 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeRPO: Verifiable Dense Reward Policy Optimization for Code Generation
Jan 07, 2026Effective reward design is a central challenge in Reinforcement Learning (RL) for code generation. Mainstream pass/fail outcome rewards enforce functional correctness via executing unit tests, but the resulting sparsity limits potential performance gains. While recent work has explored external Reward Models (RM) to generate richer, continuous rewards, the learned RMs suffer from reward misalignment and prohibitive computational cost. In this paper, we introduce \textbf{VeRPO} (\textbf{V}erifiable D\textbf{e}nse \textbf{R}eward \textbf{P}olicy \textbf{O}ptimization), a novel RL framework for code generation that synthesizes \textit{robust and dense rewards fully grounded in verifiable execution feedback}. The core idea of VeRPO is constructing dense rewards from weighted partial success: by dynamically estimating the difficulty weight of each unit test based on the execution statistics during training, a dense reward is derived from the sum of weights of the passed unit tests. To solidify the consistency between partial success and end-to-end functional correctness, VeRPO further integrates the dense signal with global execution outcomes, establishing a robust and dense reward paradigm relying solely on verifiable execution feedback. Extensive experiments across diverse benchmarks and settings demonstrate that VeRPO consistently outperforms outcome-driven and RM-based baselines, achieving up to +8.83\% gain in pass@1 with negligible time cost (< 0.02\%) and zero GPU memory overhead.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
RecTok: Reconstruction Distillation along Rectified Flow
Dec 17, 2025Visual tokenizers play a crucial role in diffusion models. The dimensionality of latent space governs both reconstruction fidelity and the semantic expressiveness of the latent feature. However, a fundamental trade-off is inherent between dimensionality and generation quality, constraining existing methods to low-dimensional latent spaces. Although recent works have leveraged vision foundation models to enrich the semantics of visual tokenizers and accelerate convergence, high-dimensional tokenizers still underperform their low-dimensional counterparts. In this work, we propose RecTok, which overcomes the limitations of high-dimensional visual tokenizers through two key innovations: flow semantic distillation and reconstruction--alignment distillation. Our key insight is to make the forward flow in flow matching semantically rich, which serves as the training space of diffusion transformers, rather than focusing on the latent space as in previous works. Specifically, our method distills the semantic information in VFMs into the forward flow trajectories in flow matching. And we further enhance the semantics by introducing a masked feature reconstruction loss. Our RecTok achieves superior image reconstruction, generation quality, and discriminative performance. It achieves state-of-the-art results on the gFID-50K under both with and without classifier-free guidance settings, while maintaining a semantically rich latent space structure. Furthermore, as the latent dimensionality increases, we observe consistent improvements. Code and model are available at https://shi-qingyu.github.io/rectok.github.io.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
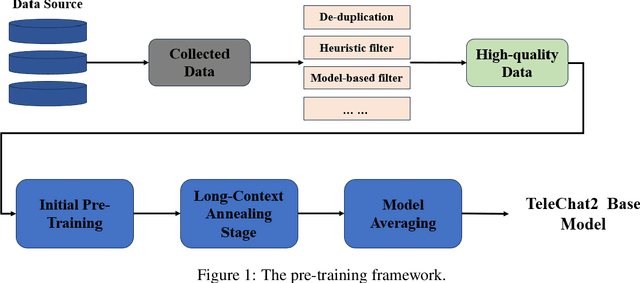

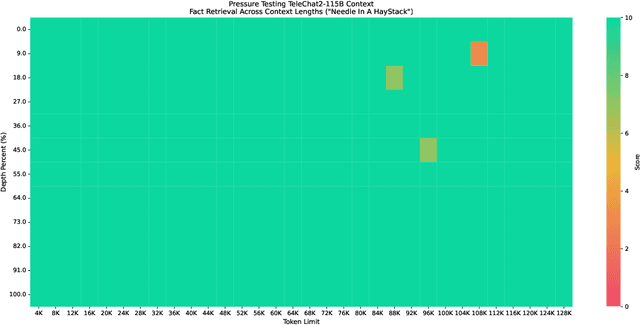
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
HSSBench: Benchmarking Humanities and Social Sciences Ability for Multimodal Large Language Models
Jun 04, 2025



Multimodal Large Language Models (MLLMs) have demonstrated significant potential to advance a broad range of domains. However, current benchmarks for evaluating MLLMs primarily emphasize general knowledge and vertical step-by-step reasoning typical of STEM disciplines, while overlooking the distinct needs and potential of the Humanities and Social Sciences (HSS). Tasks in the HSS domain require more horizontal, interdisciplinary thinking and a deep integration of knowledge across related fields, which presents unique challenges for MLLMs, particularly in linking abstract concepts with corresponding visual representations. Addressing this gap, we present HSSBench, a dedicated benchmark designed to assess the capabilities of MLLMs on HSS tasks in multiple languages, including the six official languages of the United Nations. We also introduce a novel data generation pipeline tailored for HSS scenarios, in which multiple domain experts and automated agents collaborate to generate and iteratively refine each sample. HSSBench contains over 13,000 meticulously designed samples, covering six key categories. We benchmark more than 20 mainstream MLLMs on HSSBench and demonstrate that it poses significant challenges even for state-of-the-art models. We hope that this benchmark will inspire further research into enhancing the cross-disciplinary reasoning abilities of MLLMs, especially their capacity to internalize and connect knowledge across fields.
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
May 29, 2025Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
Improve LLM-as-a-Judge Ability as a General Ability
Feb 17, 2025



LLM-as-a-Judge leverages the generative and reasoning capabilities of large language models (LLMs) to evaluate LLM responses across diverse scenarios, providing accurate preference signals. This approach plays a vital role in aligning LLMs with human values, ensuring ethical and reliable AI outputs that align with societal norms. Recent studies have raised many methods to train LLM as generative judges, but most of them are data consuming or lack accuracy, and only focus on LLM's judge ability. In this work, we regard judge ability as a general ability of LLM and implement a two-stage training approach, comprising supervised fine-tuning (SFT) warm-up and direct preference optimization (DPO) enhancement, to achieve judge style adaptation and improve judgment accuracy. Additionally, we introduce an efficient data synthesis method to generate judgmental content. Experimental results demonstrate that our approach, utilizing only about 2% to 40% of the data required by other methods, achieves SOTA performance on RewardBench. Furthermore, our training method enhances the general capabilities of the model by constructing complicated judge task, and the judge signals provided by our model have significantly enhanced the downstream DPO training performance of our internal models in our test to optimize policy model with Judge Model. We also open-source our model weights and training data to facilitate further research.
Yi: Open Foundation Models by 01.AI
Mar 07, 2024



We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
MME-CRS: Multi-Metric Evaluation Based on Correlation Re-Scaling for Evaluating Open-Domain Dialogue
Jun 19, 2022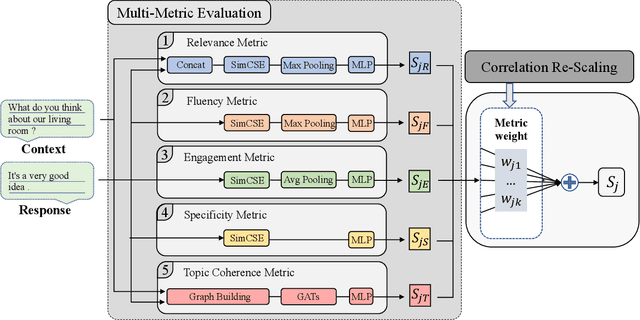

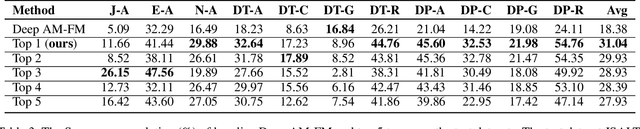
Automatic open-domain dialogue evaluation is a crucial component of dialogue systems. Recently, learning-based evaluation metrics have achieved state-of-the-art performance in open-domain dialogue evaluation. However, these metrics, which only focus on a few qualities, are hard to evaluate dialogue comprehensively. Furthermore, these metrics lack an effective score composition approach for diverse evaluation qualities. To address the above problems, we propose a Multi-Metric Evaluation based on Correlation Re-Scaling (MME-CRS) for evaluating open-domain dialogue. Firstly, we build an evaluation metric composed of 5 groups of parallel sub-metrics called Multi-Metric Evaluation (MME) to evaluate the quality of dialogue comprehensively. Furthermore, we propose a novel score composition method called Correlation Re-Scaling (CRS) to model the relationship between sub-metrics and diverse qualities. Our approach MME-CRS ranks first on the final test data of DSTC10 track5 subtask1 Automatic Open-domain Dialogue Evaluation Challenge with a large margin, which proved the effectiveness of our proposed approach.