 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-wise Modality Specialization within MLLMs for Robust Fake News Detection under Missing Modality
Apr 08, 2026Multimodal fake news detection (MFND) aims to verify news credibility by jointly exploiting textual and visual evidence. However, real-world news dissemination frequently suffers from missing modality due to deleted images, corrupted screenshots, and similar issues. Thus, robust detection in this scenario requires preserving strong verification ability for each modality, which is challenging in MFND due to insufficient learning of the low-contribution modality and scarce unimodal annotations. To address this issue, we propose Head-wise Modality Specialization within Multimodal Large Language Models (MLLMs) for robust MFND under missing modality. Specifically, we first systematically study attention heads in MLLMs and their relationship with performance under missing modality, showing that modality-critical heads serve as key carriers of unimodal verification ability through their modality specialization. Based on this observation, to better preserve verification ability for the low-contribution modality, we introduce a head-wise specialization mechanism that explicitly allocates these heads to different modalities and preserves their specialization through lower-bound attention constraints. Furthermore, to better exploit scarce unimodal annotations, we propose a Unimodal Knowledge Retention strategy that prevents these heads from drifting away from the unimodal knowledge learned from limited supervision. Experiments show that our method improves robustness under missing modality while preserving performance with full multimodal input.
Exact Minimum-Volume Confidence Set Intersection for Multinomial Outcomes
Jan 26, 2026Computation of confidence sets is central to data science and machine learning, serving as the workhorse of A/B testing and underpinning the operation and analysis of reinforcement learning algorithms. Among all valid confidence sets for the multinomial parameter, minimum-volume confidence sets (MVCs) are optimal in that they minimize average volume, but they are defined as level sets of an exact p-value that is discontinuous and difficult to compute. Rather than attempting to characterize the geometry of MVCs directly, this paper studies a practically motivated decision problem: given two observed multinomial outcomes, can one certify whether their MVCs intersect? We present a certified, tolerance-aware algorithm for this intersection problem. The method exploits the fact that likelihood ordering induces halfspace constraints in log-odds coordinates, enabling adaptive geometric partitioning of parameter space and computable lower and upper bounds on p-values over each cell. For three categories, this yields an efficient and provably sound algorithm that either certifies intersection, certifies disjointness, or returns an indeterminate result when the decision lies within a prescribed margin. We further show how the approach extends to higher dimensions. The results demonstrate that, despite their irregular geometry, MVCs admit reliable certified decision procedures for core tasks in A/B testing.
DanceEditor: Towards Iterative Editable Music-driven Dance Generation with Open-Vocabulary Descriptions
Aug 24, 2025



Generating coherent and diverse human dances from music signals has gained tremendous progress in animating virtual avatars. While existing methods support direct dance synthesis, they fail to recognize that enabling users to edit dance movements is far more practical in real-world choreography scenarios. Moreover, the lack of high-quality dance datasets incorporating iterative editing also limits addressing this challenge. To achieve this goal, we first construct DanceRemix, a large-scale multi-turn editable dance dataset comprising the prompt featuring over 25.3M dance frames and 84.5K pairs. In addition, we propose a novel framework for iterative and editable dance generation coherently aligned with given music signals, namely DanceEditor. Considering the dance motion should be both musical rhythmic and enable iterative editing by user descriptions, our framework is built upon a prediction-then-editing paradigm unifying multi-modal conditions. At the initial prediction stage, our framework improves the authority of generated results by directly modeling dance movements from tailored, aligned music. Moreover, at the subsequent iterative editing stages, we incorporate text descriptions as conditioning information to draw the editable results through a specifically designed Cross-modality Editing Module (CEM). Specifically, CEM adaptively integrates the initial prediction with music and text prompts as temporal motion cues to guide the synthesized sequences. Thereby, the results display music harmonics while preserving fine-grained semantic alignment with text descriptions. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected DanceRemix dataset. Code is available at https://lzvsdy.github.io/DanceEditor/.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
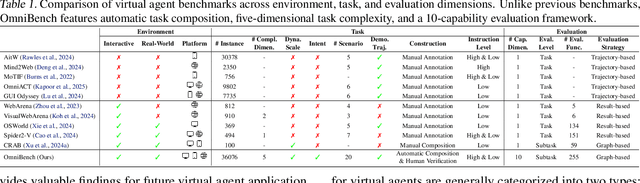

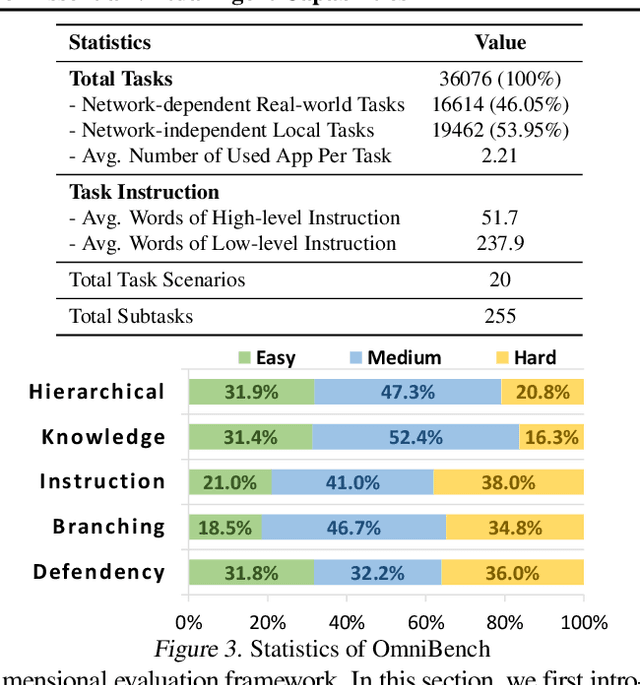
As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
LegalReasoner: Step-wised Verification-Correction for Legal Judgment Reasoning
Jun 09, 2025Legal judgment prediction (LJP) aims to function as a judge by making final rulings based on case claims and facts, which plays a vital role in the judicial domain for supporting court decision-making and improving judicial efficiency. However, existing methods often struggle with logical errors when conducting complex legal reasoning. We propose LegalReasoner, which enhances LJP reliability through step-wise verification and correction of the reasoning process. Specifically, it first identifies dispute points to decompose complex cases, and then conducts step-wise reasoning while employing a process verifier to validate each step's logic from correctness, progressiveness, and potential perspectives. When errors are detected, expert-designed attribution and resolution strategies are applied for correction. To fine-tune LegalReasoner, we release the LegalHK dataset, containing 58,130 Hong Kong court cases with detailed annotations of dispute points, step-by-step reasoning chains, and process verification labels. Experiments demonstrate that LegalReasoner significantly improves concordance with court decisions from 72.37 to 80.27 on LLAMA-3.1-70B. The data is available at https://huggingface.co/datasets/weijiezz/LegalHK.
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
May 26, 2025Large language models (LLMs) are revolutionizing education, with LLM-based agents playing a key role in simulating student behavior. A major challenge in student simulation is modeling the diverse learning patterns of students at various cognitive levels. However, current LLMs, typically trained as ``helpful assistants'', target at generating perfect responses. As a result, they struggle to simulate students with diverse cognitive abilities, as they often produce overly advanced answers, missing the natural imperfections that characterize student learning and resulting in unrealistic simulations. To address this issue, we propose a training-free framework for student simulation. We begin by constructing a cognitive prototype for each student using a knowledge graph, which captures their understanding of concepts from past learning records. This prototype is then mapped to new tasks to predict student performance. Next, we simulate student solutions based on these predictions and iteratively refine them using a beam search method to better replicate realistic mistakes. To validate our approach, we construct the \texttt{Student\_100} dataset, consisting of $100$ students working on Python programming and $5,000$ learning records. Experimental results show that our method consistently outperforms baseline models, achieving $100\%$ improvement in simulation accuracy.
Adaptation Method for Misinformation Identification
Apr 19, 2025



Multimodal fake news detection plays a crucial role in combating online misinformation. Unfortunately, effective detection methods rely on annotated labels and encounter significant performance degradation when domain shifts exist between training (source) and test (target) data. To address the problems, we propose ADOSE, an Active Domain Adaptation (ADA) framework for multimodal fake news detection which actively annotates a small subset of target samples to improve detection performance. To identify various deceptive patterns in cross-domain settings, we design multiple expert classifiers to learn dependencies across different modalities. These classifiers specifically target the distinct deception patterns exhibited in fake news, where two unimodal classifiers capture knowledge errors within individual modalities while one cross-modal classifier identifies semantic inconsistencies between text and images. To reduce annotation costs from the target domain, we propose a least-disagree uncertainty selector with a diversity calculator for selecting the most informative samples. The selector leverages prediction disagreement before and after perturbations by multiple classifiers as an indicator of uncertain samples, whose deceptive patterns deviate most from source domains. It further incorporates diversity scores derived from multi-view features to ensure the chosen samples achieve maximal coverage of target domain features. The extensive experiments on multiple datasets show that ADOSE outperforms existing ADA methods by 2.72\% $\sim$ 14.02\%, indicating the superiority of our model.
PRISM-0: A Predicate-Rich Scene Graph Generation Framework for Zero-Shot Open-Vocabulary Tasks
Apr 01, 2025In Scene Graphs Generation (SGG) one extracts structured representation from visual inputs in the form of objects nodes and predicates connecting them. This facilitates image-based understanding and reasoning for various downstream tasks. Although fully supervised SGG approaches showed steady performance improvements, they suffer from a severe training bias. This is caused by the availability of only small subsets of curated data and exhibits long-tail predicate distribution issues with a lack of predicate diversity adversely affecting downstream tasks. To overcome this, we introduce PRISM-0, a framework for zero-shot open-vocabulary SGG that bootstraps foundation models in a bottom-up approach to capture the whole spectrum of diverse, open-vocabulary predicate prediction. Detected object pairs are filtered and passed to a Vision Language Model (VLM) that generates descriptive captions. These are used to prompt an LLM to generate fine-andcoarse-grained predicates for the pair. The predicates are then validated using a VQA model to provide a final SGG. With the modular and dataset-independent PRISM-0, we can enrich existing SG datasets such as Visual Genome (VG). Experiments illustrate that PRIMS-0 generates semantically meaningful graphs that improve downstream tasks such as Image Captioning and Sentence-to-Graph Retrieval with a performance on par to the best fully supervised methods.
Argumentation Computation with Large Language Models : A Benchmark Study
Dec 21, 2024



In recent years, large language models (LLMs) have made significant advancements in neuro-symbolic computing. However, the combination of LLM with argumentation computation remains an underexplored domain, despite its considerable potential for real-world applications requiring defeasible reasoning. In this paper, we aim to investigate the capability of LLMs in determining the extensions of various abstract argumentation semantics. To achieve this, we develop and curate a benchmark comprising diverse abstract argumentation frameworks, accompanied by detailed explanations of algorithms for computing extensions. Subsequently, we fine-tune LLMs on the proposed benchmark, focusing on two fundamental extension-solving tasks. As a comparative baseline, LLMs are evaluated using a chain-of-thought approach, where they struggle to accurately compute semantics. In the experiments, we demonstrate that the process explanation plays a crucial role in semantics computation learning. Models trained with explanations show superior generalization accuracy compared to those trained solely with question-answer pairs. Furthermore, by leveraging the self-explanation capabilities of LLMs, our approach provides detailed illustrations that mitigate the lack of transparency typically associated with neural networks. Our findings contribute to the broader understanding of LLMs' potential in argumentation computation, offering promising avenues for further research in this domain.
Semantic Alignment for Multimodal Large Language Models
Aug 23, 2024



Research on Multi-modal Large Language Models (MLLMs) towards the multi-image cross-modal instruction has received increasing attention and made significant progress, particularly in scenarios involving closely resembling images (e.g., change captioning). Existing MLLMs typically follow a two-step process in their pipelines: first, extracting visual tokens independently for each input image, and then aligning these visual tokens from different images with the Large Language Model (LLM) in its textual feature space. However, the independent extraction of visual tokens for each image may result in different semantics being prioritized for different images in the first step, leading to a lack of preservation of linking information among images for subsequent LLM analysis. This issue becomes more serious in scenarios where significant variations exist among the images (e.g., visual storytelling). To address this challenge, we introduce Semantic Alignment for Multi-modal large language models (SAM). By involving the bidirectional semantic guidance between different images in the visual-token extraction process, SAM aims to enhance the preservation of linking information for coherent analysis and align the semantics of different images before feeding them into LLM. As the test bed, we propose a large-scale dataset named MmLINK consisting of 69K samples. Different from most existing datasets for MLLMs fine-tuning, our MmLINK dataset comprises multi-modal instructions with significantly diverse images. Extensive experiments on the group captioning task and the storytelling task prove the effectiveness of our SAM model, surpassing the state-of-the-art methods by a large margin (+37% for group captioning and +22% for storytelling on CIDEr score). Project page: https://mccartney01.github.io/SAM.