 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Nov 14, 2025
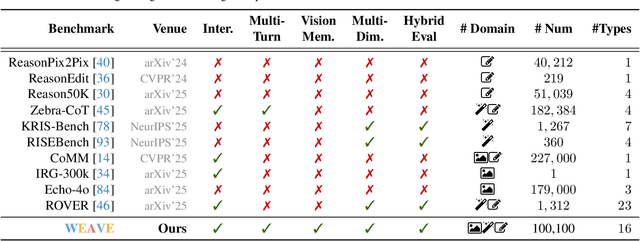
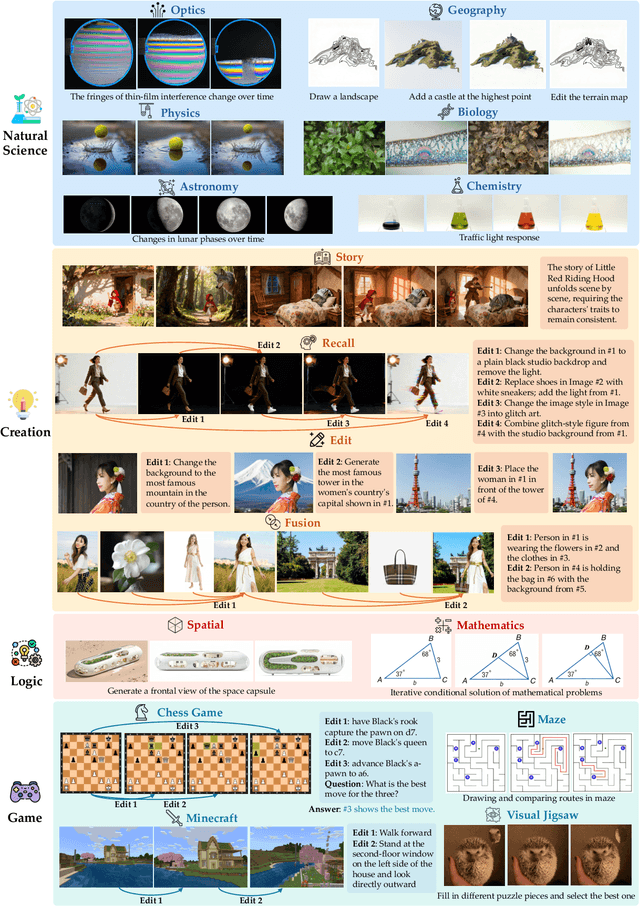

Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025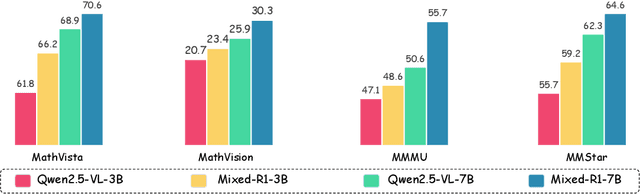
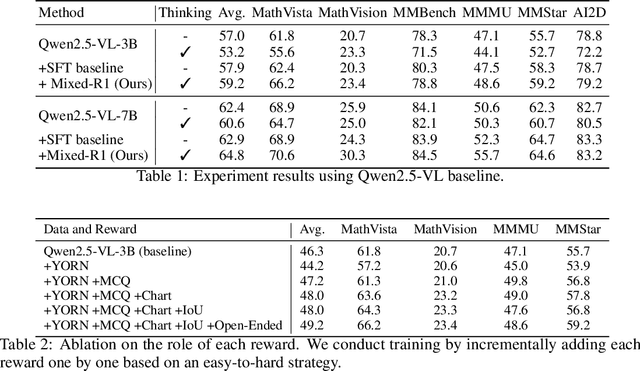
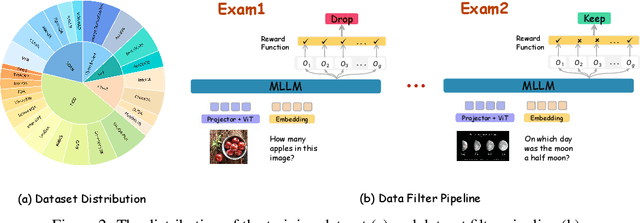

Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
Jan 29, 2025Understanding the physical world is a fundamental challenge in embodied AI, critical for enabling agents to perform complex tasks and operate safely in real-world environments. While Vision-Language Models (VLMs) have shown great promise in reasoning and task planning for embodied agents, their ability to comprehend physical phenomena remains extremely limited. To close this gap, we introduce PhysBench, a comprehensive benchmark designed to evaluate VLMs' physical world understanding capability across a diverse set of tasks. PhysBench contains 10,002 entries of interleaved video-image-text data, categorized into four major domains: physical object properties, physical object relationships, physical scene understanding, and physics-based dynamics, further divided into 19 subclasses and 8 distinct capability dimensions. Our extensive experiments, conducted on 75 representative VLMs, reveal that while these models excel in common-sense reasoning, they struggle with understanding the physical world -- likely due to the absence of physical knowledge in their training data and the lack of embedded physical priors. To tackle the shortfall, we introduce PhysAgent, a novel framework that combines the generalization strengths of VLMs with the specialized expertise of vision models, significantly enhancing VLMs' physical understanding across a variety of tasks, including an 18.4\% improvement on GPT-4o. Furthermore, our results demonstrate that enhancing VLMs' physical world understanding capabilities can help embodied agents such as MOKA. We believe that PhysBench and PhysAgent offer valuable insights and contribute to bridging the gap between VLMs and physical world understanding.
HumanEdit: A High-Quality Human-Rewarded Dataset for Instruction-based Image Editing
Dec 05, 2024We present HumanEdit, a high-quality, human-rewarded dataset specifically designed for instruction-guided image editing, enabling precise and diverse image manipulations through open-form language instructions. Previous large-scale editing datasets often incorporate minimal human feedback, leading to challenges in aligning datasets with human preferences. HumanEdit bridges this gap by employing human annotators to construct data pairs and administrators to provide feedback. With meticulously curation, HumanEdit comprises 5,751 images and requires more than 2,500 hours of human effort across four stages, ensuring both accuracy and reliability for a wide range of image editing tasks. The dataset includes six distinct types of editing instructions: Action, Add, Counting, Relation, Remove, and Replace, encompassing a broad spectrum of real-world scenarios. All images in the dataset are accompanied by masks, and for a subset of the data, we ensure that the instructions are sufficiently detailed to support mask-free editing. Furthermore, HumanEdit offers comprehensive diversity and high-resolution $1024 \times 1024$ content sourced from various domains, setting a new versatile benchmark for instructional image editing datasets. With the aim of advancing future research and establishing evaluation benchmarks in the field of image editing, we release HumanEdit at \url{https://huggingface.co/datasets/BryanW/HumanEdit}.
AnyEdit: Mastering Unified High-Quality Image Editing for Any Idea
Nov 24, 2024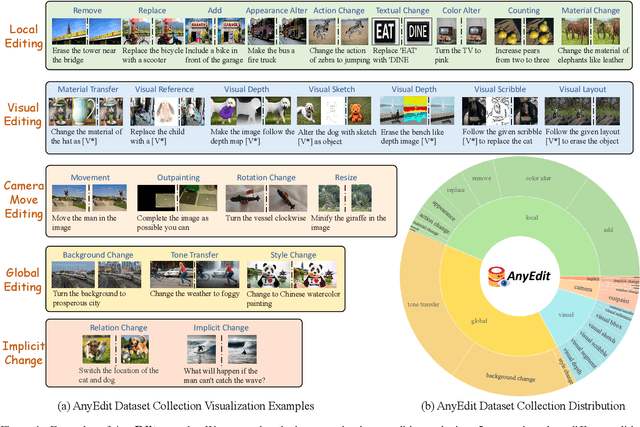



Instruction-based image editing aims to modify specific image elements with natural language instructions. However, current models in this domain often struggle to accurately execute complex user instructions, as they are trained on low-quality data with limited editing types. We present AnyEdit, a comprehensive multi-modal instruction editing dataset, comprising 2.5 million high-quality editing pairs spanning over 20 editing types and five domains. We ensure the diversity and quality of the AnyEdit collection through three aspects: initial data diversity, adaptive editing process, and automated selection of editing results. Using the dataset, we further train a novel AnyEdit Stable Diffusion with task-aware routing and learnable task embedding for unified image editing. Comprehensive experiments on three benchmark datasets show that AnyEdit consistently boosts the performance of diffusion-based editing models. This presents prospects for developing instruction-driven image editing models that support human creativity.
Unified Generative and Discriminative Training for Multi-modal Large Language Models
Nov 01, 2024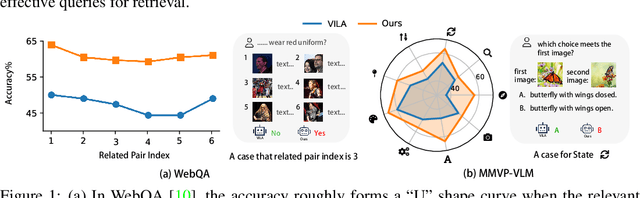
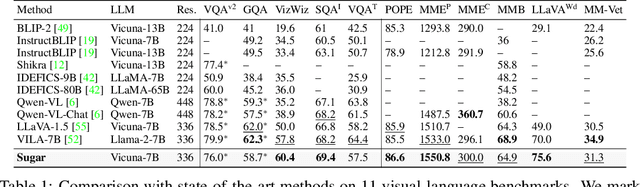
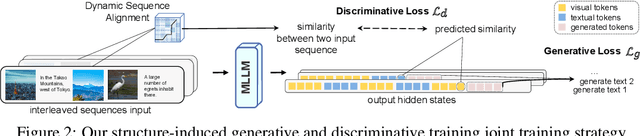
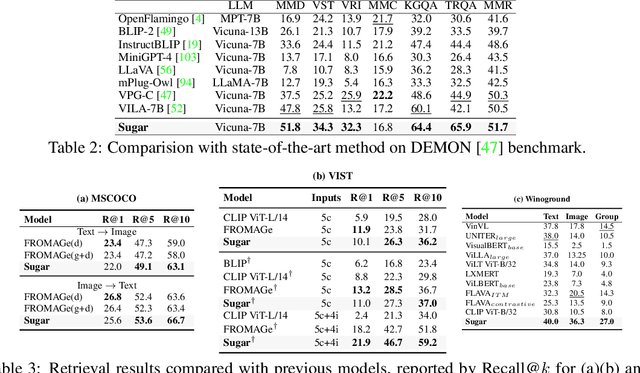
In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM's hidden state. This approach enhances the MLLM's ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.
Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
Oct 10, 2024
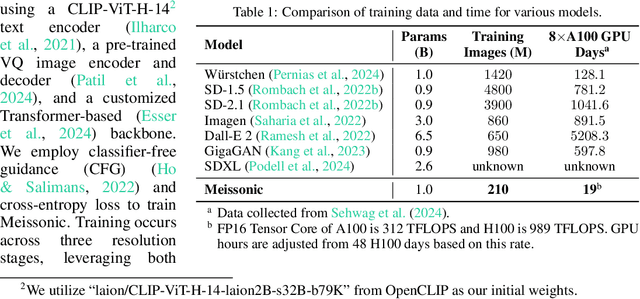
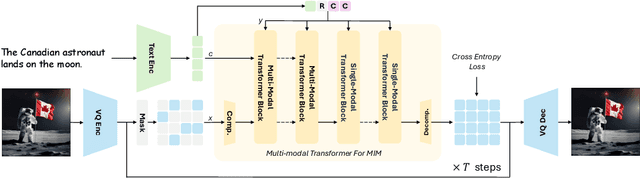
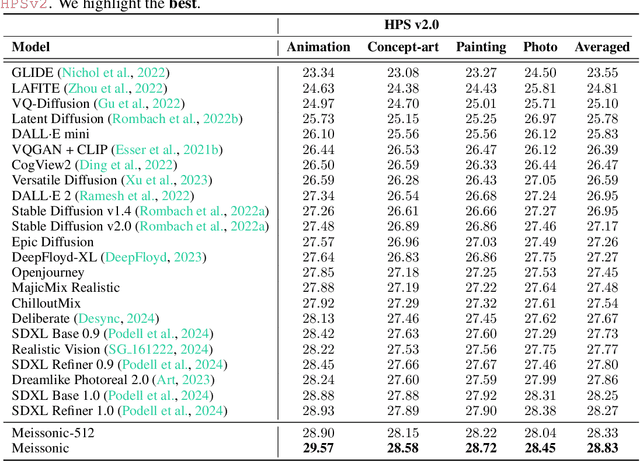
Diffusion models, such as Stable Diffusion, have made significant strides in visual generation, yet their paradigm remains fundamentally different from autoregressive language models, complicating the development of unified language-vision models. Recent efforts like LlamaGen have attempted autoregressive image generation using discrete VQVAE tokens, but the large number of tokens involved renders this approach inefficient and slow. In this work, we present Meissonic, which elevates non-autoregressive masked image modeling (MIM) text-to-image to a level comparable with state-of-the-art diffusion models like SDXL. By incorporating a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions, Meissonic substantially improves MIM's performance and efficiency. Additionally, we leverage high-quality training data, integrate micro-conditions informed by human preference scores, and employ feature compression layers to further enhance image fidelity and resolution. Our model not only matches but often exceeds the performance of existing models like SDXL in generating high-quality, high-resolution images. Extensive experiments validate Meissonic's capabilities, demonstrating its potential as a new standard in text-to-image synthesis. We release a model checkpoint capable of producing $1024 \times 1024$ resolution images.
Auto-Encoding Morph-Tokens for Multimodal LLM
May 03, 2024For multimodal LLMs, the synergy of visual comprehension (textual output) and generation (visual output) presents an ongoing challenge. This is due to a conflicting objective: for comprehension, an MLLM needs to abstract the visuals; for generation, it needs to preserve the visuals as much as possible. Thus, the objective is a dilemma for visual-tokens. To resolve the conflict, we propose encoding images into morph-tokens to serve a dual purpose: for comprehension, they act as visual prompts instructing MLLM to generate texts; for generation, they take on a different, non-conflicting role as complete visual-tokens for image reconstruction, where the missing visual cues are recovered by the MLLM. Extensive experiments show that morph-tokens can achieve a new SOTA for multimodal comprehension and generation simultaneously. Our project is available at https://github.com/DCDmllm/MorphTokens.