 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025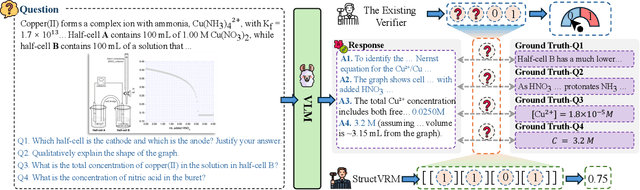

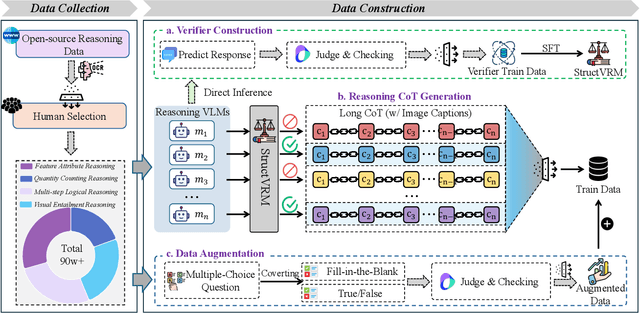
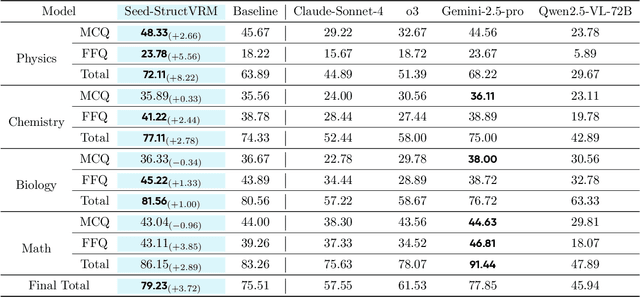
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
JiangJun: Mastering Xiangqi by Tackling Non-Transitivity in Two-Player Zero-Sum Games
Aug 09, 2023



This paper presents an empirical exploration of non-transitivity in perfect-information games, specifically focusing on Xiangqi, a traditional Chinese board game comparable in game-tree complexity to chess and shogi. By analyzing over 10,000 records of human Xiangqi play, we highlight the existence of both transitive and non-transitive elements within the game's strategic structure. To address non-transitivity, we introduce the JiangJun algorithm, an innovative combination of Monte-Carlo Tree Search (MCTS) and Policy Space Response Oracles (PSRO) designed to approximate a Nash equilibrium. We evaluate the algorithm empirically using a WeChat mini program and achieve a Master level with a 99.41\% win rate against human players. The algorithm's effectiveness in overcoming non-transitivity is confirmed by a plethora of metrics, such as relative population performance and visualization results. Our project site is available at \url{https://sites.google.com/view/jiangjun-site/}.
An Empirical Study on Google Research Football Multi-agent Scenarios
May 16, 2023Few multi-agent reinforcement learning (MARL) research on Google Research Football (GRF) focus on the 11v11 multi-agent full-game scenario and to the best of our knowledge, no open benchmark on this scenario has been released to the public. In this work, we fill the gap by providing a population-based MARL training pipeline and hyperparameter settings on multi-agent football scenario that outperforms the bot with difficulty 1.0 from scratch within 2 million steps. Our experiments serve as a reference for the expected performance of Independent Proximal Policy Optimization (IPPO), a state-of-the-art multi-agent reinforcement learning algorithm where each agent tries to maximize its own policy independently across various training configurations. Meanwhile, we open-source our training framework Light-MALib which extends the MALib codebase by distributed and asynchronized implementation with additional analytical tools for football games. Finally, we provide guidance for building strong football AI with population-based training and release diverse pretrained policies for benchmarking. The goal is to provide the community with a head start for whoever experiment their works on GRF and a simple-to-use population-based training framework for further improving their agents through self-play. The implementation is available at https://github.com/Shanghai-Digital-Brain-Laboratory/DB-Football.