 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Zero-Indexing Internet Search Augmented Generation for Large Language Models
Nov 29, 2024Retrieval augmented generation has emerged as an effective method to enhance large language model performance. This approach typically relies on an internal retrieval module that uses various indexing mechanisms to manage a static pre-processed corpus. However, such a paradigm often falls short when it is necessary to integrate the most up-to-date information that has not been updated into the corpus during generative inference time. In this paper, we explore an alternative approach that leverages standard search engine APIs to dynamically integrate the latest online information (without maintaining any index for any fixed corpus), thereby improving the quality of generated content. We design a collaborative LLM-based paradigm, where we include: (i) a parser-LLM that determines if the Internet augmented generation is demanded and extracts the search keywords if so with a single inference; (ii) a mixed ranking strategy that re-ranks the retrieved HTML files to eliminate bias introduced from the search engine API; and (iii) an extractor-LLM that can accurately and efficiently extract relevant information from the fresh content in each HTML file. We conduct extensive empirical studies to evaluate the performance of this Internet search augmented generation paradigm. The experimental results demonstrate that our method generates content with significantly improved quality. Our system has been successfully deployed in a production environment to serve 01.AI's generative inference requests.
Yi: Open Foundation Models by 01.AI
Mar 07, 2024



We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
JiangJun: Mastering Xiangqi by Tackling Non-Transitivity in Two-Player Zero-Sum Games
Aug 09, 2023



This paper presents an empirical exploration of non-transitivity in perfect-information games, specifically focusing on Xiangqi, a traditional Chinese board game comparable in game-tree complexity to chess and shogi. By analyzing over 10,000 records of human Xiangqi play, we highlight the existence of both transitive and non-transitive elements within the game's strategic structure. To address non-transitivity, we introduce the JiangJun algorithm, an innovative combination of Monte-Carlo Tree Search (MCTS) and Policy Space Response Oracles (PSRO) designed to approximate a Nash equilibrium. We evaluate the algorithm empirically using a WeChat mini program and achieve a Master level with a 99.41\% win rate against human players. The algorithm's effectiveness in overcoming non-transitivity is confirmed by a plethora of metrics, such as relative population performance and visualization results. Our project site is available at \url{https://sites.google.com/view/jiangjun-site/}.
An Empirical Study on Google Research Football Multi-agent Scenarios
May 16, 2023Few multi-agent reinforcement learning (MARL) research on Google Research Football (GRF) focus on the 11v11 multi-agent full-game scenario and to the best of our knowledge, no open benchmark on this scenario has been released to the public. In this work, we fill the gap by providing a population-based MARL training pipeline and hyperparameter settings on multi-agent football scenario that outperforms the bot with difficulty 1.0 from scratch within 2 million steps. Our experiments serve as a reference for the expected performance of Independent Proximal Policy Optimization (IPPO), a state-of-the-art multi-agent reinforcement learning algorithm where each agent tries to maximize its own policy independently across various training configurations. Meanwhile, we open-source our training framework Light-MALib which extends the MALib codebase by distributed and asynchronized implementation with additional analytical tools for football games. Finally, we provide guidance for building strong football AI with population-based training and release diverse pretrained policies for benchmarking. The goal is to provide the community with a head start for whoever experiment their works on GRF and a simple-to-use population-based training framework for further improving their agents through self-play. The implementation is available at https://github.com/Shanghai-Digital-Brain-Laboratory/DB-Football.
Learnable Behavior Control: Breaking Atari Human World Records via Sample-Efficient Behavior Selection
May 09, 2023



The exploration problem is one of the main challenges in deep reinforcement learning (RL). Recent promising works tried to handle the problem with population-based methods, which collect samples with diverse behaviors derived from a population of different exploratory policies. Adaptive policy selection has been adopted for behavior control. However, the behavior selection space is largely limited by the predefined policy population, which further limits behavior diversity. In this paper, we propose a general framework called Learnable Behavioral Control (LBC) to address the limitation, which a) enables a significantly enlarged behavior selection space via formulating a hybrid behavior mapping from all policies; b) constructs a unified learnable process for behavior selection. We introduce LBC into distributed off-policy actor-critic methods and achieve behavior control via optimizing the selection of the behavior mappings with bandit-based meta-controllers. Our agents have achieved 10077.52% mean human normalized score and surpassed 24 human world records within 1B training frames in the Arcade Learning Environment, which demonstrates our significant state-of-the-art (SOTA) performance without degrading the sample efficiency.
CTDS: Centralized Teacher with Decentralized Student for Multi-Agent Reinforcement Learning
Mar 16, 2022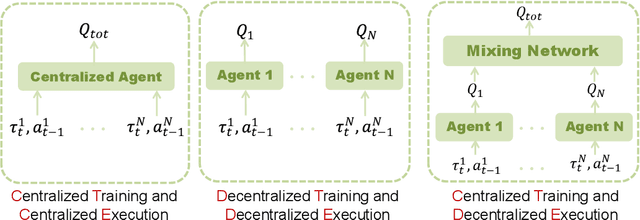
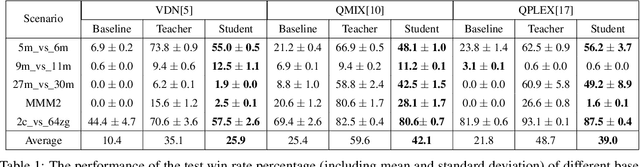
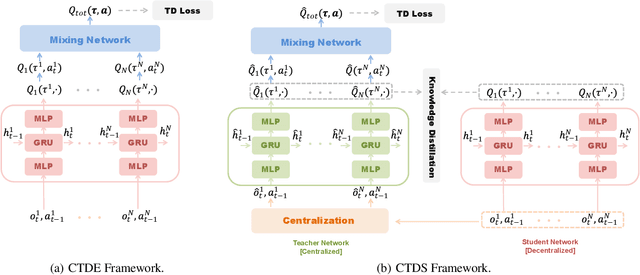

Due to the partial observability and communication constraints in many multi-agent reinforcement learning (MARL) tasks, centralized training with decentralized execution (CTDE) has become one of the most widely used MARL paradigms. In CTDE, centralized information is dedicated to learning the allocation of the team reward with a mixing network, while the learning of individual Q-values is usually based on local observations. The insufficient utility of global observation will degrade performance in challenging environments. To this end, this work proposes a novel Centralized Teacher with Decentralized Student (CTDS) framework, which consists of a teacher model and a student model. Specifically, the teacher model allocates the team reward by learning individual Q-values conditioned on global observation, while the student model utilizes the partial observations to approximate the Q-values estimated by the teacher model. In this way, CTDS balances the full utilization of global observation during training and the feasibility of decentralized execution for online inference. Our CTDS framework is generic which is ready to be applied upon existing CTDE methods to boost their performance. We conduct experiments on a challenging set of StarCraft II micromanagement tasks to test the effectiveness of our method and the results show that CTDS outperforms the existing value-based MARL methods.
Revisiting QMIX: Discriminative Credit Assignment by Gradient Entropy Regularization
Feb 16, 2022

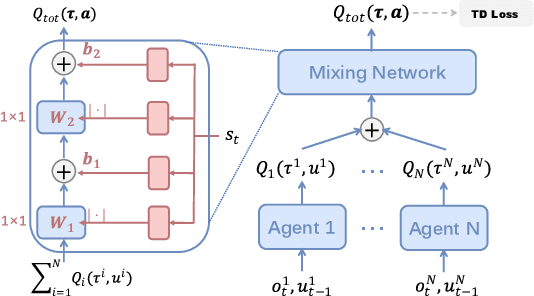
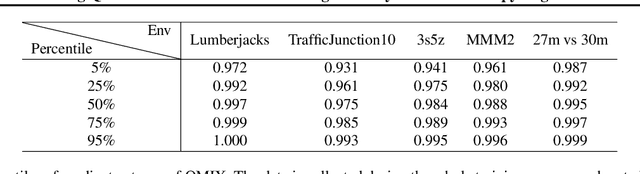
In cooperative multi-agent systems, agents jointly take actions and receive a team reward instead of individual rewards. In the absence of individual reward signals, credit assignment mechanisms are usually introduced to discriminate the contributions of different agents so as to achieve effective cooperation. Recently, the value decomposition paradigm has been widely adopted to realize credit assignment, and QMIX has become the state-of-the-art solution. In this paper, we revisit QMIX from two aspects. First, we propose a new perspective on credit assignment measurement and empirically show that QMIX suffers limited discriminability on the assignment of credits to agents. Second, we propose a gradient entropy regularization with QMIX to realize a discriminative credit assignment, thereby improving the overall performance. The experiments demonstrate that our approach can comparatively improve learning efficiency and achieve better performance.
Look Before You Leap: Safe Model-Based Reinforcement Learning with Human Intervention
Nov 16, 2021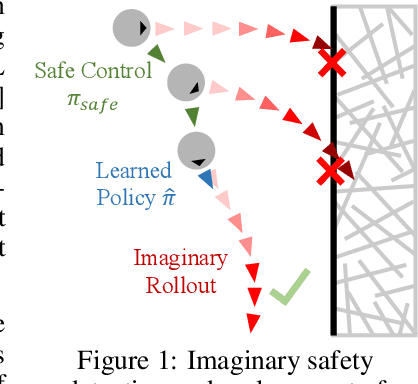
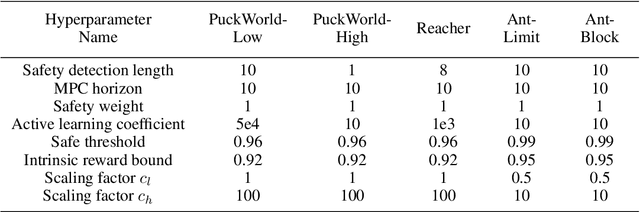
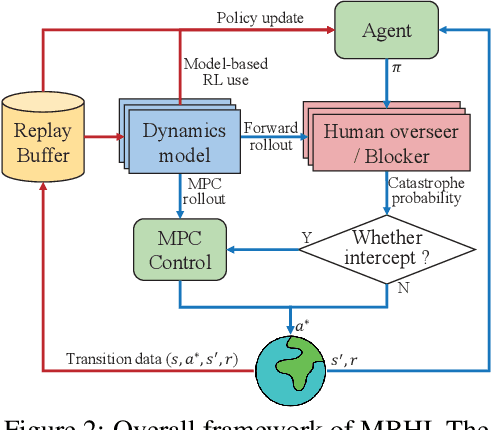
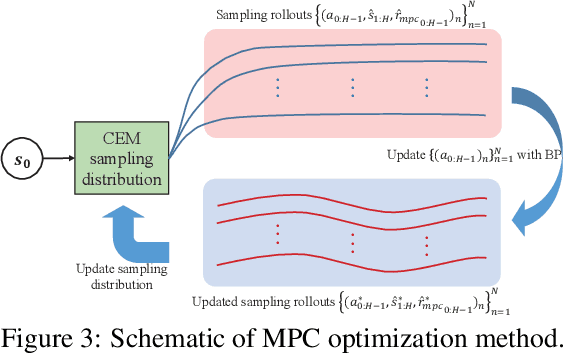
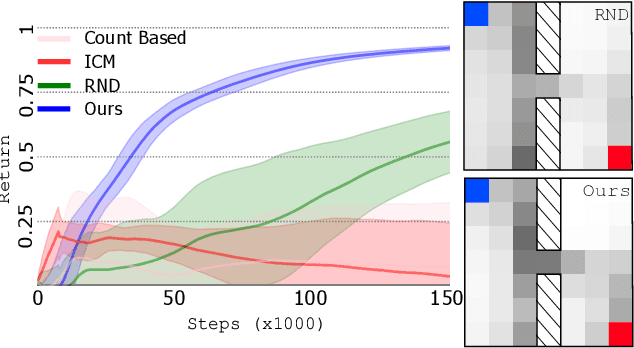
Safety has become one of the main challenges of applying deep reinforcement learning to real world systems. Currently, the incorporation of external knowledge such as human oversight is the only means to prevent the agent from visiting the catastrophic state. In this paper, we propose MBHI, a novel framework for safe model-based reinforcement learning, which ensures safety in the state-level and can effectively avoid both "local" and "non-local" catastrophes. An ensemble of supervised learners are trained in MBHI to imitate human blocking decisions. Similar to human decision-making process, MBHI will roll out an imagined trajectory in the dynamics model before executing actions to the environment, and estimate its safety. When the imagination encounters a catastrophe, MBHI will block the current action and use an efficient MPC method to output a safety policy. We evaluate our method on several safety tasks, and the results show that MBHI achieved better performance in terms of sample efficiency and number of catastrophes compared to the baselines.
Learning to Shape Rewards using a Game of Switching Controls
Mar 16, 2021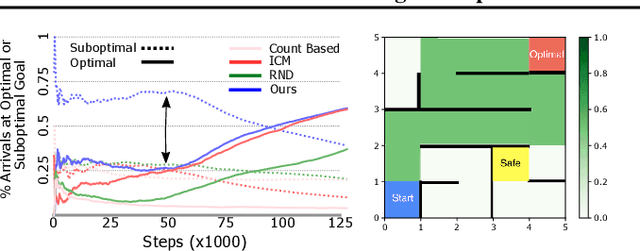
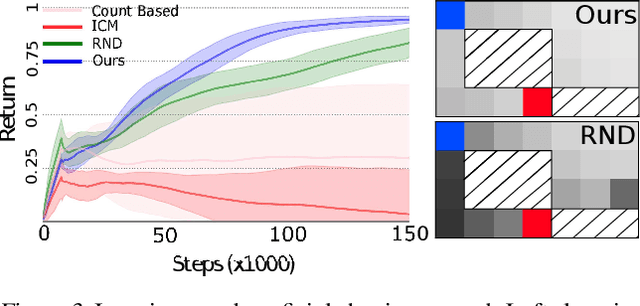
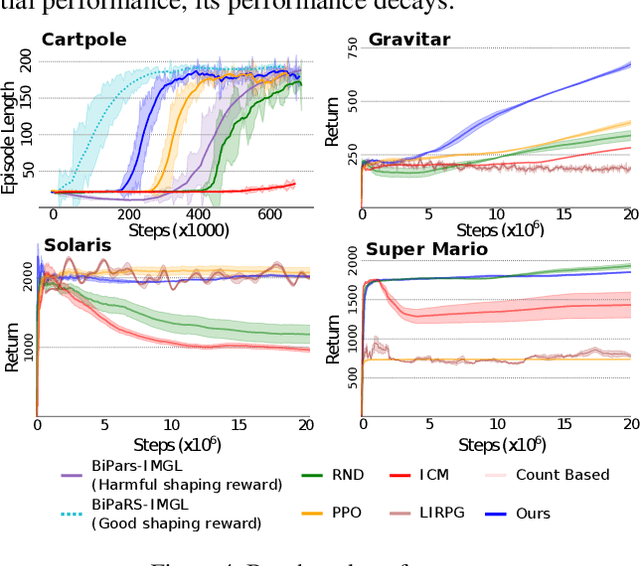
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse and uninformative rewards. However, RS relies on manually engineered shaping-reward functions whose construction is typically time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. In this paper, we introduce an automated RS framework in which the shaping-reward function is constructed in a novel stochastic game between two agents. One agent learns both which states to add shaping rewards and their optimal magnitudes and the other agent learns the optimal policy for the task using the shaped rewards. We prove theoretically that our framework, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task and ensures convergence to higher performing policies for the given task. We demonstrate the superior performance of our method against state-of-the-art RS algorithms in Cartpole and the challenging console games Gravitar, Solaris and Super Mario.