 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuvion LLM: An Adversarially-Aware Large Language Model for Content And AI Safety
Jun 26, 2026As large language models are increasingly deployed in real-world systems, safety failures can still lead to harmful outputs and dangerous misuse. We argue that the essence of safety is adversarial: many failures arise not from natural inputs alone, but from strategic attempts to evade model policies and safeguards. However, existing general-purpose model development largely overlook this adversarial nature, and often remain insufficient for realistic safety scenarios involving planning, tool use, and multi-step reasoning, causing measured safety performance to overestimate real deployment robustness. To address this gap, we present Yuvion LLM, a large language model built for adversarially robust content safety and broader AI safety. Yuvion LLM treats adversarial robustness and agentic capability as first-class objectives. Its pipeline combines adversarially aware data construction, knowledge-enhanced continued pretraining, and policy-grounded multi-task safety post-training, including risk-aware supervised fine-tuning and reinforcement learning-based policy optimization, together with safety-aware agentic reinforcement learning for tool use and multi-step reasoning in complex safety scenarios. We further introduce the Yuvion LLM RiskEval (YLRE), a collection of 93 benchmarks across four evaluation categories, covering diverse open and internal evaluations with a focus on safety, adversarial robustness, and real-world capability requirements. Across these evaluations, Yuvion LLM demonstrates clear advantages on safety-focused benchmarks and particularly strong robustness under adversarial conditions, while maintaining solid overall capability. Notably, Yuvion-8B outperforms most state-of-the-art baselines, including substantially larger models such as GPT-5.4 and Qwen3-MAX, on several safety tasks.
Yuvion VL: A Multimodal Foundation Model for Adversarial Content and AI Safety
Jun 23, 2026General-purpose models often struggle to reliably identify and understand real-world multimodal risks, largely due to the inherent multimodal adversarial nature of content and AI safety. We present Yuvion VL, a family of multimodal large language models purpose-built for content and AI safety, with both instruction-tuned and reasoning-oriented variants. Yuvion VL addresses this gap by treating safety as an inherently adversarial and multimodal problem and designing the entire pipeline around adversarial robustness. For data construction, we develop an automated pipeline integrating adversarial-aware data synthesis with multi-stage quality control, producing large-scale, high-quality multimodal samples augmented with domain knowledge and reasoning annotations. For training, we adopt a three-stage pipeline that includes continued pretraining for risk-concept cross-modal alignment, instruct post-training for production-grade safety tasks, and reasoning post-training for enhanced interpretability and performance in complex tasks. We further introduce Confuse-then-Contrast Fine-Tuning, a contrastive framework that mines model-specific confusions and constructs multi-image contrastive groups to enforce explicit discrimination of fine-grained visual-semantic elements, enabling the model to distinguish between visually similar cases with different safety implications in adversarial safety tasks. To support rigorous evaluation, we further introduce Yuvion VL RiskEval (YVRE), a collection of benchmarks covering diverse open and internal evaluations, with a focus on content and AI safety, adversarial robustness, and real-world capability requirements. Experiments show that Yuvion VL-32B achieves industry-leading safety performance, surpassing comparably sized open-source models and best closed-source commercial models, while maintaining comparable general capabilities.
Towards Unified Multimodal Editing with Enhanced Knowledge Collaboration
Sep 30, 2024
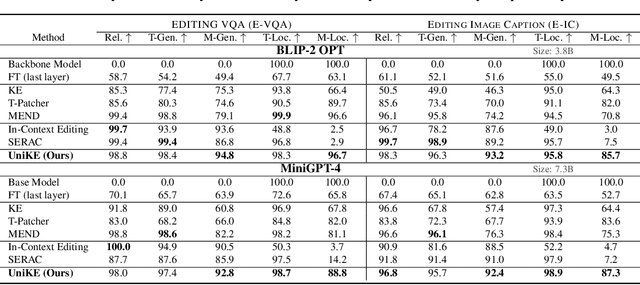
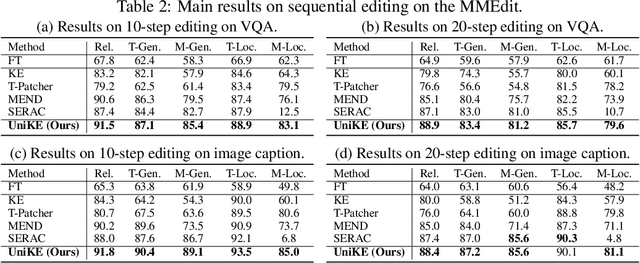
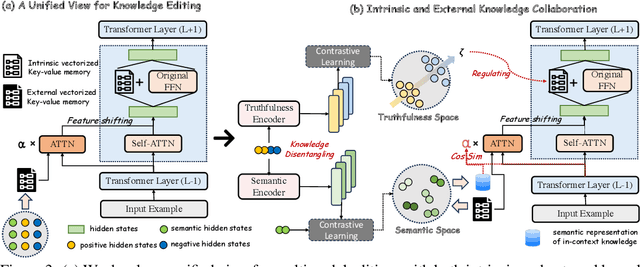
The swift advancement in Multimodal LLMs (MLLMs) also presents significant challenges for effective knowledge editing. Current methods, including intrinsic knowledge editing and external knowledge resorting, each possess strengths and weaknesses, struggling to balance the desired properties of reliability, generality, and locality when applied to MLLMs. In this paper, we propose UniKE, a novel multimodal editing method that establishes a unified perspective and paradigm for intrinsic knowledge editing and external knowledge resorting. Both types of knowledge are conceptualized as vectorized key-value memories, with the corresponding editing processes resembling the assimilation and accommodation phases of human cognition, conducted at the same semantic levels. Within such a unified framework, we further promote knowledge collaboration by disentangling the knowledge representations into the semantic and truthfulness spaces. Extensive experiments validate the effectiveness of our method, which ensures that the post-edit MLLM simultaneously maintains excellent reliability, generality, and locality. The code for UniKE will be available at \url{https://github.com/beepkh/UniKE}.
Coordinated Spectral Efficiency Prediction for Real-World 5G CoMP Systems
Aug 14, 2024Coordinated multipoint (CoMP) systems incur substantial resource consumption due to the management of backhaul links and the coordination among various base stations (BSs). Accurate prediction of coordinated spectral efficiency (CSE) can guide the optimization of network parameters, resulting in enhanced resource utilization efficiency. However, characterizing the CSE is intractable due to the inherent complexity of the CoMP channel model and the diversity of the 5G dynamic network environment, which poses a great challenge for CSE prediction in real-world 5G CoMP systems. To address this challenge, in this letter, we propose a data-driven model-assisted approach. Initially, we leverage domain knowledge to preprocess the collected raw data, thereby creating a well-informed dataset. Within this dataset, we explicitly define the target variable and the input feature space relevant to channel statistics for CSE prediction. Subsequently, a residual-based network model is built to capture the high-dimensional non-linear mapping function from the channel statistics to the CSE. The effectiveness of the proposed approach is validated by experimental results on real-world data.
Auto-Encoding Morph-Tokens for Multimodal LLM
May 03, 2024For multimodal LLMs, the synergy of visual comprehension (textual output) and generation (visual output) presents an ongoing challenge. This is due to a conflicting objective: for comprehension, an MLLM needs to abstract the visuals; for generation, it needs to preserve the visuals as much as possible. Thus, the objective is a dilemma for visual-tokens. To resolve the conflict, we propose encoding images into morph-tokens to serve a dual purpose: for comprehension, they act as visual prompts instructing MLLM to generate texts; for generation, they take on a different, non-conflicting role as complete visual-tokens for image reconstruction, where the missing visual cues are recovered by the MLLM. Extensive experiments show that morph-tokens can achieve a new SOTA for multimodal comprehension and generation simultaneously. Our project is available at https://github.com/DCDmllm/MorphTokens.