 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Compositional Generalization in LLMs for Smart Contract Security: A Case Study on Reentrancy Vulnerabilities
Jan 11, 2026Large language models (LLMs) demonstrate remarkable capabilities in natural language understanding and generation. Despite being trained on large-scale, high-quality data, LLMs still fail to outperform traditional static analysis tools in specialized domains like smart contract vulnerability detection. To address this issue, this paper proposes a post-training algorithm based on atomic task decomposition and fusion. This algorithm aims to achieve combinatorial generalization under limited data by decomposing complex reasoning tasks. Specifically, we decompose the reentrancy vulnerability detection task into four linearly independent atomic tasks: identifying external calls, identifying state updates, identifying data dependencies between external calls and state updates, and determining their data flow order. These tasks form the core components of our approach. By training on synthetic datasets, we generate three compiler-verified datasets. We then employ the Slither tool to extract structural information from the control flow graph and data flow graph, which is used to fine-tune the LLM's adapter. Experimental results demonstrate that low-rank normalization fusion with the LoRA adapter improves the LLM's reentrancy vulnerability detection accuracy to 98.2%, surpassing state-of-the-art methods. On 31 real-world contracts, the algorithm achieves a 20% higher recall than traditional analysis tools.
Puppeteer: Rig and Animate Your 3D Models
Aug 14, 2025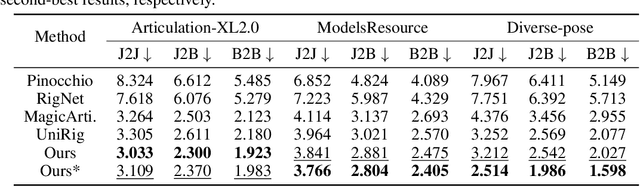

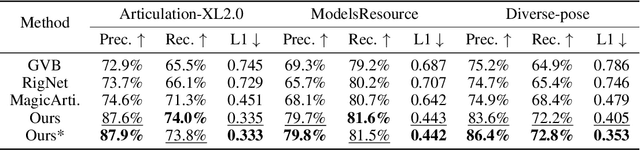

Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
OccLE: Label-Efficient 3D Semantic Occupancy Prediction
May 27, 2025
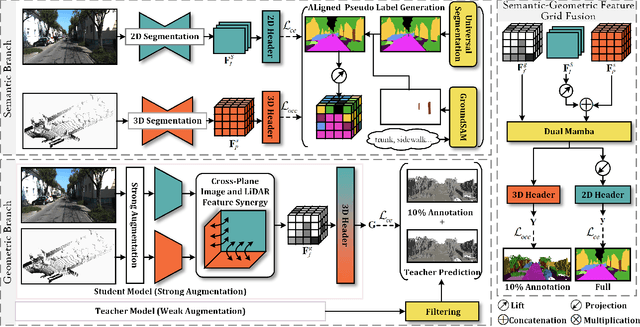
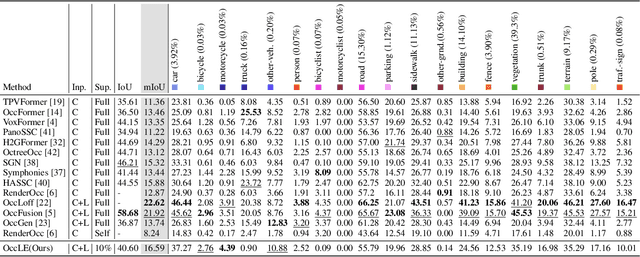
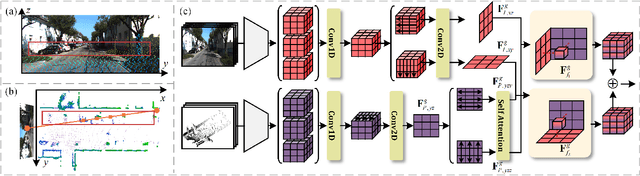
3D semantic occupancy prediction offers an intuitive and efficient scene understanding and has attracted significant interest in autonomous driving perception. Existing approaches either rely on full supervision, which demands costly voxel-level annotations, or on self-supervision, which provides limited guidance and yields suboptimal performance. To address these challenges, we propose OccLE, a Label-Efficient 3D Semantic Occupancy Prediction that takes images and LiDAR as inputs and maintains high performance with limited voxel annotations. Our intuition is to decouple the semantic and geometric learning tasks and then fuse the learned feature grids from both tasks for the final semantic occupancy prediction. Therefore, the semantic branch distills 2D foundation model to provide aligned pseudo labels for 2D and 3D semantic learning. The geometric branch integrates image and LiDAR inputs in cross-plane synergy based on their inherency, employing semi-supervision to enhance geometry learning. We fuse semantic-geometric feature grids through Dual Mamba and incorporate a scatter-accumulated projection to supervise unannotated prediction with aligned pseudo labels. Experiments show that OccLE achieves competitive performance with only 10% of voxel annotations, reaching a mIoU of 16.59% on the SemanticKITTI validation set.
CADCrafter: Generating Computer-Aided Design Models from Unconstrained Images
Apr 10, 2025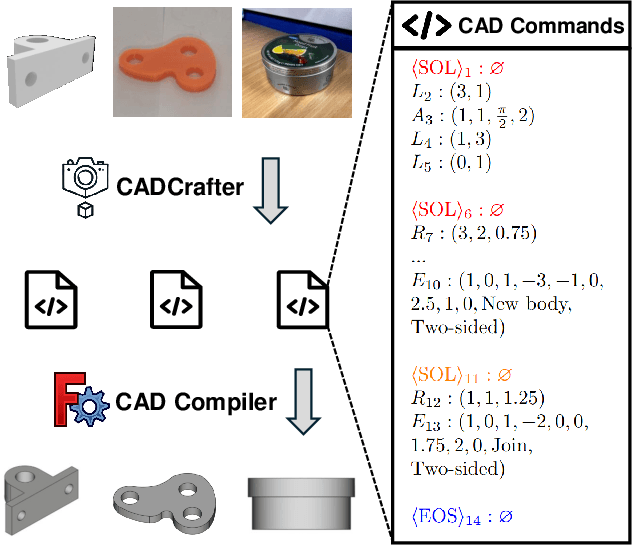
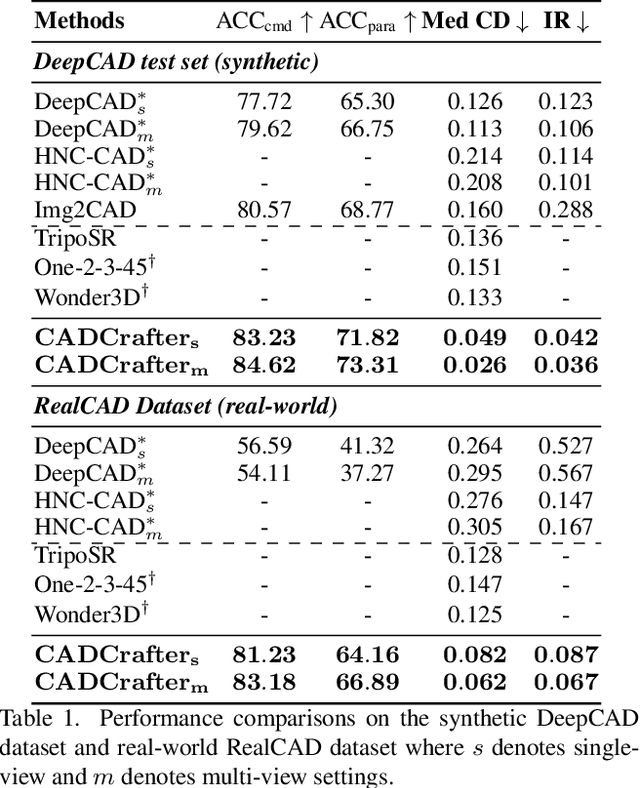
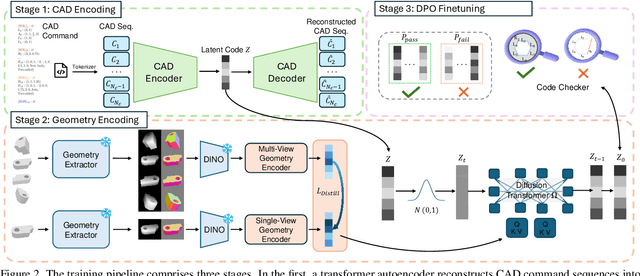
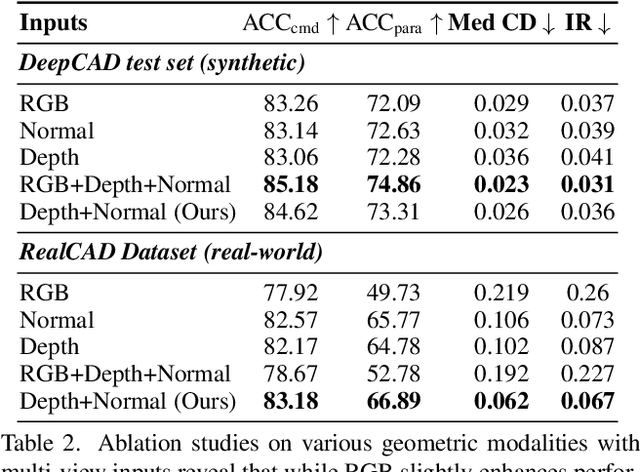
Creating CAD digital twins from the physical world is crucial for manufacturing, design, and simulation. However, current methods typically rely on costly 3D scanning with labor-intensive post-processing. To provide a user-friendly design process, we explore the problem of reverse engineering from unconstrained real-world CAD images that can be easily captured by users of all experiences. However, the scarcity of real-world CAD data poses challenges in directly training such models. To tackle these challenges, we propose CADCrafter, an image-to-parametric CAD model generation framework that trains solely on synthetic textureless CAD data while testing on real-world images. To bridge the significant representation disparity between images and parametric CAD models, we introduce a geometry encoder to accurately capture diverse geometric features. Moreover, the texture-invariant properties of the geometric features can also facilitate the generalization to real-world scenarios. Since compiling CAD parameter sequences into explicit CAD models is a non-differentiable process, the network training inherently lacks explicit geometric supervision. To impose geometric validity constraints, we employ direct preference optimization (DPO) to fine-tune our model with the automatic code checker feedback on CAD sequence quality. Furthermore, we collected a real-world dataset, comprised of multi-view images and corresponding CAD command sequence pairs, to evaluate our method. Experimental results demonstrate that our approach can robustly handle real unconstrained CAD images, and even generalize to unseen general objects.
Prim2Room: Layout-Controllable Room Mesh Generation from Primitives
Sep 09, 2024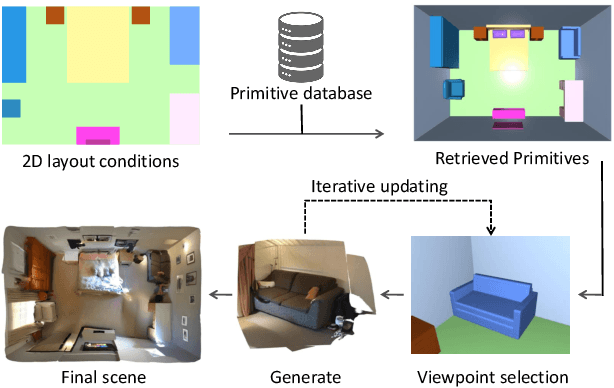
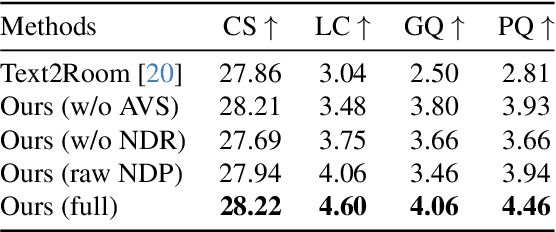
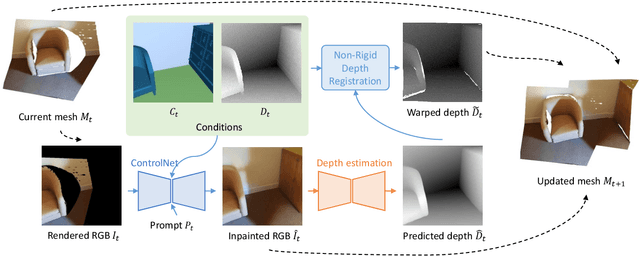

We propose Prim2Room, a novel framework for controllable room mesh generation leveraging 2D layout conditions and 3D primitive retrieval to facilitate precise 3D layout specification. Diverging from existing methods that lack control and precision, our approach allows for detailed customization of room-scale environments. To overcome the limitations of previous methods, we introduce an adaptive viewpoint selection algorithm that allows the system to generate the furniture texture and geometry from more favorable views than predefined camera trajectories. Additionally, we employ non-rigid depth registration to ensure alignment between generated objects and their corresponding primitive while allowing for shape variations to maintain diversity. Our method not only enhances the accuracy and aesthetic appeal of generated 3D scenes but also provides a user-friendly platform for detailed room design.
Sync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
May 27, 2024



In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.
REACTO: Reconstructing Articulated Objects from a Single Video
Apr 17, 2024



In this paper, we address the challenge of reconstructing general articulated 3D objects from a single video. Existing works employing dynamic neural radiance fields have advanced the modeling of articulated objects like humans and animals from videos, but face challenges with piece-wise rigid general articulated objects due to limitations in their deformation models. To tackle this, we propose Quasi-Rigid Blend Skinning, a novel deformation model that enhances the rigidity of each part while maintaining flexible deformation of the joints. Our primary insight combines three distinct approaches: 1) an enhanced bone rigging system for improved component modeling, 2) the use of quasi-sparse skinning weights to boost part rigidity and reconstruction fidelity, and 3) the application of geodesic point assignment for precise motion and seamless deformation. Our method outperforms previous works in producing higher-fidelity 3D reconstructions of general articulated objects, as demonstrated on both real and synthetic datasets. Project page: https://chaoyuesong.github.io/REACTO.
Learning-Based Biharmonic Augmentation for Point Cloud Classification
Nov 10, 2023



Point cloud datasets often suffer from inadequate sample sizes in comparison to image datasets, making data augmentation challenging. While traditional methods, like rigid transformations and scaling, have limited potential in increasing dataset diversity due to their constraints on altering individual sample shapes, we introduce the Biharmonic Augmentation (BA) method. BA is a novel and efficient data augmentation technique that diversifies point cloud data by imposing smooth non-rigid deformations on existing 3D structures. This approach calculates biharmonic coordinates for the deformation function and learns diverse deformation prototypes. Utilizing a CoefNet, our method predicts coefficients to amalgamate these prototypes, ensuring comprehensive deformation. Moreover, we present AdvTune, an advanced online augmentation system that integrates adversarial training. This system synergistically refines the CoefNet and the classification network, facilitating the automated creation of adaptive shape deformations contingent on the learner status. Comprehensive experimental analysis validates the superiority of Biharmonic Augmentation, showcasing notable performance improvements over prevailing point cloud augmentation techniques across varied network designs.
MoDA: Modeling Deformable 3D Objects from Casual Videos
Apr 17, 2023In this paper, we focus on the challenges of modeling deformable 3D objects from casual videos. With the popularity of neural radiance fields (NeRF), many works extend it to dynamic scenes with a canonical NeRF and a deformation model that achieves 3D point transformation between the observation space and the canonical space. Recent works rely on linear blend skinning (LBS) to achieve the canonical-observation transformation. However, the linearly weighted combination of rigid transformation matrices is not guaranteed to be rigid. As a matter of fact, unexpected scale and shear factors often appear. In practice, using LBS as the deformation model can always lead to skin-collapsing artifacts for bending or twisting motions. To solve this problem, we propose neural dual quaternion blend skinning (NeuDBS) to achieve 3D point deformation, which can perform rigid transformation without skin-collapsing artifacts. Besides, we introduce a texture filtering approach for texture rendering that effectively minimizes the impact of noisy colors outside target deformable objects. Extensive experiments on real and synthetic datasets show that our approach can reconstruct 3D models for humans and animals with better qualitative and quantitative performance than state-of-the-art methods.
TAPS3D: Text-Guided 3D Textured Shape Generation from Pseudo Supervision
Mar 23, 2023
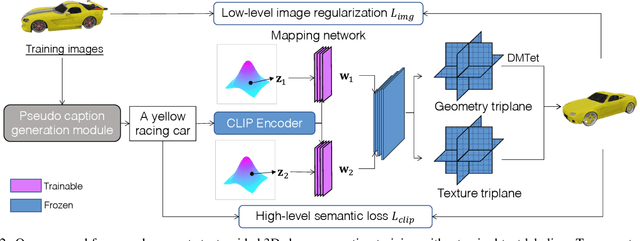
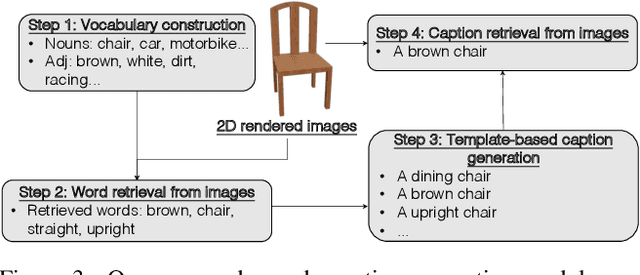
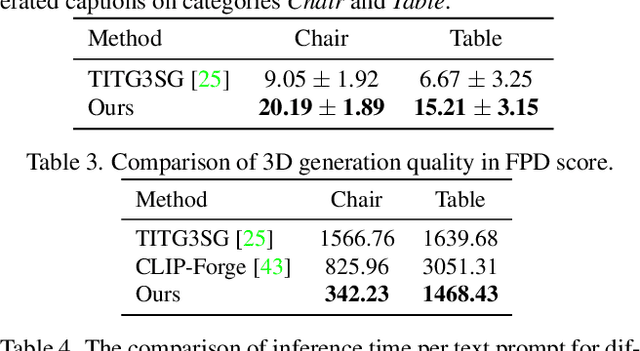
In this paper, we investigate an open research task of generating controllable 3D textured shapes from the given textual descriptions. Previous works either require ground truth caption labeling or extensive optimization time. To resolve these issues, we present a novel framework, TAPS3D, to train a text-guided 3D shape generator with pseudo captions. Specifically, based on rendered 2D images, we retrieve relevant words from the CLIP vocabulary and construct pseudo captions using templates. Our constructed captions provide high-level semantic supervision for generated 3D shapes. Further, in order to produce fine-grained textures and increase geometry diversity, we propose to adopt low-level image regularization to enable fake-rendered images to align with the real ones. During the inference phase, our proposed model can generate 3D textured shapes from the given text without any additional optimization. We conduct extensive experiments to analyze each of our proposed components and show the efficacy of our framework in generating high-fidelity 3D textured and text-relevant shapes.