high-level semantic features, enhancing the support-query correlations by exploiting both the same-layer and adjacent-layer features, and refining the predicted results by a multi-scale mask prediction strategy, with which the different scale contents have bidirectionally interacted. Experiments on two benchmarks demonstrate that our approach reaches SOTA performances and outperforms the best competitors with many desirable advantages, especially on the challenging COCO dataset.
Reducing Flipping Errors in Deep Neural Networks
Mar 16, 2022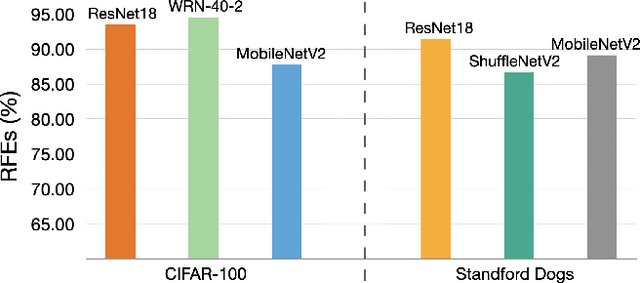
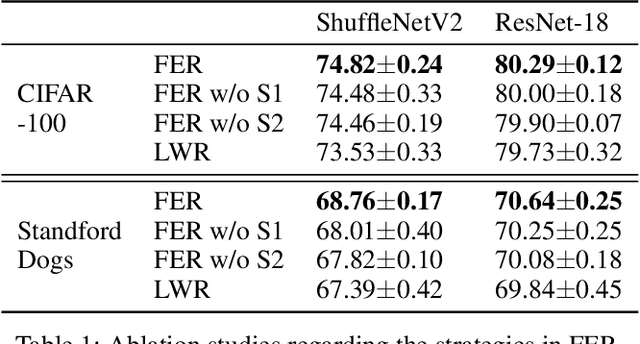
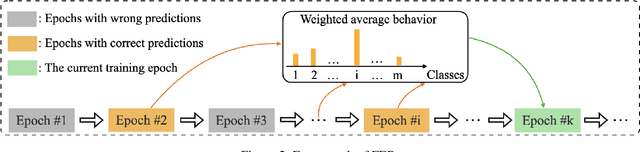
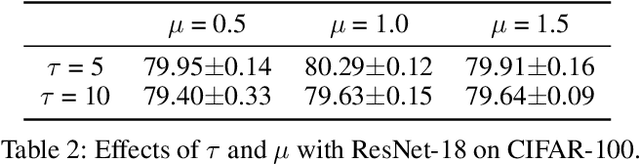
Deep neural networks (DNNs) have been widely applied in various domains in artificial intelligence including computer vision and natural language processing. A DNN is typically trained for many epochs and then a validation dataset is used to select the DNN in an epoch (we simply call this epoch "the last epoch") as the final model for making predictions on unseen samples, while it usually cannot achieve a perfect accuracy on unseen samples. An interesting question is "how many test (unseen) samples that a DNN misclassifies in the last epoch were ever correctly classified by the DNN before the last epoch?". In this paper, we empirically study this question and find on several benchmark datasets that the vast majority of the misclassified samples in the last epoch were ever classified correctly before the last epoch, which means that the predictions for these samples were flipped from "correct" to "wrong". Motivated by this observation, we propose to restrict the behavior changes of a DNN on the correctly-classified samples so that the correct local boundaries can be maintained and the flipping error on unseen samples can be largely reduced. Extensive experiments on different benchmark datasets with different modern network architectures demonstrate that the proposed flipping error reduction (FER) approach can substantially improve the generalization, the robustness, and the transferability of DNNs without introducing any additional network parameters or inference cost, only with a negligible training overhead.
Stable Prediction on Graphs with Agnostic Distribution Shift
Oct 08, 2021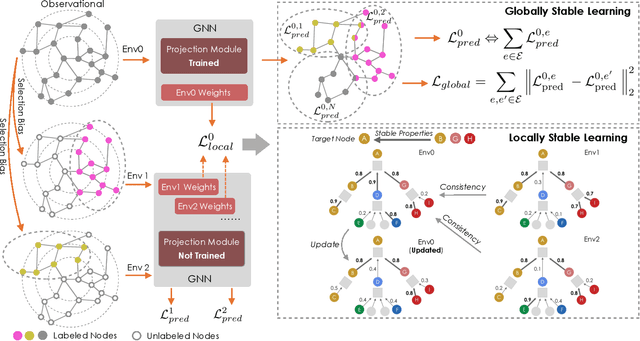
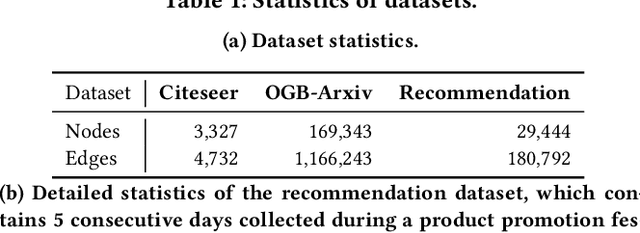
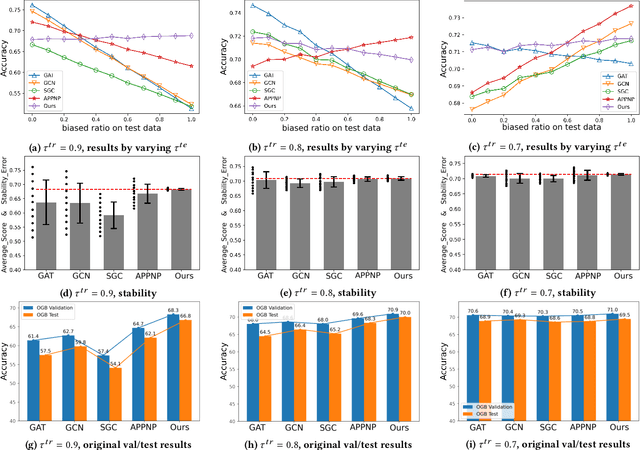
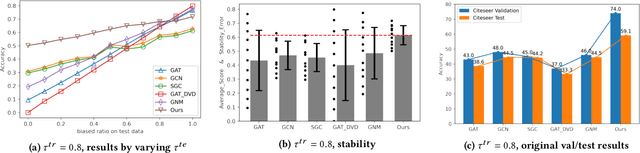
Graph is a flexible and effective tool to represent complex structures in practice and graph neural networks (GNNs) have been shown to be effective on various graph tasks with randomly separated training and testing data. In real applications, however, the distribution of training graph might be different from that of the test one (e.g., users' interactions on the user-item training graph and their actual preference on items, i.e., testing environment, are known to have inconsistencies in recommender systems). Moreover, the distribution of test data is always agnostic when GNNs are trained. Hence, we are facing the agnostic distribution shift between training and testing on graph learning, which would lead to unstable inference of traditional GNNs across different test environments. To address this problem, we propose a novel stable prediction framework for GNNs, which permits both locally and globally stable learning and prediction on graphs. In particular, since each node is partially represented by its neighbors in GNNs, we propose to capture the stable properties for each node (locally stable) by re-weighting the information propagation/aggregation processes. For global stability, we propose a stable regularizer that reduces the training losses on heterogeneous environments and thus warping the GNNs to generalize well. We conduct extensive experiments on several graph benchmarks and a noisy industrial recommendation dataset that is collected from 5 consecutive days during a product promotion festival. The results demonstrate that our method outperforms various SOTA GNNs for stable prediction on graphs with agnostic distribution shift, including shift caused by node labels and attributes.
Complementary Calibration: Boosting General Continual Learning with Collaborative Distillation and Self-Supervision
Sep 03, 2021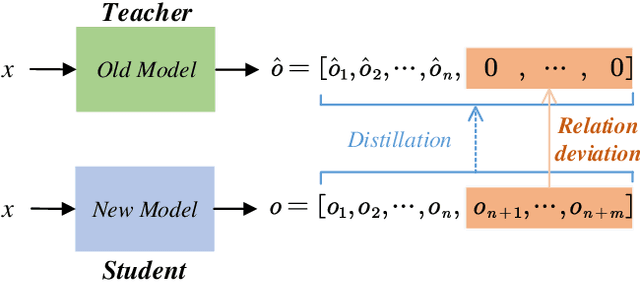
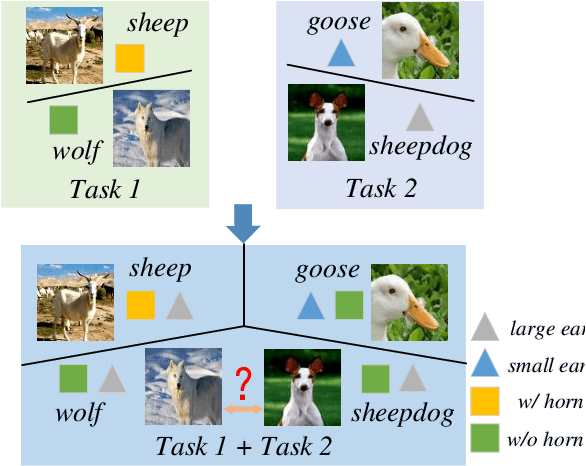
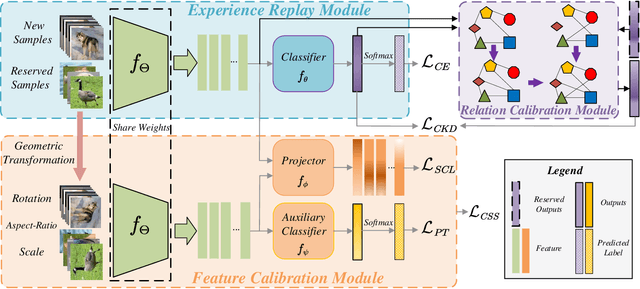
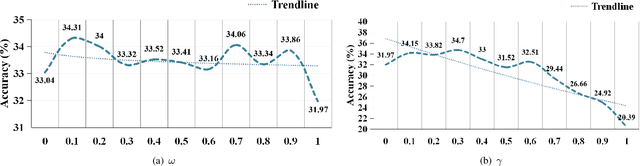
General Continual Learning (GCL) aims at learning from non independent and identically distributed stream data without catastrophic forgetting of the old tasks that don't rely on task boundaries during both training and testing stages. We reveal that the relation and feature deviations are crucial problems for catastrophic forgetting, in which relation deviation refers to the deficiency of the relationship among all classes in knowledge distillation, and feature deviation refers to indiscriminative feature representations. To this end, we propose a Complementary Calibration (CoCa) framework by mining the complementary model's outputs and features to alleviate the two deviations in the process of GCL. Specifically, we propose a new collaborative distillation approach for addressing the relation deviation. It distills model's outputs by utilizing ensemble dark knowledge of new model's outputs and reserved outputs, which maintains the performance of old tasks as well as balancing the relationship among all classes. Furthermore, we explore a collaborative self-supervision idea to leverage pretext tasks and supervised contrastive learning for addressing the feature deviation problem by learning complete and discriminative features for all classes. Extensive experiments on four popular datasets show that our CoCa framework achieves superior performance against state-of-the-art methods.
Self-Taught Cross-Domain Few-Shot Learning with Weakly Supervised Object Localization and Task-Decomposition
Sep 03, 2021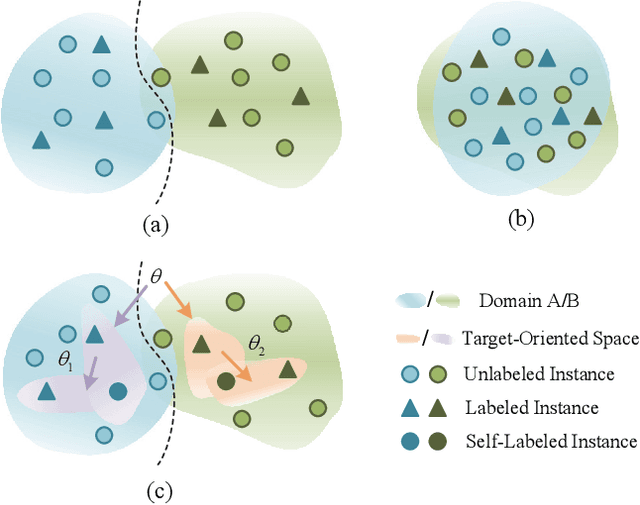

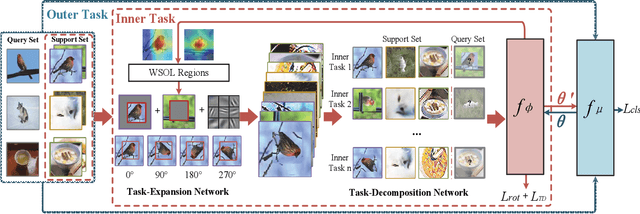
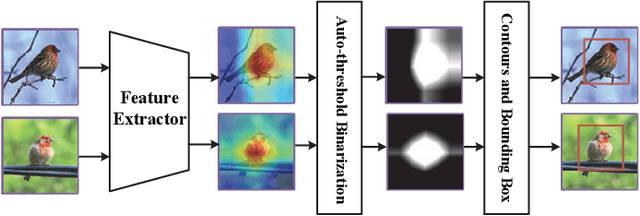
The domain shift between the source and target domain is the main challenge in Cross-Domain Few-Shot Learning (CD-FSL). However, the target domain is absolutely unknown during the training on the source domain, which results in lacking directed guidance for target tasks. We observe that since there are similar backgrounds in target domains, it can apply self-labeled samples as prior tasks to transfer knowledge onto target tasks. To this end, we propose a task-expansion-decomposition framework for CD-FSL, called Self-Taught (ST) approach, which alleviates the problem of non-target guidance by constructing task-oriented metric spaces. Specifically, Weakly Supervised Object Localization (WSOL) and self-supervised technologies are employed to enrich task-oriented samples by exchanging and rotating the discriminative regions, which generates a more abundant task set. Then these tasks are decomposed into several tasks to finish the task of few-shot recognition and rotation classification. It helps to transfer the source knowledge onto the target tasks and focus on discriminative regions. We conduct extensive experiments under the cross-domain setting including 8 target domains: CUB, Cars, Places, Plantae, CropDieases, EuroSAT, ISIC, and ChestX. Experimental results demonstrate that the proposed ST approach is applicable to various metric-based models, and provides promising improvements in CD-FSL.
Graph-Free Knowledge Distillation for Graph Neural Networks
May 16, 2021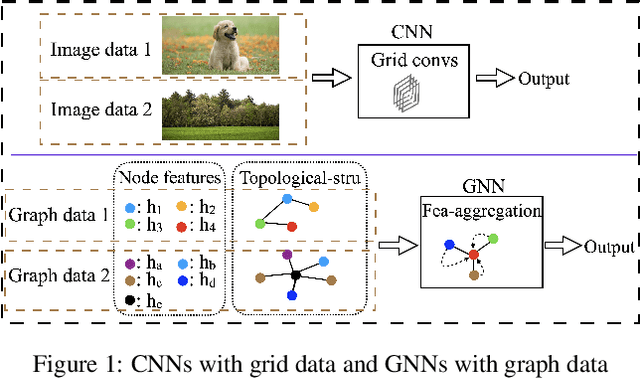
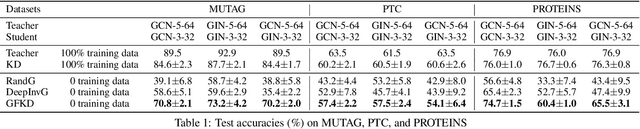
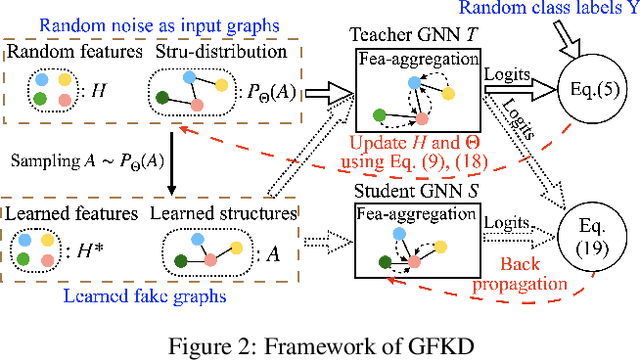

Knowledge distillation (KD) transfers knowledge from a teacher network to a student by enforcing the student to mimic the outputs of the pretrained teacher on training data. However, data samples are not always accessible in many cases due to large data sizes, privacy, or confidentiality. Many efforts have been made on addressing this problem for convolutional neural networks (CNNs) whose inputs lie in a grid domain within a continuous space such as images and videos, but largely overlook graph neural networks (GNNs) that handle non-grid data with different topology structures within a discrete space. The inherent differences between their inputs make these CNN-based approaches not applicable to GNNs. In this paper, we propose to our best knowledge the first dedicated approach to distilling knowledge from a GNN without graph data. The proposed graph-free KD (GFKD) learns graph topology structures for knowledge transfer by modeling them with multinomial distribution. We then introduce a gradient estimator to optimize this framework. Essentially, the gradients w.r.t. graph structures are obtained by only using GNN forward-propagation without back-propagation, which means that GFKD is compatible with modern GNN libraries such as DGL and Geometric. Moreover, we provide the strategies for handling different types of prior knowledge in the graph data or the GNNs. Extensive experiments demonstrate that GFKD achieves the state-of-the-art performance for distilling knowledge from GNNs without training data.
Learning with Retrospection
Dec 24, 2020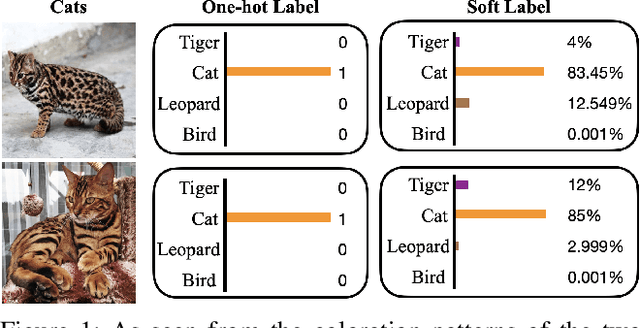
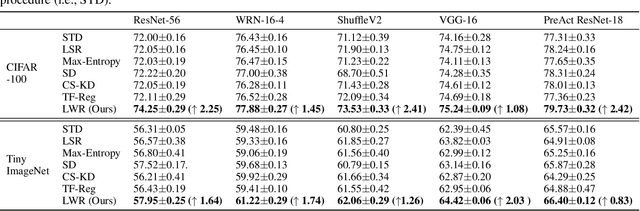
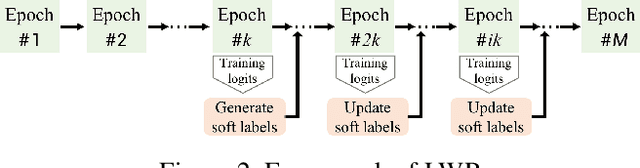
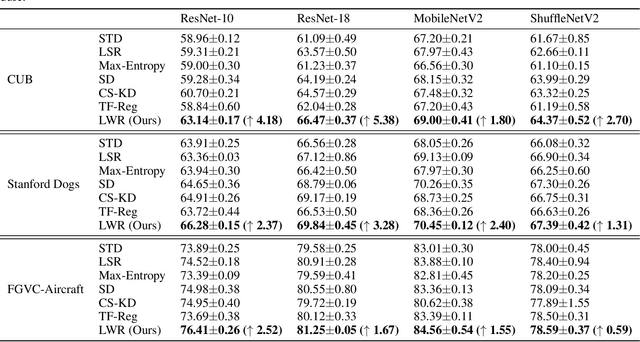
Deep neural networks have been successfully deployed in various domains of artificial intelligence, including computer vision and natural language processing. We observe that the current standard procedure for training DNNs discards all the learned information in the past epochs except the current learned weights. An interesting question is: is this discarded information indeed useless? We argue that the discarded information can benefit the subsequent training. In this paper, we propose learning with retrospection (LWR) which makes use of the learned information in the past epochs to guide the subsequent training. LWR is a simple yet effective training framework to improve accuracies, calibration, and robustness of DNNs without introducing any additional network parameters or inference cost, only with a negligible training overhead. Extensive experiments on several benchmark datasets demonstrate the superiority of LWR for training DNNs.
Full-Resolution Correspondence Learning for Image Translation
Dec 03, 2020
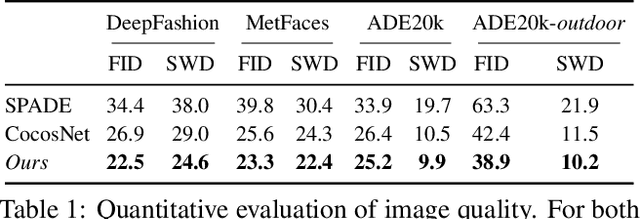
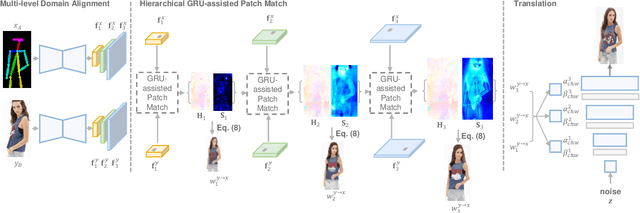
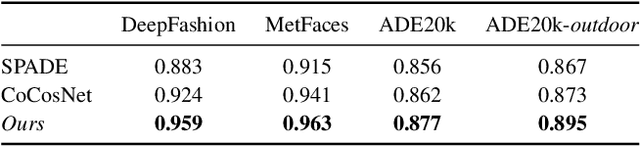
We present the full-resolution correspondence learning for cross-domain images, which aids image translation. We adopt a hierarchical strategy that uses the correspondence from coarse level to guide the finer levels. In each hierarchy, the correspondence can be efficiently computed via PatchMatch that iteratively leverages the matchings from the neighborhood. Within each PatchMatch iteration, the ConvGRU module is employed to refine the current correspondence considering not only the matchings of larger context but also the historic estimates. The proposed GRU-assisted PatchMatch is fully differentiable and highly efficient. When jointly trained with image translation, full-resolution semantic correspondence can be established in an unsupervised manner, which in turn facilitates the exemplar-based image translation. Experiments on diverse translation tasks show our approach performs considerably better than state-of-the-arts on producing high-resolution images.
Deep Metric Learning with Spherical Embedding
Nov 05, 2020

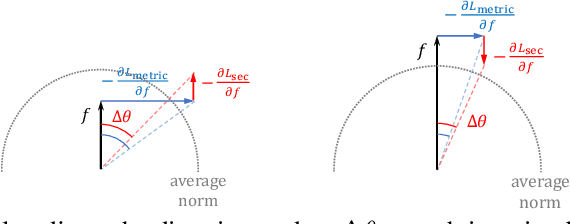
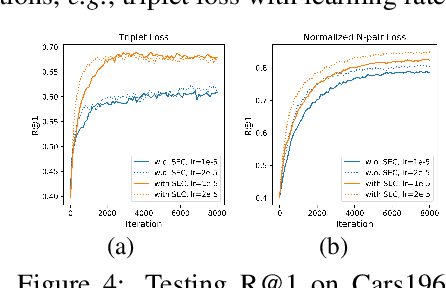
Deep metric learning has attracted much attention in recent years, due to seamlessly combining the distance metric learning and deep neural network. Many endeavors are devoted to design different pair-based angular loss functions, which decouple the magnitude and direction information for embedding vectors and ensure the training and testing measure consistency. However, these traditional angular losses cannot guarantee that all the sample embeddings are on the surface of the same hypersphere during the training stage, which would result in unstable gradient in batch optimization and may influence the quick convergence of the embedding learning. In this paper, we first investigate the effect of the embedding norm for deep metric learning with angular distance, and then propose a spherical embedding constraint (SEC) to regularize the distribution of the norms. SEC adaptively adjusts the embeddings to fall on the same hypersphere and performs more balanced direction update. Extensive experiments on deep metric learning, face recognition, and contrastive self-supervised learning show that the SEC-based angular space learning strategy significantly improves the performance of the state-of-the-art.