 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyEdit: Mastering Unified High-Quality Image Editing for Any Idea
Paper and Code
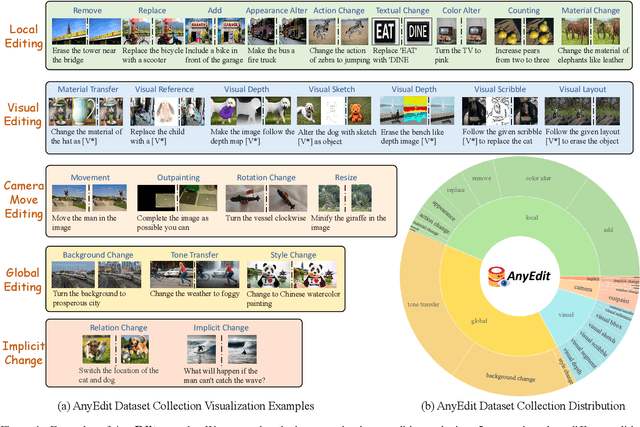



Instruction-based image editing aims to modify specific image elements with natural language instructions. However, current models in this domain often struggle to accurately execute complex user instructions, as they are trained on low-quality data with limited editing types. We present AnyEdit, a comprehensive multi-modal instruction editing dataset, comprising 2.5 million high-quality editing pairs spanning over 20 editing types and five domains. We ensure the diversity and quality of the AnyEdit collection through three aspects: initial data diversity, adaptive editing process, and automated selection of editing results. Using the dataset, we further train a novel AnyEdit Stable Diffusion with task-aware routing and learnable task embedding for unified image editing. Comprehensive experiments on three benchmark datasets show that AnyEdit consistently boosts the performance of diffusion-based editing models. This presents prospects for developing instruction-driven image editing models that support human creativity.