 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSesaHand: Enhancing 3D Hand Reconstruction via Controllable Generation with Semantic and Structural Alignment
Feb 28, 2026Recent studies on 3D hand reconstruction have demonstrated the effectiveness of synthetic training data to improve estimation performance. However, most methods rely on game engines to synthesize hand images, which often lack diversity in textures and environments, and fail to include crucial components like arms or interacting objects. Generative models are promising alternatives to generate diverse hand images, but still suffer from misalignment issues. In this paper, we present SesaHand, which enhances controllable hand image generation from both semantic and structural alignment perspectives for 3D hand reconstruction. Specifically, for semantic alignment, we propose a pipeline with Chain-of-Thought inference to extract human behavior semantics from image captions generated by the Vision-Language Model. This semantics suppresses human-irrelevant environmental details and ensures sufficient human-centric contexts for hand image generation. For structural alignment, we introduce hierarchical structural fusion to integrate structural information with different granularity for feature refinement to better align the hand and the overall human body in generated images. We further propose a hand structure attention enhancement method to efficiently enhance the model's attention on hand regions. Experiments demonstrate that our method not only outperforms prior work in generation performance but also improves 3D hand reconstruction with the generated hand images.
Composing Concepts from Images and Videos via Concept-prompt Binding
Dec 10, 2025Visual concept composition, which aims to integrate different elements from images and videos into a single, coherent visual output, still falls short in accurately extracting complex concepts from visual inputs and flexibly combining concepts from both images and videos. We introduce Bind & Compose, a one-shot method that enables flexible visual concept composition by binding visual concepts with corresponding prompt tokens and composing the target prompt with bound tokens from various sources. It adopts a hierarchical binder structure for cross-attention conditioning in Diffusion Transformers to encode visual concepts into corresponding prompt tokens for accurate decomposition of complex visual concepts. To improve concept-token binding accuracy, we design a Diversify-and-Absorb Mechanism that uses an extra absorbent token to eliminate the impact of concept-irrelevant details when training with diversified prompts. To enhance the compatibility between image and video concepts, we present a Temporal Disentanglement Strategy that decouples the training process of video concepts into two stages with a dual-branch binder structure for temporal modeling. Evaluations demonstrate that our method achieves superior concept consistency, prompt fidelity, and motion quality over existing approaches, opening up new possibilities for visual creativity.
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
May 29, 2025Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
Analyzing the Synthetic-to-Real Domain Gap in 3D Hand Pose Estimation
Mar 25, 2025



Recent synthetic 3D human datasets for the face, body, and hands have pushed the limits on photorealism. Face recognition and body pose estimation have achieved state-of-the-art performance using synthetic training data alone, but for the hand, there is still a large synthetic-to-real gap. This paper presents the first systematic study of the synthetic-to-real gap of 3D hand pose estimation. We analyze the gap and identify key components such as the forearm, image frequency statistics, hand pose, and object occlusions. To facilitate our analysis, we propose a data synthesis pipeline to synthesize high-quality data. We demonstrate that synthetic hand data can achieve the same level of accuracy as real data when integrating our identified components, paving the path to use synthetic data alone for hand pose estimation. Code and data are available at: https://github.com/delaprada/HandSynthesis.git.
InfNeRF: Towards Infinite Scale NeRF Rendering with O(log n) Space Complexity
Mar 21, 2024The conventional mesh-based Level of Detail (LoD) technique, exemplified by applications such as Google Earth and many game engines, exhibits the capability to holistically represent a large scene even the Earth, and achieves rendering with a space complexity of O(log n). This constrained data requirement not only enhances rendering efficiency but also facilitates dynamic data fetching, thereby enabling a seamless 3D navigation experience for users. In this work, we extend this proven LoD technique to Neural Radiance Fields (NeRF) by introducing an octree structure to represent the scenes in different scales. This innovative approach provides a mathematically simple and elegant representation with a rendering space complexity of O(log n), aligned with the efficiency of mesh-based LoD techniques. We also present a novel training strategy that maintains a complexity of O(n). This strategy allows for parallel training with minimal overhead, ensuring the scalability and efficiency of our proposed method. Our contribution is not only in extending the capabilities of existing techniques but also in establishing a foundation for scalable and efficient large-scale scene representation using NeRF and octree structures.
HiFiHR: Enhancing 3D Hand Reconstruction from a Single Image via High-Fidelity Texture
Aug 25, 2023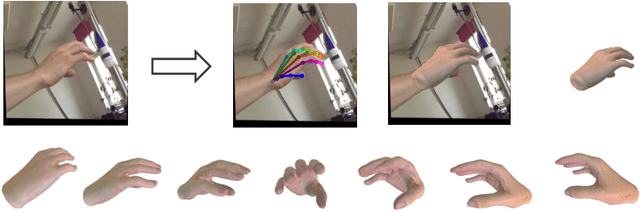
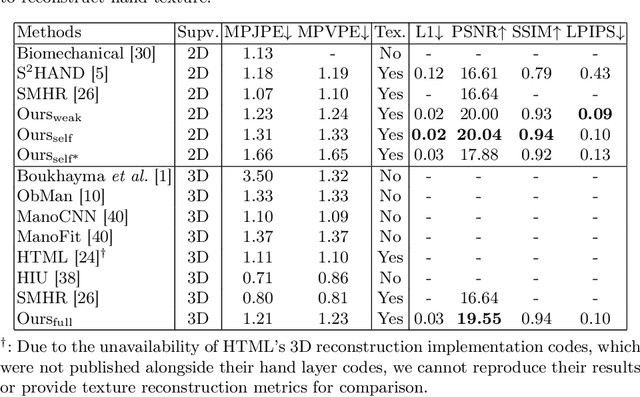
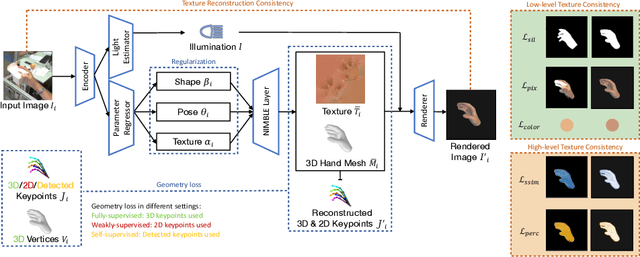
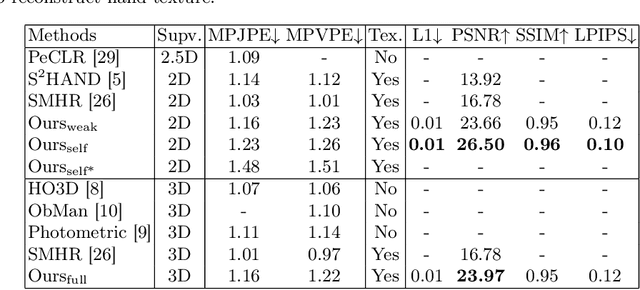
We present HiFiHR, a high-fidelity hand reconstruction approach that utilizes render-and-compare in the learning-based framework from a single image, capable of generating visually plausible and accurate 3D hand meshes while recovering realistic textures. Our method achieves superior texture reconstruction by employing a parametric hand model with predefined texture assets, and by establishing a texture reconstruction consistency between the rendered and input images during training. Moreover, based on pretraining the network on an annotated dataset, we apply varying degrees of supervision using our pipeline, i.e., self-supervision, weak supervision, and full supervision, and discuss the various levels of contributions of the learned high-fidelity textures in enhancing hand pose and shape estimation. Experimental results on public benchmarks including FreiHAND and HO-3D demonstrate that our method outperforms the state-of-the-art hand reconstruction methods in texture reconstruction quality while maintaining comparable accuracy in pose and shape estimation. Our code is available at https://github.com/viridityzhu/HiFiHR.
Taming Diffusion Models for Music-driven Conducting Motion Generation
Jun 15, 2023



Generating the motion of orchestral conductors from a given piece of symphony music is a challenging task since it requires a model to learn semantic music features and capture the underlying distribution of real conducting motion. Prior works have applied Generative Adversarial Networks (GAN) to this task, but the promising diffusion model, which recently showed its advantages in terms of both training stability and output quality, has not been exploited in this context. This paper presents Diffusion-Conductor, a novel DDIM-based approach for music-driven conducting motion generation, which integrates the diffusion model to a two-stage learning framework. We further propose a random masking strategy to improve the feature robustness, and use a pair of geometric loss functions to impose additional regularizations and increase motion diversity. We also design several novel metrics, including Frechet Gesture Distance (FGD) and Beat Consistency Score (BC) for a more comprehensive evaluation of the generated motion. Experimental results demonstrate the advantages of our model.
Understanding Capacity-Driven Scale-Out Neural Recommendation Inference
Nov 11, 2020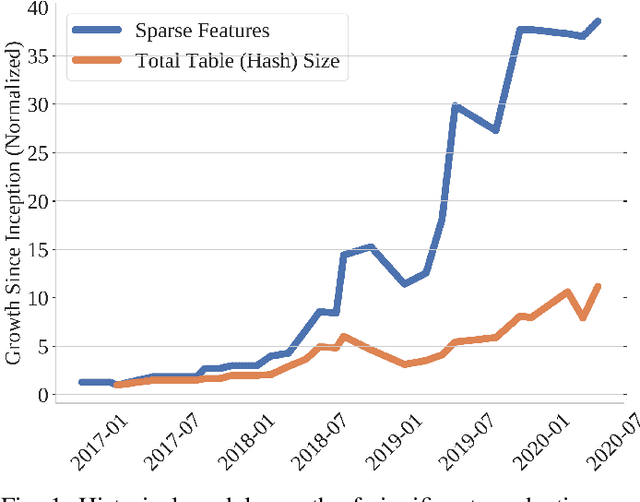

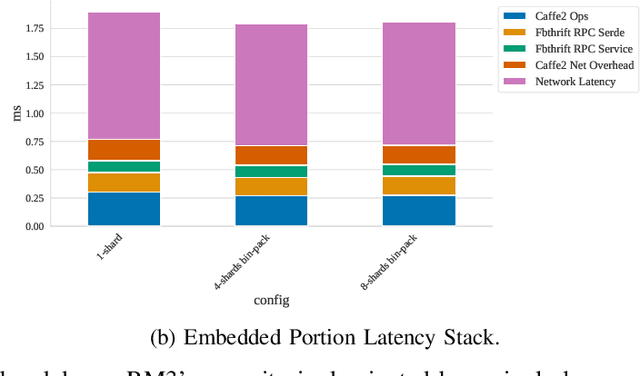
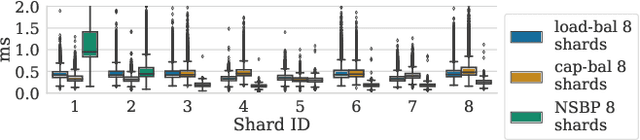
Deep learning recommendation models have grown to the terabyte scale. Traditional serving schemes--that load entire models to a single server--are unable to support this scale. One approach to support this scale is with distributed serving, or distributed inference, which divides the memory requirements of a single large model across multiple servers. This work is a first-step for the systems research community to develop novel model-serving solutions, given the huge system design space. Large-scale deep recommender systems are a novel workload and vital to study, as they consume up to 79% of all inference cycles in the data center. To that end, this work describes and characterizes scale-out deep learning recommendation inference using data-center serving infrastructure. This work specifically explores latency-bounded inference systems, compared to the throughput-oriented training systems of other recent works. We find that the latency and compute overheads of distributed inference are largely a result of a model's static embedding table distribution and sparsity of input inference requests. We further evaluate three embedding table mapping strategies of three DLRM-like models and specify challenging design trade-offs in terms of end-to-end latency, compute overhead, and resource efficiency. Overall, we observe only a marginal latency overhead when the data-center scale recommendation models are served with the distributed inference manner--P99 latency is increased by only 1% in the best case configuration. The latency overheads are largely a result of the commodity infrastructure used and the sparsity of embedding tables. Even more encouragingly, we also show how distributed inference can account for efficiency improvements in data-center scale recommendation serving.