 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAD-Judge: Toward Efficient Morphological Grading and Verification for Text-to-CAD Generation
Aug 06, 2025Computer-Aided Design (CAD) models are widely used across industrial design, simulation, and manufacturing processes. Text-to-CAD systems aim to generate editable, general-purpose CAD models from textual descriptions, significantly reducing the complexity and entry barrier associated with traditional CAD workflows. However, rendering CAD models can be slow, and deploying VLMs to review CAD models can be expensive and may introduce reward hacking that degrades the systems. To address these challenges, we propose CAD-Judge, a novel, verifiable reward system for efficient and effective CAD preference grading and grammatical validation. We adopt the Compiler-as-a-Judge Module (CJM) as a fast, direct reward signal, optimizing model alignment by maximizing generative utility through prospect theory. To further improve the robustness of Text-to-CAD in the testing phase, we introduce a simple yet effective agentic CAD generation approach and adopt the Compiler-as-a-Review Module (CRM), which efficiently verifies the generated CAD models, enabling the system to refine them accordingly. Extensive experiments on challenging CAD datasets demonstrate that our method achieves state-of-the-art performance while maintaining superior efficiency.
DSOcc: Leveraging Depth Awareness and Semantic Aid to Boost Camera-Based 3D Semantic Occupancy Prediction
May 27, 2025Camera-based 3D semantic occupancy prediction offers an efficient and cost-effective solution for perceiving surrounding scenes in autonomous driving. However, existing works rely on explicit occupancy state inference, leading to numerous incorrect feature assignments, and insufficient samples restrict the learning of occupancy class inference. To address these challenges, we propose leveraging Depth awareness and Semantic aid to boost camera-based 3D semantic Occupancy prediction (DSOcc). We jointly perform occupancy state and occupancy class inference, where soft occupancy confidence is calculated through non-learning method and multiplied with image features to make the voxel representation aware of depth, enabling adaptive implicit occupancy state inference. Rather than focusing on improving feature learning, we directly utilize well-trained image semantic segmentation and fuse multiple frames with their occupancy probabilities to aid occupancy class inference, thereby enhancing robustness. Experimental results demonstrate that DSOcc achieves state-of-the-art performance on the SemanticKITTI dataset among camera-based methods.
R3D-AD: Reconstruction via Diffusion for 3D Anomaly Detection
Jul 15, 2024



3D anomaly detection plays a crucial role in monitoring parts for localized inherent defects in precision manufacturing. Embedding-based and reconstruction-based approaches are among the most popular and successful methods. However, there are two major challenges to the practical application of the current approaches: 1) the embedded models suffer the prohibitive computational and storage due to the memory bank structure; 2) the reconstructive models based on the MAE mechanism fail to detect anomalies in the unmasked regions. In this paper, we propose R3D-AD, reconstructing anomalous point clouds by diffusion model for precise 3D anomaly detection. Our approach capitalizes on the data distribution conversion of the diffusion process to entirely obscure the input's anomalous geometry. It step-wisely learns a strict point-level displacement behavior, which methodically corrects the aberrant points. To increase the generalization of the model, we further present a novel 3D anomaly simulation strategy named Patch-Gen to generate realistic and diverse defect shapes, which narrows the domain gap between training and testing. Our R3D-AD ensures a uniform spatial transformation, which allows straightforwardly generating anomaly results by distance comparison. Extensive experiments show that our R3D-AD outperforms previous state-of-the-art methods, achieving 73.4% Image-level AUROC on the Real3D-AD dataset and 74.9% Image-level AUROC on the Anomaly-ShapeNet dataset with an exceptional efficiency.
A Novel Garment Transfer Method Supervised by Distilled Knowledge of Virtual Try-on Model
Jan 23, 2024When a shopper chooses garments online, garment transfer technology wears the garment from the model image onto the shopper's image, allowing the shopper to decide whether the garment is suitable for them. As garment transfer leverages wild and cheap person image as garment condition, it has attracted tremendous community attention and holds vast commercial potential. However, since the ground truth of garment transfer is almost unavailable in reality, previous studies have treated garment transfer as either pose transfer or garment-pose disentanglement, and trained garment transfer in self-supervised learning, yet do not cover garment transfer intentions completely. Therefore, the training supervising the garment transfer is a rock-hard issue. Notably, virtual try-on technology has exhibited superior performance using self-supervised learning. We supervise the garment transfer training via knowledge distillation from virtual try-on. Specifically, we first train the transfer parsing reasoning model at multi-phases to provide shape guidance for downstream tasks. The transfer parsing reasoning model learns the response and feature knowledge from the try-on parsing reasoning model and absorbs the hard knowledge from the ground truth. By leveraging the warping knowledge from virtual try-on, we estimate a progressive flow to precisely warp the garment by learning the shape and content correspondence. To enhance transfer realism, we propose a well-designed arm regrowth task to infer exposed skin pixel content. Experiments demonstrate that our method has state-of-the-art performance in transferring garments between person compared with other virtual try-on and garment transfer methods.
GSDC Transformer: An Efficient and Effective Cue Fusion for Monocular Multi-Frame Depth Estimation
Sep 29, 2023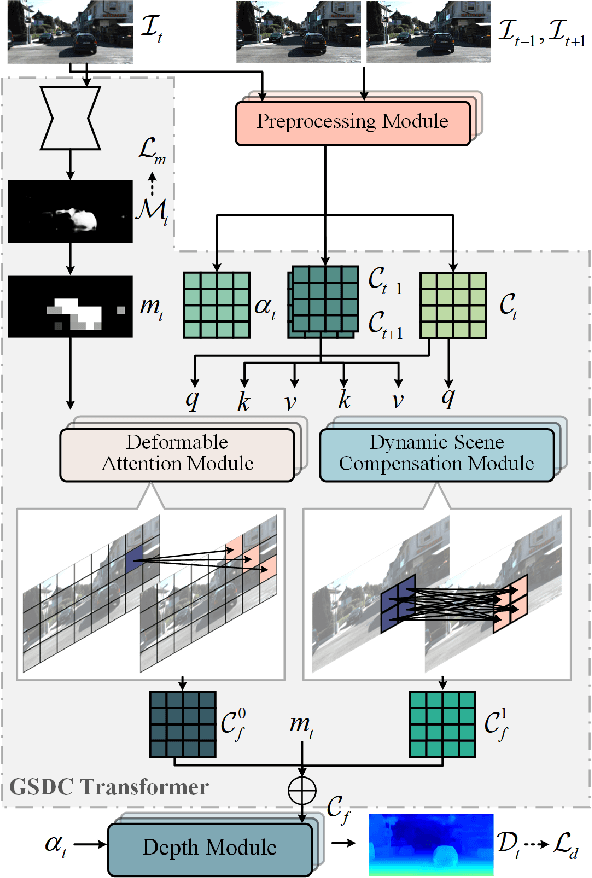
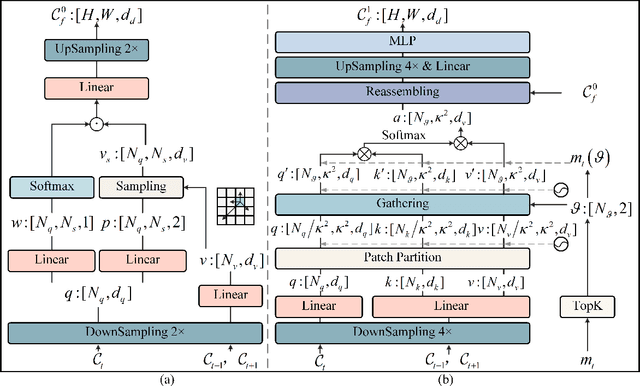
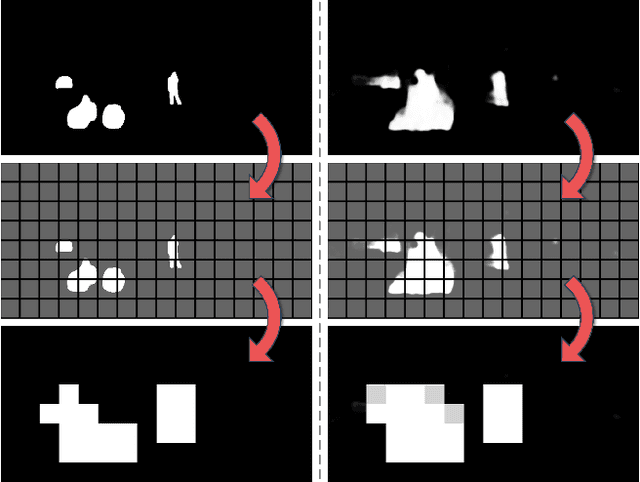
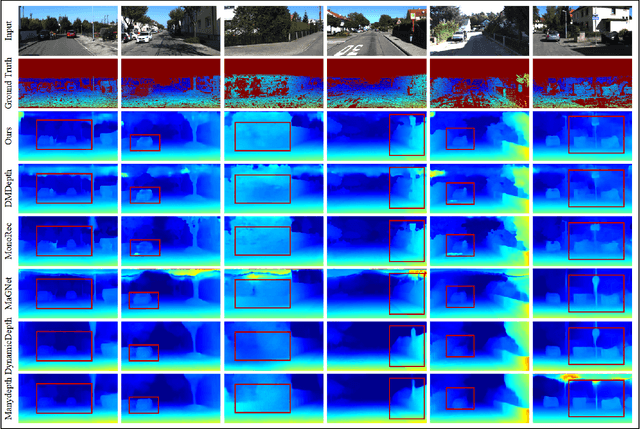
Depth estimation provides an alternative approach for perceiving 3D information in autonomous driving. Monocular depth estimation, whether with single-frame or multi-frame inputs, has achieved significant success by learning various types of cues and specializing in either static or dynamic scenes. Recently, these cues fusion becomes an attractive topic, aiming to enable the combined cues to perform well in both types of scenes. However, adaptive cue fusion relies on attention mechanisms, where the quadratic complexity limits the granularity of cue representation. Additionally, explicit cue fusion depends on precise segmentation, which imposes a heavy burden on mask prediction. To address these issues, we propose the GSDC Transformer, an efficient and effective component for cue fusion in monocular multi-frame depth estimation. We utilize deformable attention to learn cue relationships at a fine scale, while sparse attention reduces computational requirements when granularity increases. To compensate for the precision drop in dynamic scenes, we represent scene attributes in the form of super tokens without relying on precise shapes. Within each super token attributed to dynamic scenes, we gather its relevant cues and learn local dense relationships to enhance cue fusion. Our method achieves state-of-the-art performance on the KITTI dataset with efficient fusion speed.
PG-VTON: A Novel Image-Based Virtual Try-On Method via Progressive Inference Paradigm
Apr 18, 2023Virtual try-on is a promising computer vision topic with a high commercial value wherein a new garment is visually worn on a person with a photo-realistic effect. Previous studies conduct their shape and content inference at one stage, employing a single-scale warping mechanism and a relatively unsophisticated content inference mechanism. These approaches have led to suboptimal results in terms of garment warping and skin reservation under challenging try-on scenarios. To address these limitations, we propose a novel virtual try-on method via progressive inference paradigm (PGVTON) that leverages a top-down inference pipeline and a general garment try-on strategy. Specifically, we propose a robust try-on parsing inference method by disentangling semantic categories and introducing consistency. Exploiting the try-on parsing as the shape guidance, we implement the garment try-on via warping-mapping-composition. To facilitate adaptation to a wide range of try-on scenarios, we adopt a covering more and selecting one warping strategy and explicitly distinguish tasks based on alignment. Additionally, we regulate StyleGAN2 to implement re-naked skin inpainting, conditioned on the target skin shape and spatial-agnostic skin features. Experiments demonstrate that our method has state-of-the-art performance under two challenging scenarios. The code will be available at https://github.com/NerdFNY/PGVTON.
A Cross-Scale Hierarchical Transformer with Correspondence-Augmented Attention for inferring Bird's-Eye-View Semantic Segmentation
Apr 07, 2023As bird's-eye-view (BEV) semantic segmentation is simple-to-visualize and easy-to-handle, it has been applied in autonomous driving to provide the surrounding information to downstream tasks. Inferring BEV semantic segmentation conditioned on multi-camera-view images is a popular scheme in the community as cheap devices and real-time processing. The recent work implemented this task by learning the content and position relationship via the vision Transformer (ViT). However, the quadratic complexity of ViT confines the relationship learning only in the latent layer, leaving the scale gap to impede the representation of fine-grained objects. And their plain fusion method of multi-view features does not conform to the information absorption intention in representing BEV features. To tackle these issues, we propose a novel cross-scale hierarchical Transformer with correspondence-augmented attention for semantic segmentation inferring. Specifically, we devise a hierarchical framework to refine the BEV feature representation, where the last size is only half of the final segmentation. To save the computation increase caused by this hierarchical framework, we exploit the cross-scale Transformer to learn feature relationships in a reversed-aligning way, and leverage the residual connection of BEV features to facilitate information transmission between scales. We propose correspondence-augmented attention to distinguish conducive and inconducive correspondences. It is implemented in a simple yet effective way, amplifying attention scores before the Softmax operation, so that the position-view-related and the position-view-disrelated attention scores are highlighted and suppressed. Extensive experiments demonstrate that our method has state-of-the-art performance in inferring BEV semantic segmentation conditioned on multi-camera-view images.
Physical Logic Enhanced Network for Small-Sample Bi-Layer Metallic Tubes Bending Springback Prediction
Sep 20, 2022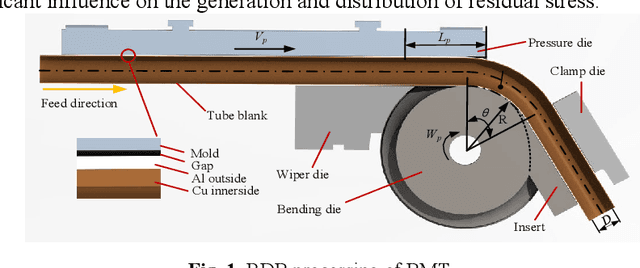

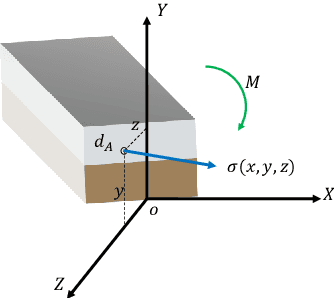

Bi-layer metallic tube (BMT) plays an extremely crucial role in engineering applications, with rotary draw bending (RDB) the high-precision bending processing can be achieved, however, the product will further springback. Due to the complex structure of BMT and the high cost of dataset acquisi-tion, the existing methods based on mechanism research and machine learn-ing cannot meet the engineering requirements of springback prediction. Based on the preliminary mechanism analysis, a physical logic enhanced network (PE-NET) is proposed. The architecture includes ES-NET which equivalent the BMT to the single-layer tube, and SP-NET for the final predic-tion of springback with sufficient single-layer tube samples. Specifically, in the first stage, with the theory-driven pre-exploration and the data-driven pretraining, the ES-NET and SP-NET are constructed, respectively. In the second stage, under the physical logic, the PE-NET is assembled by ES-NET and SP-NET and then fine-tuned with the small sample BMT dataset and composite loss function. The validity and stability of the proposed method are verified by the FE simulation dataset, the small-sample dataset BMT springback angle prediction is achieved, and the method potential in inter-pretability and engineering applications are demonstrated.
Digital-twin-enhanced metal tube bending forming real-time prediction method based on Multi-source-input MTL
Jul 03, 2022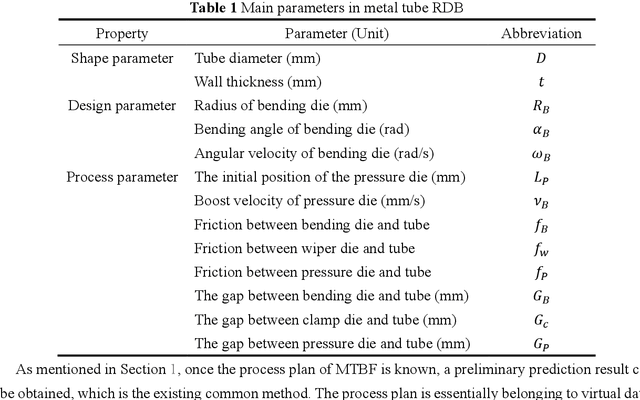



As one of the most widely used metal tube bending methods, the rotary draw bending (RDB) process enables reliable and high-precision metal tube bending forming (MTBF). The forming accuracy is seriously affected by the springback and other potential forming defects, of which the mechanism analysis is difficult to deal with. At the same time, the existing methods are mainly conducted in offline space, ignoring the real-time information in the physical world, which is unreliable and inefficient. To address this issue, a digital-twin-enhanced (DT-enhanced) metal tube bending forming real-time prediction method based on multi-source-input multi-task learning (MTL) is proposed. The new method can achieve comprehensive MTBF real-time prediction. By sharing the common feature of the multi-close domain and adopting group regularization strategy on feature sharing and accepting layers, the accuracy and efficiency of the multi-source-input MTL can be guaranteed. Enhanced by DT, the physical real-time deformation data is aligned in the image dimension by an improved Grammy Angle Field (GAF) conversion, realizing the reflection of the actual processing. Different from the traditional offline prediction methods, the new method integrates the virtual and physical data to achieve a more efficient and accurate real-time prediction result. and the DT mapping connection between virtual and physical systems can be achieved. To exclude the effects of equipment errors, the effectiveness of the proposed method is verified on the physical experiment-verified FE simulation scenarios. At the same time, the common pre-training networks are compared with the proposed method. The results show that the proposed DT-enhanced prediction method is more accurate and efficient.