 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Adapt: Self-Improving Web Agent via Cognitive-Aware Exploration
May 29, 2026Recent advances in Multimodal Large Language Models (MLLMs) have led to promising progress in web agents. However, existing web agents often rely on handcrafted execution pipelines or expensive expert trajectories, limiting their adaptability to complex, dynamic environments. To address these challenges, we propose SCALE (Self-Cognitive-Aware Learning and Exploration), which leverages three adversarial roles, Selector, Predictor, and Judger to autonomously discover the agent's limitations and expand its cognitive boundaries through environmental exploration. Moreover, we propose SCALE-Hop, a graph exploration strategy that facilitates global planning and helps agents avoid local exploration traps. To further support learning, we construct SCALE-20k, a large-scale dataset collected from 19 real-world websites, containing diverse task types and structured demonstrations generated from SCALE's exploration traces. Experimental results show that our approach significantly improves the performance and generalization of multiple MLLMs in various web environments. Our framework offers a scalable and generalizable solution for building truly autonomous and adaptive web agents.
SPARKLING: Balancing Signal Preservation and Symmetry Breaking for Width-Progressive Learning
Feb 02, 2026Progressive Learning (PL) reduces pre-training computational overhead by gradually increasing model scale. While prior work has extensively explored depth expansion, width expansion remains significantly understudied, with the few existing methods limited to the early stages of training. However, expanding width during the mid-stage is essential for maximizing computational savings, yet it remains a formidable challenge due to severe training instabilities. Empirically, we show that naive initialization at this stage disrupts activation statistics, triggering loss spikes, while copy-based initialization introduces gradient symmetry that hinders feature diversity. To address these issues, we propose SPARKLING (balancing {S}ignal {P}reservation {A}nd symmet{R}y brea{K}ing for width-progressive {L}earn{ING}), a novel framework for mid-stage width expansion. Our method achieves signal preservation via RMS-scale consistency, stabilizing activation statistics during expansion. Symmetry breaking is ensured through asymmetric optimizer state resetting and learning rate re-warmup. Extensive experiments on Mixture-of-Experts (MoE) models demonstrate that, across multiple width axes and optimizer families, SPARKLING consistently outperforms training from scratch and reduces training cost by up to 35% under $2\times$ width expansion.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
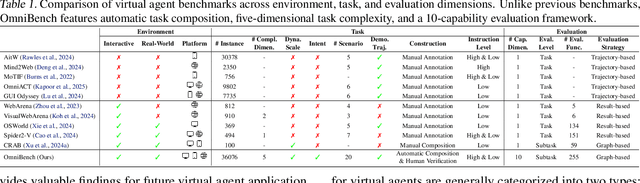

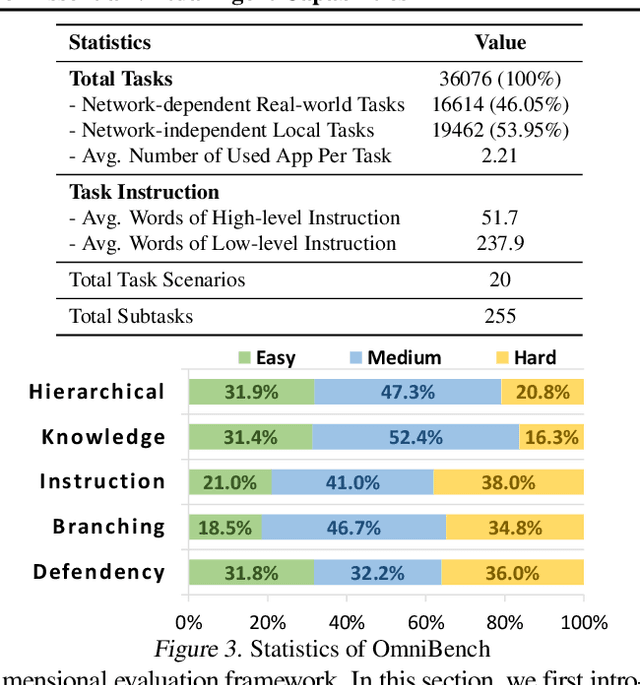
As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Mar 24, 2025The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.
SOYO: A Tuning-Free Approach for Video Style Morphing via Style-Adaptive Interpolation in Diffusion Models
Mar 10, 2025Diffusion models have achieved remarkable progress in image and video stylization. However, most existing methods focus on single-style transfer, while video stylization involving multiple styles necessitates seamless transitions between them. We refer to this smooth style transition between video frames as video style morphing. Current approaches often generate stylized video frames with discontinuous structures and abrupt style changes when handling such transitions. To address these limitations, we introduce SOYO, a novel diffusion-based framework for video style morphing. Our method employs a pre-trained text-to-image diffusion model without fine-tuning, combining attention injection and AdaIN to preserve structural consistency and enable smooth style transitions across video frames. Moreover, we notice that applying linear equidistant interpolation directly induces imbalanced style morphing. To harmonize across video frames, we propose a novel adaptive sampling scheduler operating between two style images. Extensive experiments demonstrate that SOYO outperforms existing methods in open-domain video style morphing, better preserving the structural coherence of video frames while achieving stable and smooth style transitions.
Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning
Feb 12, 2025



Chain-of-Thought (CoT) prompting has emerged as a powerful technique for enhancing language model's reasoning capabilities. However, generating long and correct CoT trajectories is challenging. Recent studies have demonstrated that Looped Transformers possess remarkable length generalization capabilities, but their limited generality and adaptability prevent them from serving as an alternative to auto-regressive solutions. To better leverage the strengths of Looped Transformers, we propose RELAY (REasoning through Loop Alignment iterativelY). Specifically, we align the steps of Chain-of-Thought (CoT) reasoning with loop iterations and apply intermediate supervision during the training of Looped Transformers. This additional iteration-wise supervision not only preserves the Looped Transformer's ability for length generalization but also enables it to predict CoT reasoning steps for unseen data. Therefore, we leverage this Looped Transformer to generate accurate reasoning chains for complex problems that exceed the training length, which will then be used to fine-tune an auto-regressive model. We conduct extensive experiments, and the results demonstrate the effectiveness of our approach, with significant improvements in the performance of the auto-regressive model. Code will be released at https://github.com/qifanyu/RELAY.
Mastering Collaborative Multi-modal Data Selection: A Focus on Informativeness, Uniqueness, and Representativeness
Dec 09, 2024



Instruction tuning fine-tunes pre-trained Multi-modal Large Language Models (MLLMs) to handle real-world tasks. However, the rapid expansion of visual instruction datasets introduces data redundancy, leading to excessive computational costs. We propose a collaborative framework, DataTailor, which leverages three key principles--informativeness, uniqueness, and representativeness--for effective data selection. We argue that a valuable sample should be informative of the task, non-redundant, and represent the sample distribution (i.e., not an outlier). We further propose practical ways to score against each principle, which automatically adapts to a given dataset without tedious hyperparameter tuning. Comprehensive experiments on various benchmarks demonstrate that DataTailor achieves 100.8% of the performance of full-data fine-tuning with only 15% of the data, significantly reducing computational costs while maintaining superior results. This exemplifies the "Less is More" philosophy in MLLM development.
STEP: Enhancing Video-LLMs' Compositional Reasoning by Spatio-Temporal Graph-guided Self-Training
Nov 29, 2024Video Large Language Models (Video-LLMs) have recently shown strong performance in basic video understanding tasks, such as captioning and coarse-grained question answering, but struggle with compositional reasoning that requires multi-step spatio-temporal inference across object relations, interactions, and events. The hurdles to enhancing this capability include extensive manual labor, the lack of spatio-temporal compositionality in existing data and the absence of explicit reasoning supervision. In this paper, we propose STEP, a novel graph-guided self-training method that enables Video-LLMs to generate reasoning-rich fine-tuning data from any raw videos to improve itself. Specifically, we first induce Spatio-Temporal Scene Graph (STSG) representation of diverse videos to capture fine-grained, multi-granular video semantics. Then, the STSGs guide the derivation of multi-step reasoning Question-Answer (QA) data with Chain-of-Thought (CoT) rationales. Both answers and rationales are integrated as training objective, aiming to enhance model's reasoning abilities by supervision over explicit reasoning steps. Experimental results demonstrate the effectiveness of STEP across models of varying scales, with a significant 21.3\% improvement in tasks requiring three or more reasoning steps. Furthermore, it achieves superior performance with a minimal amount of self-generated rationale-enriched training samples in both compositional reasoning and comprehensive understanding benchmarks, highlighting the broad applicability and vast potential.
AnyEdit: Mastering Unified High-Quality Image Editing for Any Idea
Nov 24, 2024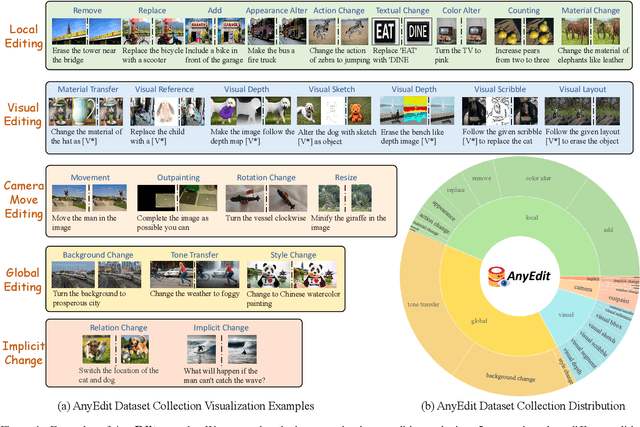



Instruction-based image editing aims to modify specific image elements with natural language instructions. However, current models in this domain often struggle to accurately execute complex user instructions, as they are trained on low-quality data with limited editing types. We present AnyEdit, a comprehensive multi-modal instruction editing dataset, comprising 2.5 million high-quality editing pairs spanning over 20 editing types and five domains. We ensure the diversity and quality of the AnyEdit collection through three aspects: initial data diversity, adaptive editing process, and automated selection of editing results. Using the dataset, we further train a novel AnyEdit Stable Diffusion with task-aware routing and learnable task embedding for unified image editing. Comprehensive experiments on three benchmark datasets show that AnyEdit consistently boosts the performance of diffusion-based editing models. This presents prospects for developing instruction-driven image editing models that support human creativity.
Unified Generative and Discriminative Training for Multi-modal Large Language Models
Nov 01, 2024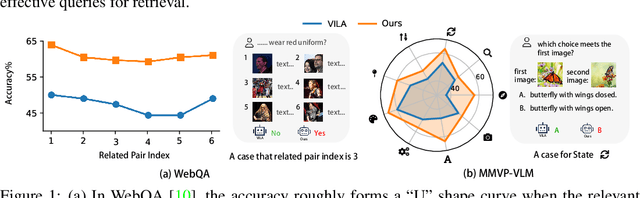
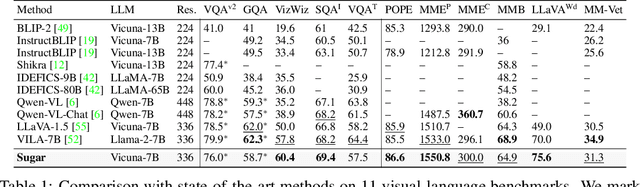
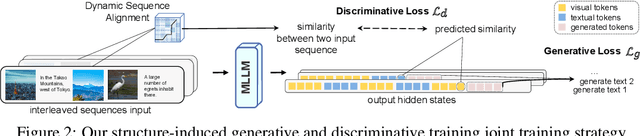
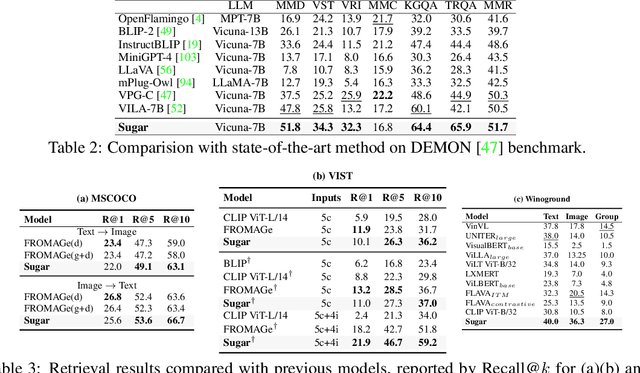
In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM's hidden state. This approach enhances the MLLM's ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.