 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Balanced Distillation for Object Detection
Aug 05, 2022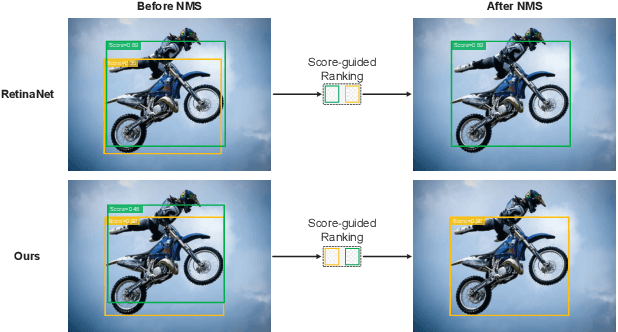

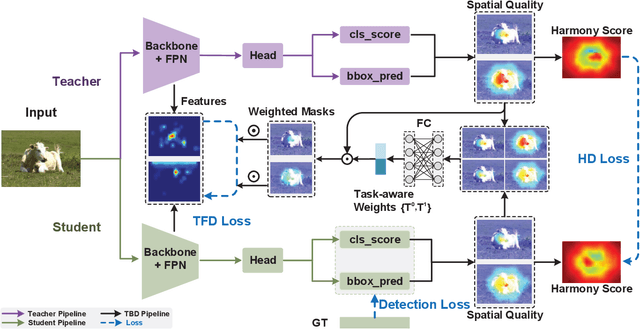
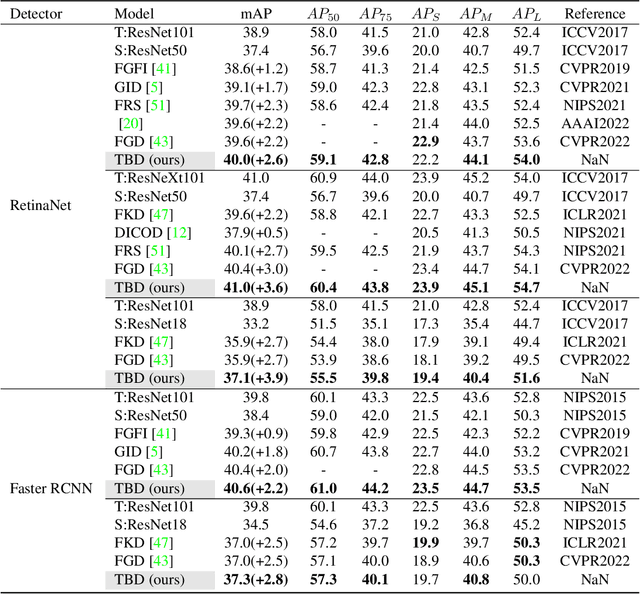
Mainstream object detectors are commonly constituted of two sub-tasks, including classification and regression tasks, implemented by two parallel heads. This classic design paradigm inevitably leads to inconsistent spatial distributions between classification score and localization quality (IOU). Therefore, this paper alleviates this misalignment in the view of knowledge distillation. First, we observe that the massive teacher achieves a higher proportion of harmonious predictions than the lightweight student. Based on this intriguing observation, a novel Harmony Score (HS) is devised to estimate the alignment of classification and regression qualities. HS models the relationship between two sub-tasks and is seen as prior knowledge to promote harmonious predictions for the student. Second, this spatial misalignment will result in inharmonious region selection when distilling features. To alleviate this problem, a novel Task-decoupled Feature Distillation (TFD) is proposed by flexibly balancing the contributions of classification and regression tasks. Eventually, HD and TFD constitute the proposed method, named Task-Balanced Distillation (TBD). Extensive experiments demonstrate the considerable potential and generalization of the proposed method. Specifically, when equipped with TBD, RetinaNet with ResNet-50 achieves 41.0 mAP under the COCO benchmark, outperforming the recent FGD and FRS.
Look Before You Leap: Safe Model-Based Reinforcement Learning with Human Intervention
Nov 16, 2021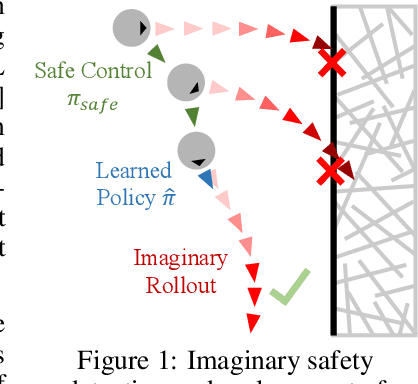
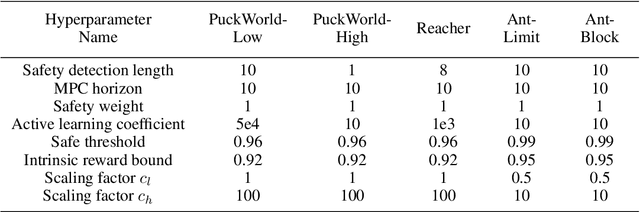
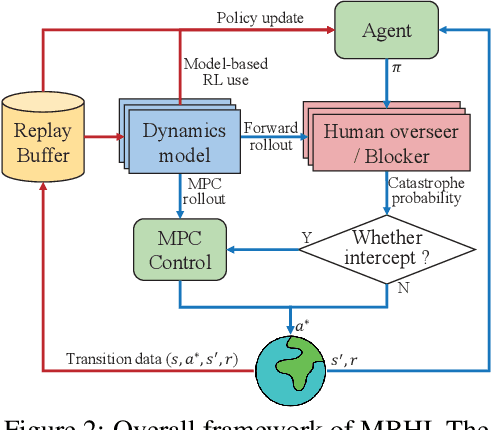
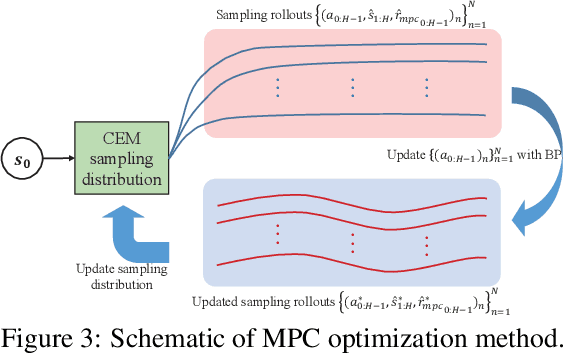
Safety has become one of the main challenges of applying deep reinforcement learning to real world systems. Currently, the incorporation of external knowledge such as human oversight is the only means to prevent the agent from visiting the catastrophic state. In this paper, we propose MBHI, a novel framework for safe model-based reinforcement learning, which ensures safety in the state-level and can effectively avoid both "local" and "non-local" catastrophes. An ensemble of supervised learners are trained in MBHI to imitate human blocking decisions. Similar to human decision-making process, MBHI will roll out an imagined trajectory in the dynamics model before executing actions to the environment, and estimate its safety. When the imagination encounters a catastrophe, MBHI will block the current action and use an efficient MPC method to output a safety policy. We evaluate our method on several safety tasks, and the results show that MBHI achieved better performance in terms of sample efficiency and number of catastrophes compared to the baselines.