 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign for Manufacturing: A Manufacturability Knowledge-Integrated Reinforcement Learning Framework for Free-Form Pipe Routing in Aeroengines
May 20, 2026Design for manufacturing plays a critical role in advanced aeroengine development, where complex components necessitate careful consideration of manufacturability. However, current practices in pipe routing remain largely decoupled from down-stream manufacturing, leading to labor-intensive, trial-and-error iterations to achieve manufacturable designs. To address this problem, this study proposes the Frenet-based pipe routing optimization (FPRO) framework, a manufacturability knowledge-integrated reinforcement learning approach for free-form pipe design in aeroengines. FPRO formulates the routing problem as a boundary value problem in the Frenet frame. In this framework, the pipe path is represented by curvature and torsion profiles, which are generated using cubic Hermite interpolation. To integrate design and manufacturing, domain-specific manufacturing knowledge is embedded as constraints on the permissible ranges of curvature and torsion. The path optimization is performed using the proximal policy optimization algorithm with stochastic exploration and a stage-guided reward mechanism. A unified mapping formulation then translates the optimized path into motion trajectories for the bending die, enabling direct fabrication on a six-axis free-bending machine. Experimental results demonstrate that FPRO consistently generates collision-free, manufacturable paths with smoother geometric profiles compared to Cartesian-based methods. It also achieves faster convergence and superior performance in terminal alignment, path length, obstacle avoidance, and manufacturability compared to state-of-the-art reinforcement learning baselines. Real-world validation confirms the close geometric correspondence between the manufactured pipe and its digital design, validating the practical feasibility of FPRO.
A Novel Garment Transfer Method Supervised by Distilled Knowledge of Virtual Try-on Model
Jan 23, 2024When a shopper chooses garments online, garment transfer technology wears the garment from the model image onto the shopper's image, allowing the shopper to decide whether the garment is suitable for them. As garment transfer leverages wild and cheap person image as garment condition, it has attracted tremendous community attention and holds vast commercial potential. However, since the ground truth of garment transfer is almost unavailable in reality, previous studies have treated garment transfer as either pose transfer or garment-pose disentanglement, and trained garment transfer in self-supervised learning, yet do not cover garment transfer intentions completely. Therefore, the training supervising the garment transfer is a rock-hard issue. Notably, virtual try-on technology has exhibited superior performance using self-supervised learning. We supervise the garment transfer training via knowledge distillation from virtual try-on. Specifically, we first train the transfer parsing reasoning model at multi-phases to provide shape guidance for downstream tasks. The transfer parsing reasoning model learns the response and feature knowledge from the try-on parsing reasoning model and absorbs the hard knowledge from the ground truth. By leveraging the warping knowledge from virtual try-on, we estimate a progressive flow to precisely warp the garment by learning the shape and content correspondence. To enhance transfer realism, we propose a well-designed arm regrowth task to infer exposed skin pixel content. Experiments demonstrate that our method has state-of-the-art performance in transferring garments between person compared with other virtual try-on and garment transfer methods.
Physical Logic Enhanced Network for Small-Sample Bi-Layer Metallic Tubes Bending Springback Prediction
Sep 20, 2022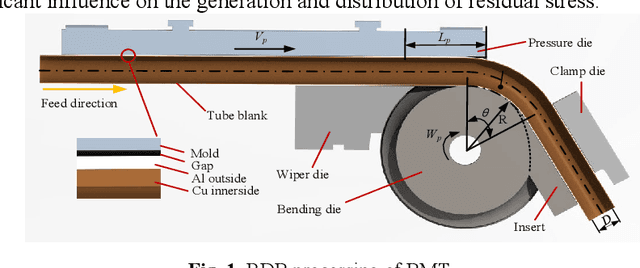

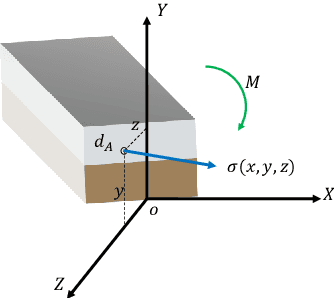

Bi-layer metallic tube (BMT) plays an extremely crucial role in engineering applications, with rotary draw bending (RDB) the high-precision bending processing can be achieved, however, the product will further springback. Due to the complex structure of BMT and the high cost of dataset acquisi-tion, the existing methods based on mechanism research and machine learn-ing cannot meet the engineering requirements of springback prediction. Based on the preliminary mechanism analysis, a physical logic enhanced network (PE-NET) is proposed. The architecture includes ES-NET which equivalent the BMT to the single-layer tube, and SP-NET for the final predic-tion of springback with sufficient single-layer tube samples. Specifically, in the first stage, with the theory-driven pre-exploration and the data-driven pretraining, the ES-NET and SP-NET are constructed, respectively. In the second stage, under the physical logic, the PE-NET is assembled by ES-NET and SP-NET and then fine-tuned with the small sample BMT dataset and composite loss function. The validity and stability of the proposed method are verified by the FE simulation dataset, the small-sample dataset BMT springback angle prediction is achieved, and the method potential in inter-pretability and engineering applications are demonstrated.
Task-Balanced Distillation for Object Detection
Aug 05, 2022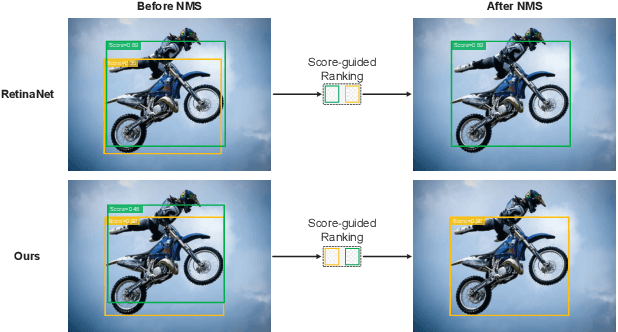

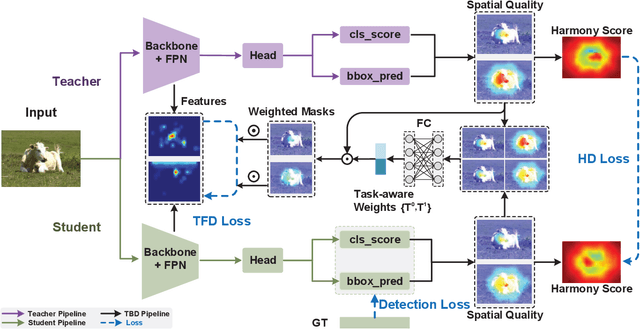
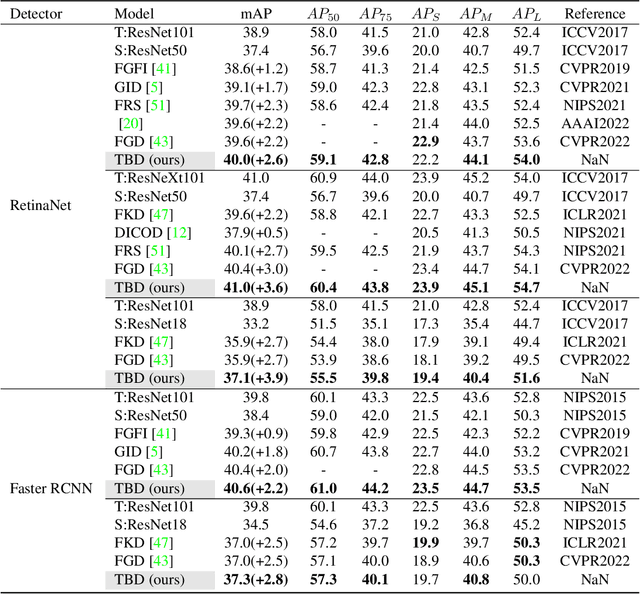
Mainstream object detectors are commonly constituted of two sub-tasks, including classification and regression tasks, implemented by two parallel heads. This classic design paradigm inevitably leads to inconsistent spatial distributions between classification score and localization quality (IOU). Therefore, this paper alleviates this misalignment in the view of knowledge distillation. First, we observe that the massive teacher achieves a higher proportion of harmonious predictions than the lightweight student. Based on this intriguing observation, a novel Harmony Score (HS) is devised to estimate the alignment of classification and regression qualities. HS models the relationship between two sub-tasks and is seen as prior knowledge to promote harmonious predictions for the student. Second, this spatial misalignment will result in inharmonious region selection when distilling features. To alleviate this problem, a novel Task-decoupled Feature Distillation (TFD) is proposed by flexibly balancing the contributions of classification and regression tasks. Eventually, HD and TFD constitute the proposed method, named Task-Balanced Distillation (TBD). Extensive experiments demonstrate the considerable potential and generalization of the proposed method. Specifically, when equipped with TBD, RetinaNet with ResNet-50 achieves 41.0 mAP under the COCO benchmark, outperforming the recent FGD and FRS.
Digital-twin-enhanced metal tube bending forming real-time prediction method based on Multi-source-input MTL
Jul 03, 2022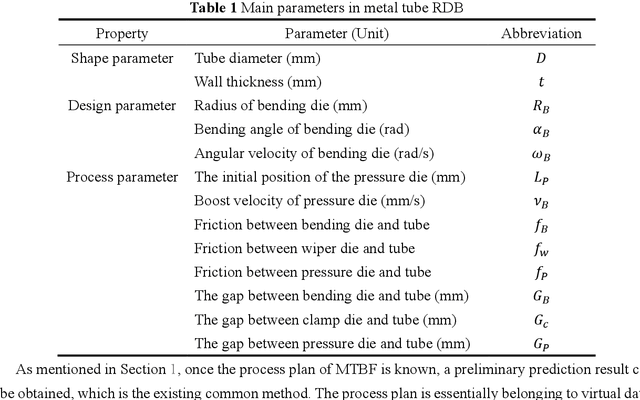



As one of the most widely used metal tube bending methods, the rotary draw bending (RDB) process enables reliable and high-precision metal tube bending forming (MTBF). The forming accuracy is seriously affected by the springback and other potential forming defects, of which the mechanism analysis is difficult to deal with. At the same time, the existing methods are mainly conducted in offline space, ignoring the real-time information in the physical world, which is unreliable and inefficient. To address this issue, a digital-twin-enhanced (DT-enhanced) metal tube bending forming real-time prediction method based on multi-source-input multi-task learning (MTL) is proposed. The new method can achieve comprehensive MTBF real-time prediction. By sharing the common feature of the multi-close domain and adopting group regularization strategy on feature sharing and accepting layers, the accuracy and efficiency of the multi-source-input MTL can be guaranteed. Enhanced by DT, the physical real-time deformation data is aligned in the image dimension by an improved Grammy Angle Field (GAF) conversion, realizing the reflection of the actual processing. Different from the traditional offline prediction methods, the new method integrates the virtual and physical data to achieve a more efficient and accurate real-time prediction result. and the DT mapping connection between virtual and physical systems can be achieved. To exclude the effects of equipment errors, the effectiveness of the proposed method is verified on the physical experiment-verified FE simulation scenarios. At the same time, the common pre-training networks are compared with the proposed method. The results show that the proposed DT-enhanced prediction method is more accurate and efficient.
Look Before You Leap: Safe Model-Based Reinforcement Learning with Human Intervention
Nov 16, 2021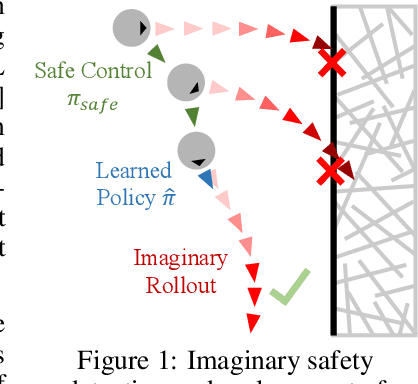
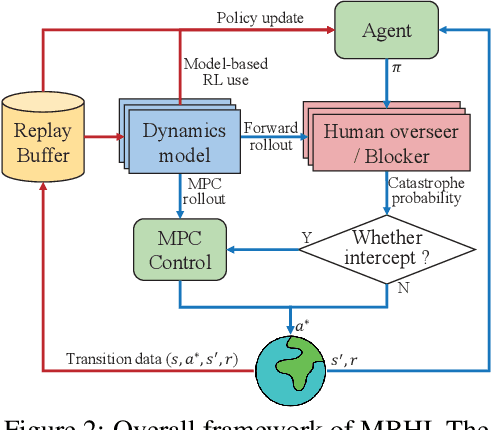
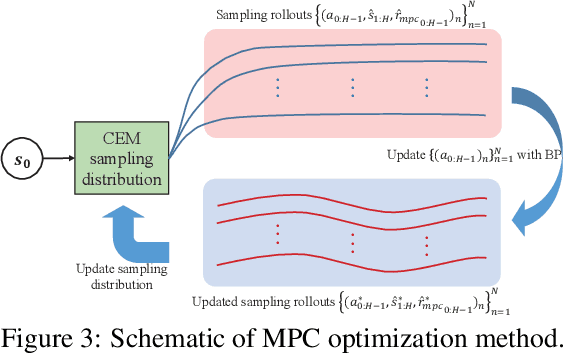
Safety has become one of the main challenges of applying deep reinforcement learning to real world systems. Currently, the incorporation of external knowledge such as human oversight is the only means to prevent the agent from visiting the catastrophic state. In this paper, we propose MBHI, a novel framework for safe model-based reinforcement learning, which ensures safety in the state-level and can effectively avoid both "local" and "non-local" catastrophes. An ensemble of supervised learners are trained in MBHI to imitate human blocking decisions. Similar to human decision-making process, MBHI will roll out an imagined trajectory in the dynamics model before executing actions to the environment, and estimate its safety. When the imagination encounters a catastrophe, MBHI will block the current action and use an efficient MPC method to output a safety policy. We evaluate our method on several safety tasks, and the results show that MBHI achieved better performance in terms of sample efficiency and number of catastrophes compared to the baselines.