 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIN-VLA: Modeling Abstraction of Intention and eNvironment for Vision-Language-Action Models
Feb 02, 2026Despite significant progress in Visual-Language-Action (VLA), in highly complex and dynamic environments that involve real-time unpredictable interactions (such as 3D open worlds and large-scale PvP games), existing approaches remain inefficient at extracting action-critical signals from redundant sensor streams. To tackle this, we introduce MAIN-VLA, a framework that explicitly Models the Abstraction of Intention and eNvironment to ground decision-making in deep semantic alignment rather than superficial pattern matching. Specifically, our Intention Abstraction (IA) extracts verbose linguistic instructions and their associated reasoning into compact, explicit semantic primitives, while the Environment Semantics Abstraction (ESA) projects overwhelming visual streams into a structured, topological affordance representation. Furthermore, aligning these two abstract modalities induces an emergent attention-concentration effect, enabling a parameter-free token-pruning strategy that filters out perceptual redundancy without degrading performance. Extensive experiments in open-world Minecraft and large-scale PvP environments (Game for Peace and Valorant) demonstrate that MAIN-VLA sets a new state-of-the-art, which achieves superior decision quality, stronger generalization, and cutting-edge inference efficiency.
CAE: Character-Level Autoencoder for Non-Semantic Relational Data Grouping
Nov 10, 2025Enterprise relational databases increasingly contain vast amounts of non-semantic data - IP addresses, product identifiers, encoded keys, and timestamps - that challenge traditional semantic analysis. This paper introduces a novel Character-Level Autoencoder (CAE) approach that automatically identifies and groups semantically identical columns in non-semantic relational datasets by detecting column similarities based on data patterns and structures. Unlike conventional Natural Language Processing (NLP) models that struggle with limitations in semantic interpretability and out-of-vocabulary tokens, our approach operates at the character level with fixed dictionary constraints, enabling scalable processing of large-scale data lakes and warehouses. The CAE architecture encodes text representations of non-semantic relational table columns and extracts high-dimensional feature embeddings for data grouping. By maintaining a fixed dictionary size, our method significantly reduces both memory requirements and training time, enabling efficient processing of large-scale industrial data environments. Experimental evaluation demonstrates substantial performance gains: our CAE approach achieved 80.95% accuracy in top 5 column matching tasks across relational datasets, substantially outperforming traditional NLP approaches such as Bag of Words (47.62%). These results demonstrate its effectiveness for identifying and clustering identical columns in relational datasets. This work bridges the gap between theoretical advances in character-level neural architectures and practical enterprise data management challenges, providing an automated solution for schema understanding and data profiling of non-semantic industrial datasets at scale.
CAD-Judge: Toward Efficient Morphological Grading and Verification for Text-to-CAD Generation
Aug 06, 2025Computer-Aided Design (CAD) models are widely used across industrial design, simulation, and manufacturing processes. Text-to-CAD systems aim to generate editable, general-purpose CAD models from textual descriptions, significantly reducing the complexity and entry barrier associated with traditional CAD workflows. However, rendering CAD models can be slow, and deploying VLMs to review CAD models can be expensive and may introduce reward hacking that degrades the systems. To address these challenges, we propose CAD-Judge, a novel, verifiable reward system for efficient and effective CAD preference grading and grammatical validation. We adopt the Compiler-as-a-Judge Module (CJM) as a fast, direct reward signal, optimizing model alignment by maximizing generative utility through prospect theory. To further improve the robustness of Text-to-CAD in the testing phase, we introduce a simple yet effective agentic CAD generation approach and adopt the Compiler-as-a-Review Module (CRM), which efficiently verifies the generated CAD models, enabling the system to refine them accordingly. Extensive experiments on challenging CAD datasets demonstrate that our method achieves state-of-the-art performance while maintaining superior efficiency.
OccLE: Label-Efficient 3D Semantic Occupancy Prediction
May 27, 2025
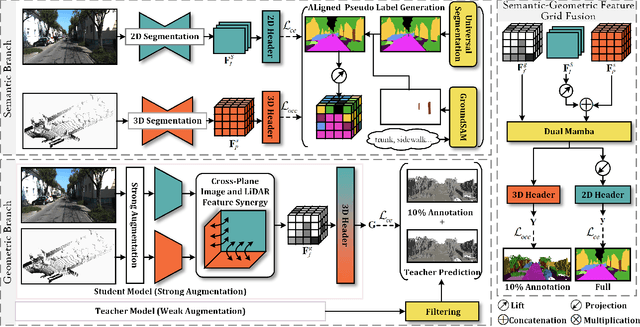
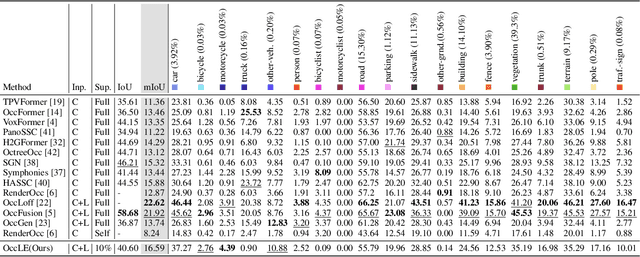
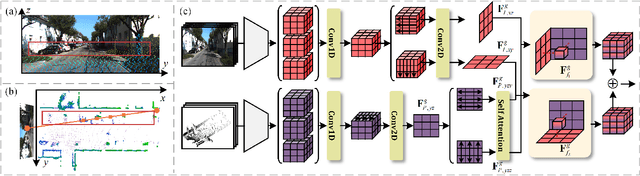
3D semantic occupancy prediction offers an intuitive and efficient scene understanding and has attracted significant interest in autonomous driving perception. Existing approaches either rely on full supervision, which demands costly voxel-level annotations, or on self-supervision, which provides limited guidance and yields suboptimal performance. To address these challenges, we propose OccLE, a Label-Efficient 3D Semantic Occupancy Prediction that takes images and LiDAR as inputs and maintains high performance with limited voxel annotations. Our intuition is to decouple the semantic and geometric learning tasks and then fuse the learned feature grids from both tasks for the final semantic occupancy prediction. Therefore, the semantic branch distills 2D foundation model to provide aligned pseudo labels for 2D and 3D semantic learning. The geometric branch integrates image and LiDAR inputs in cross-plane synergy based on their inherency, employing semi-supervision to enhance geometry learning. We fuse semantic-geometric feature grids through Dual Mamba and incorporate a scatter-accumulated projection to supervise unannotated prediction with aligned pseudo labels. Experiments show that OccLE achieves competitive performance with only 10% of voxel annotations, reaching a mIoU of 16.59% on the SemanticKITTI validation set.
DSOcc: Leveraging Depth Awareness and Semantic Aid to Boost Camera-Based 3D Semantic Occupancy Prediction
May 27, 2025Camera-based 3D semantic occupancy prediction offers an efficient and cost-effective solution for perceiving surrounding scenes in autonomous driving. However, existing works rely on explicit occupancy state inference, leading to numerous incorrect feature assignments, and insufficient samples restrict the learning of occupancy class inference. To address these challenges, we propose leveraging Depth awareness and Semantic aid to boost camera-based 3D semantic Occupancy prediction (DSOcc). We jointly perform occupancy state and occupancy class inference, where soft occupancy confidence is calculated through non-learning method and multiplied with image features to make the voxel representation aware of depth, enabling adaptive implicit occupancy state inference. Rather than focusing on improving feature learning, we directly utilize well-trained image semantic segmentation and fuse multiple frames with their occupancy probabilities to aid occupancy class inference, thereby enhancing robustness. Experimental results demonstrate that DSOcc achieves state-of-the-art performance on the SemanticKITTI dataset among camera-based methods.
R3D-AD: Reconstruction via Diffusion for 3D Anomaly Detection
Jul 15, 2024



3D anomaly detection plays a crucial role in monitoring parts for localized inherent defects in precision manufacturing. Embedding-based and reconstruction-based approaches are among the most popular and successful methods. However, there are two major challenges to the practical application of the current approaches: 1) the embedded models suffer the prohibitive computational and storage due to the memory bank structure; 2) the reconstructive models based on the MAE mechanism fail to detect anomalies in the unmasked regions. In this paper, we propose R3D-AD, reconstructing anomalous point clouds by diffusion model for precise 3D anomaly detection. Our approach capitalizes on the data distribution conversion of the diffusion process to entirely obscure the input's anomalous geometry. It step-wisely learns a strict point-level displacement behavior, which methodically corrects the aberrant points. To increase the generalization of the model, we further present a novel 3D anomaly simulation strategy named Patch-Gen to generate realistic and diverse defect shapes, which narrows the domain gap between training and testing. Our R3D-AD ensures a uniform spatial transformation, which allows straightforwardly generating anomaly results by distance comparison. Extensive experiments show that our R3D-AD outperforms previous state-of-the-art methods, achieving 73.4% Image-level AUROC on the Real3D-AD dataset and 74.9% Image-level AUROC on the Anomaly-ShapeNet dataset with an exceptional efficiency.
GSDC Transformer: An Efficient and Effective Cue Fusion for Monocular Multi-Frame Depth Estimation
Sep 29, 2023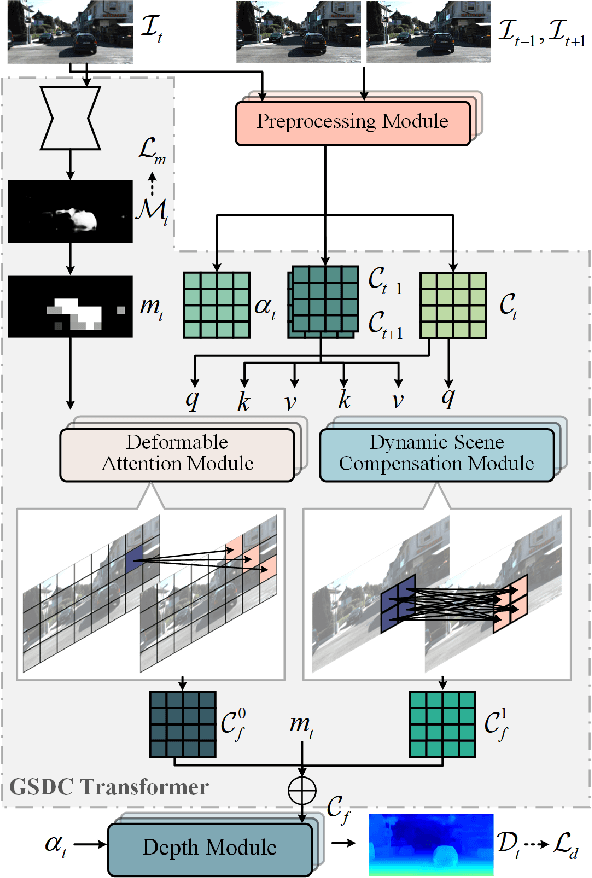
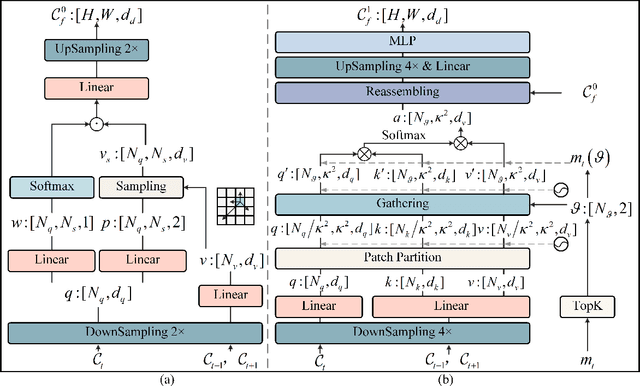
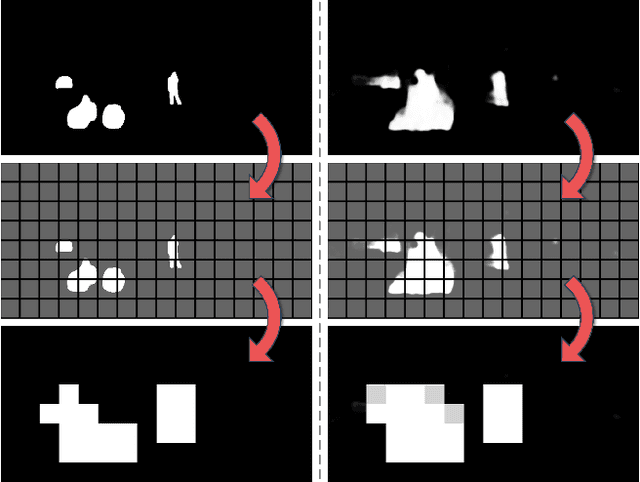
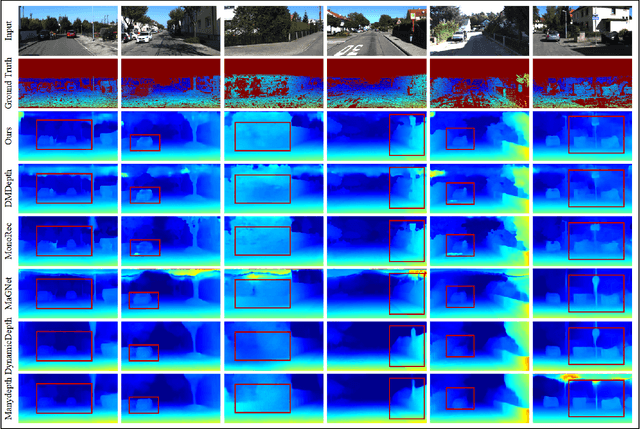
Depth estimation provides an alternative approach for perceiving 3D information in autonomous driving. Monocular depth estimation, whether with single-frame or multi-frame inputs, has achieved significant success by learning various types of cues and specializing in either static or dynamic scenes. Recently, these cues fusion becomes an attractive topic, aiming to enable the combined cues to perform well in both types of scenes. However, adaptive cue fusion relies on attention mechanisms, where the quadratic complexity limits the granularity of cue representation. Additionally, explicit cue fusion depends on precise segmentation, which imposes a heavy burden on mask prediction. To address these issues, we propose the GSDC Transformer, an efficient and effective component for cue fusion in monocular multi-frame depth estimation. We utilize deformable attention to learn cue relationships at a fine scale, while sparse attention reduces computational requirements when granularity increases. To compensate for the precision drop in dynamic scenes, we represent scene attributes in the form of super tokens without relying on precise shapes. Within each super token attributed to dynamic scenes, we gather its relevant cues and learn local dense relationships to enhance cue fusion. Our method achieves state-of-the-art performance on the KITTI dataset with efficient fusion speed.
SUIT: Learning Significance-guided Information for 3D Temporal Detection
Jul 04, 2023



3D object detection from LiDAR point cloud is of critical importance for autonomous driving and robotics. While sequential point cloud has the potential to enhance 3D perception through temporal information, utilizing these temporal features effectively and efficiently remains a challenging problem. Based on the observation that the foreground information is sparsely distributed in LiDAR scenes, we believe sufficient knowledge can be provided by sparse format rather than dense maps. To this end, we propose to learn Significance-gUided Information for 3D Temporal detection (SUIT), which simplifies temporal information as sparse features for information fusion across frames. Specifically, we first introduce a significant sampling mechanism that extracts information-rich yet sparse features based on predicted object centroids. On top of that, we present an explicit geometric transformation learning technique, which learns the object-centric transformations among sparse features across frames. We evaluate our method on large-scale nuScenes and Waymo dataset, where our SUIT not only significantly reduces the memory and computation cost of temporal fusion, but also performs well over the state-of-the-art baselines.
Learning Ego 3D Representation as Ray Tracing
Jun 08, 2022
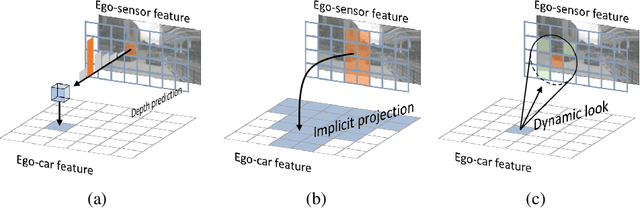

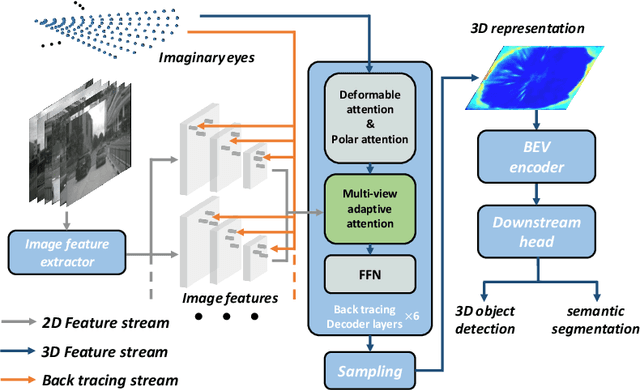
A self-driving perception model aims to extract 3D semantic representations from multiple cameras collectively into the bird's-eye-view (BEV) coordinate frame of the ego car in order to ground downstream planner. Existing perception methods often rely on error-prone depth estimation of the whole scene or learning sparse virtual 3D representations without the target geometry structure, both of which remain limited in performance and/or capability. In this paper, we present a novel end-to-end architecture for ego 3D representation learning from an arbitrary number of unconstrained camera views. Inspired by the ray tracing principle, we design a polarized grid of "imaginary eyes" as the learnable ego 3D representation and formulate the learning process with the adaptive attention mechanism in conjunction with the 3D-to-2D projection. Critically, this formulation allows extracting rich 3D representation from 2D images without any depth supervision, and with the built-in geometry structure consistent w.r.t. BEV. Despite its simplicity and versatility, extensive experiments on standard BEV visual tasks (e.g., camera-based 3D object detection and BEV segmentation) show that our model outperforms all state-of-the-art alternatives significantly, with an extra advantage in computational efficiency from multi-task learning.
SGM3D: Stereo Guided Monocular 3D Object Detection
Dec 03, 2021
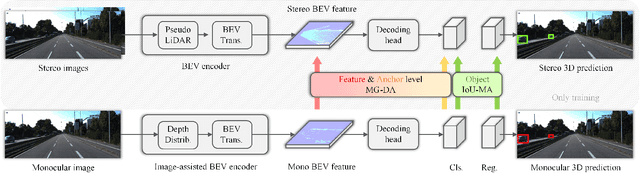
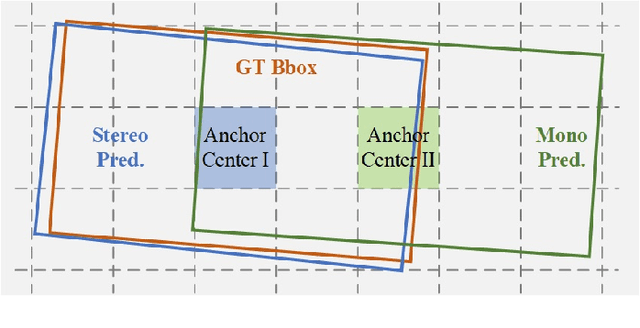

Monocular 3D object detection is a critical yet challenging task for autonomous driving, due to the lack of accurate depth information captured by LiDAR sensors. In this paper, we propose a stereo-guided monocular 3D object detection network, termed SGM3D, which leverages robust 3D features extracted from stereo images to enhance the features learned from the monocular image. We innovatively investigate a multi-granularity domain adaptation module (MG-DA) to exploit the network's ability so as to generate stereo-mimic features only based on the monocular cues. The coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are leveraged to guide the monocular branch. We present an IoU matching-based alignment module (IoU-MA) for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches in previous stages. We conduct extensive experiments on the most challenging KITTI and Lyft datasets and achieve new state-of-the-art performance. Furthermore, our method can be integrated into many other monocular approaches to boost performance without introducing any extra computational cost.