 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLNE-Blocking: An Efficient Framework for Contamination Mitigation Evaluation on Large Language Models
Sep 18, 2025The problem of data contamination is now almost inevitable during the development of large language models (LLMs), with the training data commonly integrating those evaluation benchmarks even unintentionally. This problem subsequently makes it hard to benchmark LLMs fairly. Instead of constructing contamination-free datasets (quite hard), we propose a novel framework, \textbf{LNE-Blocking}, to restore model performance prior to contamination on potentially leaked datasets. Our framework consists of two components: contamination detection and disruption operation. For the prompt, the framework first uses the contamination detection method, \textbf{LNE}, to assess the extent of contamination in the model. Based on this, it adjusts the intensity of the disruption operation, \textbf{Blocking}, to elicit non-memorized responses from the model. Our framework is the first to efficiently restore the model's greedy decoding performance. This comes with a strong performance on multiple datasets with potential leakage risks, and it consistently achieves stable recovery results across different models and varying levels of data contamination. We release the code at https://github.com/RuijieH/LNE-Blocking to facilitate research.
CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
May 17, 2024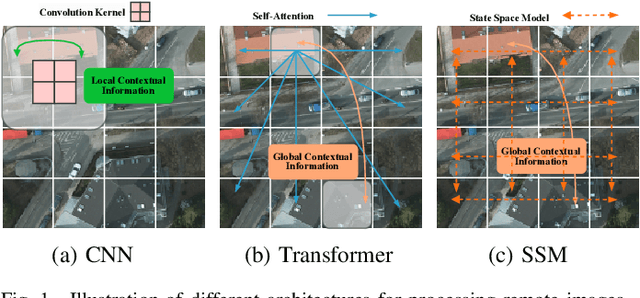
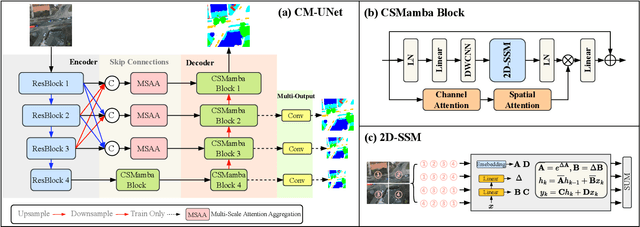
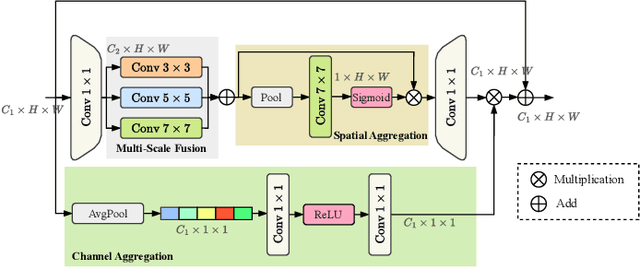
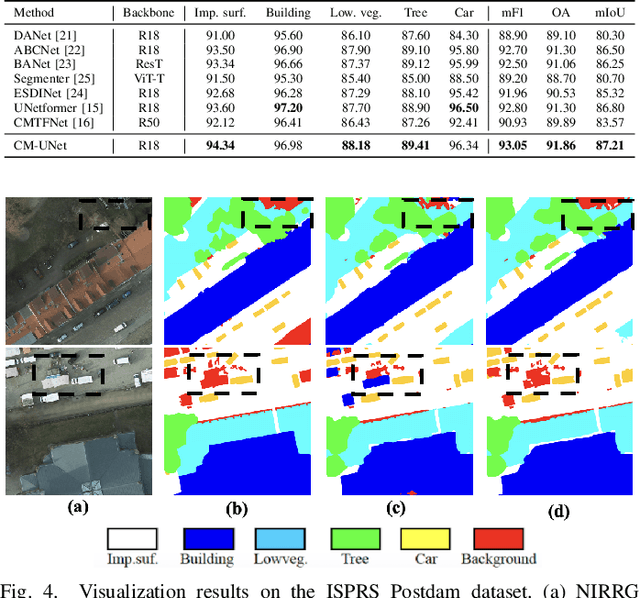
Due to the large-scale image size and object variations, current CNN-based and Transformer-based approaches for remote sensing image semantic segmentation are suboptimal for capturing the long-range dependency or limited to the complex computational complexity. In this paper, we propose CM-UNet, comprising a CNN-based encoder for extracting local image features and a Mamba-based decoder for aggregating and integrating global information, facilitating efficient semantic segmentation of remote sensing images. Specifically, a CSMamba block is introduced to build the core segmentation decoder, which employs channel and spatial attention as the gate activation condition of the vanilla Mamba to enhance the feature interaction and global-local information fusion. Moreover, to further refine the output features from the CNN encoder, a Multi-Scale Attention Aggregation (MSAA) module is employed to merge the different scale features. By integrating the CSMamba block and MSAA module, CM-UNet effectively captures the long-range dependencies and multi-scale global contextual information of large-scale remote-sensing images. Experimental results obtained on three benchmarks indicate that the proposed CM-UNet outperforms existing methods in various performance metrics. The codes are available at https://github.com/XiaoBuL/CM-UNet.
Enabling Collaborative Clinical Diagnosis of Infectious Keratitis by Integrating Expert Knowledge and Interpretable Data-driven Intelligence
Jan 14, 2024Although data-driven artificial intelligence (AI) in medical image diagnosis has shown impressive performance in silico, the lack of interpretability makes it difficult to incorporate the "black box" into clinicians' workflows. To make the diagnostic patterns learned from data understandable by clinicians, we develop an interpretable model, knowledge-guided diagnosis model (KGDM), that provides a visualized reasoning process containing AI-based biomarkers and retrieved cases that with the same diagnostic patterns. It embraces clinicians' prompts into the interpreted reasoning through human-AI interaction, leading to potentially enhanced safety and more accurate predictions. This study investigates the performance, interpretability, and clinical utility of KGDM in the diagnosis of infectious keratitis (IK), which is the leading cause of corneal blindness. The classification performance of KGDM is evaluated on a prospective validation dataset, an external testing dataset, and an publicly available testing dataset. The diagnostic odds ratios (DOR) of the interpreted AI-based biomarkers are effective, ranging from 3.011 to 35.233 and exhibit consistent diagnostic patterns with clinic experience. Moreover, a human-AI collaborative diagnosis test is conducted and the participants with collaboration achieved a performance exceeding that of both humans and AI. By synergistically integrating interpretability and interaction, this study facilitates the convergence of clinicians' expertise and data-driven intelligence. The promotion of inexperienced ophthalmologists with the aid of AI-based biomarkers, as well as increased AI prediction by intervention from experienced ones, demonstrate a promising diagnostic paradigm for infectious keratitis using KGDM, which holds the potential for extension to other diseases where experienced medical practitioners are limited and the safety of AI is concerned.
Dense Affinity Matching for Few-Shot Segmentation
Jul 17, 2023



Few-Shot Segmentation (FSS) aims to segment the novel class images with a few annotated samples. In this paper, we propose a dense affinity matching (DAM) framework to exploit the support-query interaction by densely capturing both the pixel-to-pixel and pixel-to-patch relations in each support-query pair with the bidirectional 3D convolutions. Different from the existing methods that remove the support background, we design a hysteretic spatial filtering module (HSFM) to filter the background-related query features and retain the foreground-related query features with the assistance of the support background, which is beneficial for eliminating interference objects in the query background. We comprehensively evaluate our DAM on ten benchmarks under cross-category, cross-dataset, and cross-domain FSS tasks. Experimental results demonstrate that DAM performs very competitively under different settings with only 0.68M parameters, especially under cross-domain FSS tasks, showing its effectiveness and efficiency.
Multi-Context Interaction Network for Few-Shot Segmentation
Mar 11, 2023



Few-Shot Segmentation (FSS) is challenging for limited support images and large intra-class appearance discrepancies. Due to the huge difference between support and query samples, most existing approaches focus on extracting high-level representations of the same layers for support-query correlations but neglect the shift issue between different layers and scales. In this paper, we propose a Multi-Context Interaction Network (MCINet) to remedy this issue by fully exploiting and interacting with the multi-scale contextual information contained in the support-query pairs. Specifically, MCINet improves FSS from the perspectives of boosting the query representations by incorporating the low-level structural information from another query branch into the high-level semantic features, enhancing the support-query correlations by exploiting both the same-layer and adjacent-layer features, and refining the predicted results by a multi-scale mask prediction strategy, with which the different scale contents have bidirectionally interacted. Experiments on two benchmarks demonstrate that our approach reaches SOTA performances and outperforms the best competitors with many desirable advantages, especially on the challenging COCO dataset.
Deep Metric Learning with Spherical Embedding
Nov 05, 2020

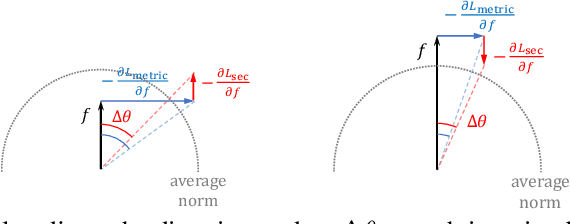
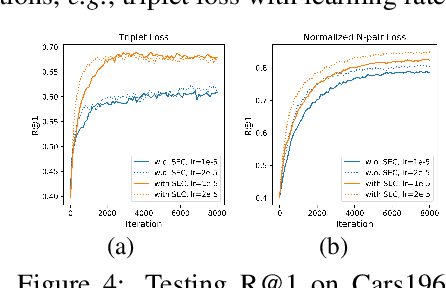
Deep metric learning has attracted much attention in recent years, due to seamlessly combining the distance metric learning and deep neural network. Many endeavors are devoted to design different pair-based angular loss functions, which decouple the magnitude and direction information for embedding vectors and ensure the training and testing measure consistency. However, these traditional angular losses cannot guarantee that all the sample embeddings are on the surface of the same hypersphere during the training stage, which would result in unstable gradient in batch optimization and may influence the quick convergence of the embedding learning. In this paper, we first investigate the effect of the embedding norm for deep metric learning with angular distance, and then propose a spherical embedding constraint (SEC) to regularize the distribution of the norms. SEC adaptively adjusts the embeddings to fall on the same hypersphere and performs more balanced direction update. Extensive experiments on deep metric learning, face recognition, and contrastive self-supervised learning show that the SEC-based angular space learning strategy significantly improves the performance of the state-of-the-art.
SBAT: Video Captioning with Sparse Boundary-Aware Transformer
Jul 23, 2020
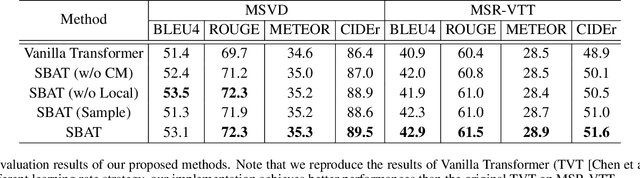
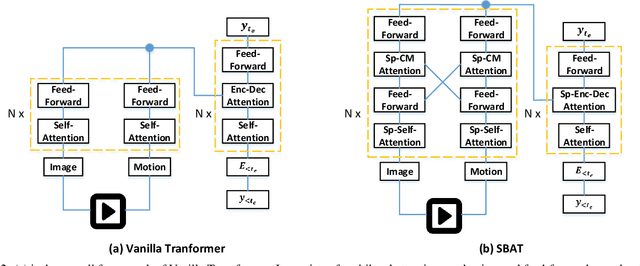
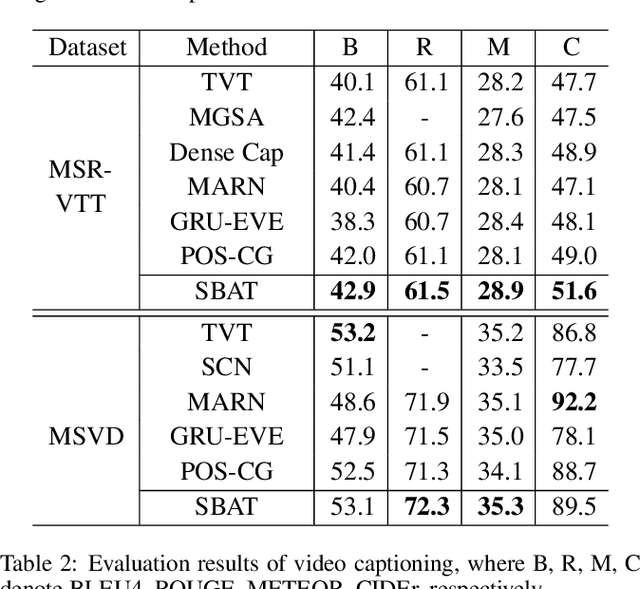
In this paper, we focus on the problem of applying the transformer structure to video captioning effectively. The vanilla transformer is proposed for uni-modal language generation task such as machine translation. However, video captioning is a multimodal learning problem, and the video features have much redundancy between different time steps. Based on these concerns, we propose a novel method called sparse boundary-aware transformer (SBAT) to reduce the redundancy in video representation. SBAT employs boundary-aware pooling operation for scores from multihead attention and selects diverse features from different scenarios. Also, SBAT includes a local correlation scheme to compensate for the local information loss brought by sparse operation. Based on SBAT, we further propose an aligned cross-modal encoding scheme to boost the multimodal interaction. Experimental results on two benchmark datasets show that SBAT outperforms the state-of-the-art methods under most of the metrics.
Low-Rank HOCA: Efficient High-Order Cross-Modal Attention for Video Captioning
Nov 01, 2019
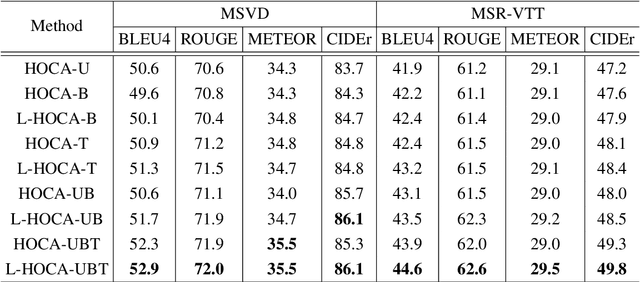

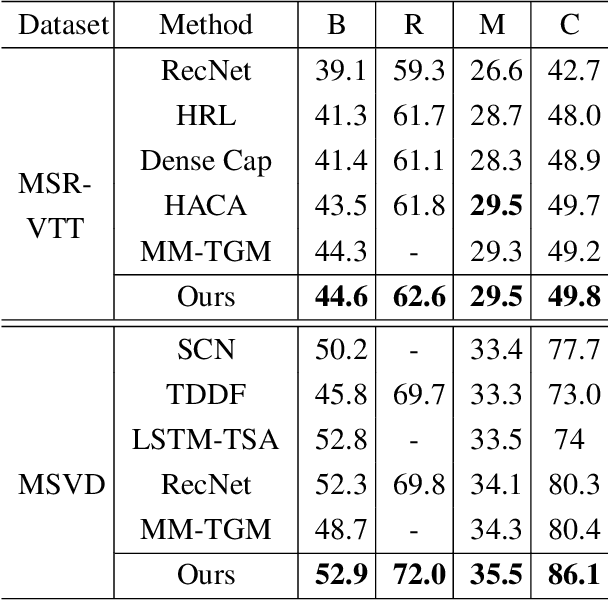
This paper addresses the challenging task of video captioning which aims to generate descriptions for video data. Recently, the attention-based encoder-decoder structures have been widely used in video captioning. In existing literature, the attention weights are often built from the information of an individual modality, while, the association relationships between multiple modalities are neglected. Motivated by this observation, we propose a video captioning model with High-Order Cross-Modal Attention (HOCA) where the attention weights are calculated based on the high-order correlation tensor to capture the frame-level cross-modal interaction of different modalities sufficiently. Furthermore, we novelly introduce Low-Rank HOCA which adopts tensor decomposition to reduce the extremely large space requirement of HOCA, leading to a practical and efficient implementation in real-world applications. Experimental results on two benchmark datasets, MSVD and MSR-VTT, show that Low-rank HOCA establishes a new state-of-the-art.
Text Guided Person Image Synthesis
Apr 10, 2019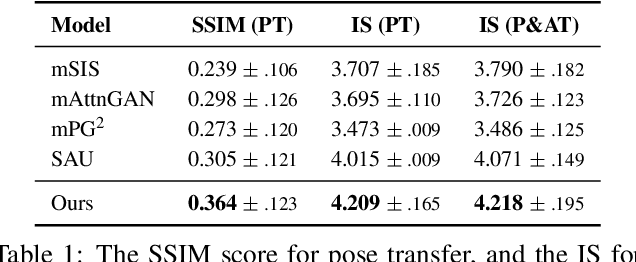
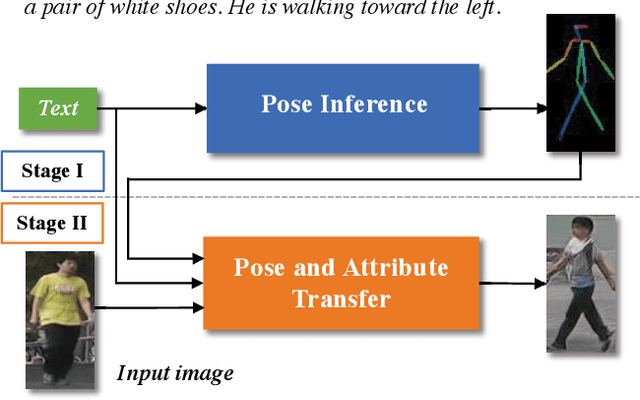
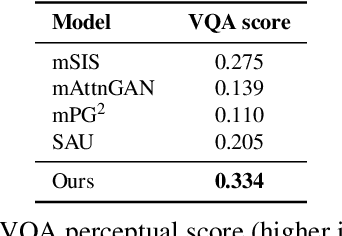
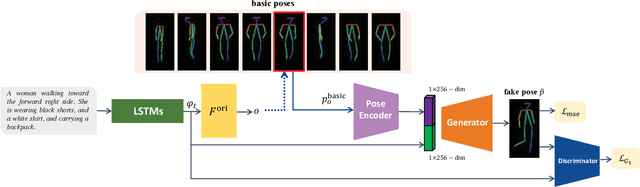
This paper presents a novel method to manipulate the visual appearance (pose and attribute) of a person image according to natural language descriptions. Our method can be boiled down to two stages: 1) text guided pose generation and 2) visual appearance transferred image synthesis. In the first stage, our method infers a reasonable target human pose based on the text. In the second stage, our method synthesizes a realistic and appearance transferred person image according to the text in conjunction with the target pose. Our method extracts sufficient information from the text and establishes a mapping between the image space and the language space, making generating and editing images corresponding to the description possible. We conduct extensive experiments to reveal the effectiveness of our method, as well as using the VQA Perceptual Score as a metric for evaluating the method. It shows for the first time that we can automatically edit the person image from the natural language descriptions.
A Survey of Multi-View Representation Learning
Oct 24, 2018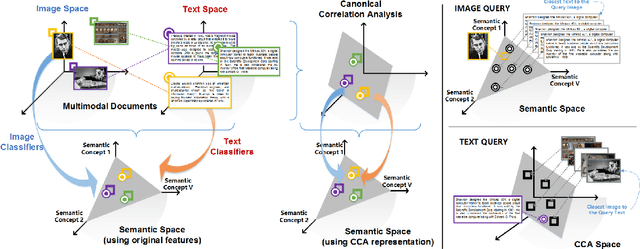


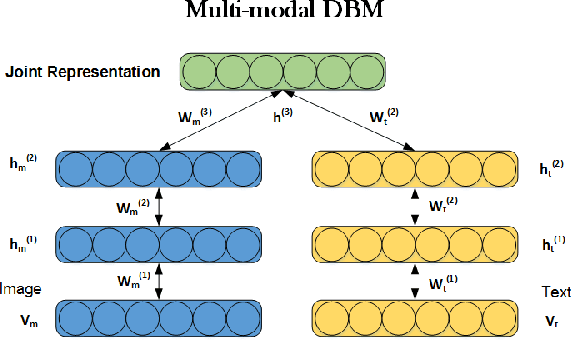
Recently, multi-view representation learning has become a rapidly growing direction in machine learning and data mining areas. This paper introduces two categories for multi-view representation learning: multi-view representation alignment and multi-view representation fusion. Consequently, we first review the representative methods and theories of multi-view representation learning based on the perspective of alignment, such as correlation-based alignment. Representative examples are canonical correlation analysis (CCA) and its several extensions. Then from the perspective of representation fusion we investigate the advancement of multi-view representation learning that ranges from generative methods including multi-modal topic learning, multi-view sparse coding, and multi-view latent space Markov networks, to neural network-based methods including multi-modal autoencoders, multi-view convolutional neural networks, and multi-modal recurrent neural networks. Further, we also investigate several important applications of multi-view representation learning. Overall, this survey aims to provide an insightful overview of theoretical foundation and state-of-the-art developments in the field of multi-view representation learning and to help researchers find the most appropriate tools for particular applications.