 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActWorld: From Explorable to Interactive World Model via Action-Aware Memory
Jun 16, 2026Interactive world models aim to simulate environment dynamics under real-time user actions. However, their action vocabulary is largely confined to navigation: most actions correspond to motion (e.g., walk, turn, look around), while interaction with objects in the scene (e.g., pick up plates, open doors, or trigger physical responses) is either absent, restricted to game domains, or relegated to prompt-to-full-video scenarios. The resulting worlds are visually explorable but not truly actionable. In this work, we present ActWorld, an interactive world model that extends prior navigation-centric generators to support mid-rollout object interaction within a chunk-autoregressive framework. We argue that the navigation-interaction gap stems from two bottlenecks. First, a data bottleneck: the lack of human-object interaction data with accurate, dense labels. Second, a memory bottleneck: recency-biased history compression in existing world models discards the event-transition frames that causally determine subsequent object states, leading to an action-forgetting pathology. On the data side, we construct a 100K interaction video dataset, each annotated with per-chunk captions via chain-of-thought reasoning. On the model side, we introduce a hierarchical action-aware memory design that routes history compression by interaction importance, complemented by a persistent memory bank that maintains event-update and object-identity tokens across long rollouts. Experiments show that ActWorld supports both flexible navigation and rich object interaction within a single model, substantially improving interaction fidelity over navigation-only baselines without sacrificing viewpoint control. Project page is available at https://interactwm.github.io/ActWorld.
MVAnimate: Enhancing Character Animation with Multi-View Optimization
Feb 09, 2026The demand for realistic and versatile character animation has surged, driven by its wide-ranging applications in various domains. However, the animation generation algorithms modeling human pose with 2D or 3D structures all face various problems, including low-quality output content and training data deficiency, preventing the related algorithms from generating high-quality animation videos. Therefore, we introduce MVAnimate, a novel framework that synthesizes both 2D and 3D information of dynamic figures based on multi-view prior information, to enhance the generated video quality. Our approach leverages multi-view prior information to produce temporally consistent and spatially coherent animation outputs, demonstrating improvements over existing animation methods. Our MVAnimate also optimizes the multi-view videos of the target character, enhancing the video quality from different views. Experimental results on diverse datasets highlight the robustness of our method in handling various motion patterns and appearances.
VINO: A Unified Visual Generator with Interleaved OmniModal Context
Jan 05, 2026We present VINO, a unified visual generator that performs image and video generation and editing within a single framework. Instead of relying on task-specific models or independent modules for each modality, VINO uses a shared diffusion backbone that conditions on text, images and videos, enabling a broad range of visual creation and editing tasks under one model. Specifically, VINO couples a vision-language model (VLM) with a Multimodal Diffusion Transformer (MMDiT), where multimodal inputs are encoded as interleaved conditioning tokens, and then used to guide the diffusion process. This design supports multi-reference grounding, long-form instruction following, and coherent identity preservation across static and dynamic content, while avoiding modality-specific architectural components. To train such a unified system, we introduce a multi-stage training pipeline that progressively expands a video generation base model into a unified, multi-task generator capable of both image and video input and output. Across diverse generation and editing benchmarks, VINO demonstrates strong visual quality, faithful instruction following, improved reference and attribute preservation, and more controllable multi-identity edits. Our results highlight a practical path toward scalable unified visual generation, and the promise of interleaved, in-context computation as a foundation for general-purpose visual creation.
Sync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
May 27, 2024



In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.
Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior
Mar 14, 2024



Recent works on text-to-3d generation show that using only 2D diffusion supervision for 3D generation tends to produce results with inconsistent appearances (e.g., faces on the back view) and inaccurate shapes (e.g., animals with extra legs). Existing methods mainly address this issue by retraining diffusion models with images rendered from 3D data to ensure multi-view consistency while struggling to balance 2D generation quality with 3D consistency. In this paper, we present a new framework Sculpt3D that equips the current pipeline with explicit injection of 3D priors from retrieved reference objects without re-training the 2D diffusion model. Specifically, we demonstrate that high-quality and diverse 3D geometry can be guaranteed by keypoints supervision through a sparse ray sampling approach. Moreover, to ensure accurate appearances of different views, we further modulate the output of the 2D diffusion model to the correct patterns of the template views without altering the generated object's style. These two decoupled designs effectively harness 3D information from reference objects to generate 3D objects while preserving the generation quality of the 2D diffusion model. Extensive experiments show our method can largely improve the multi-view consistency while retaining fidelity and diversity. Our project page is available at: https://stellarcheng.github.io/Sculpt3D/.
OR-NeRF: Object Removing from 3D Scenes Guided by Multiview Segmentation with Neural Radiance Fields
May 24, 2023



The emergence of Neural Radiance Fields (NeRF) for novel view synthesis has led to increased interest in 3D scene editing. One important task in editing is removing objects from a scene while ensuring visual reasonability and multiview consistency. However, current methods face challenges such as time-consuming object labelling, limited capability to remove specific targets, and compromised rendering quality after removal. This paper proposes a novel object-removing pipeline, named OR-NeRF, that can remove objects from 3D scenes with either point or text prompts on a single view, achieving better performance in less time than previous works. Our method uses a points projection strategy to rapidly spread user annotations to all views, significantly reducing the processing burden. This algorithm allows us to leverage the recent 2D segmentation model Segment-Anything (SAM) to predict masks with improved precision and efficiency. Additionally, we obtain colour and depth priors through 2D inpainting methods. Finally, our algorithm employs depth supervision and perceptual loss for scene reconstruction to maintain consistency in geometry and appearance after object removal. Experimental results demonstrate that our method achieves better editing quality with less time than previous works, considering both quality and quantity.
HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction
Apr 08, 2022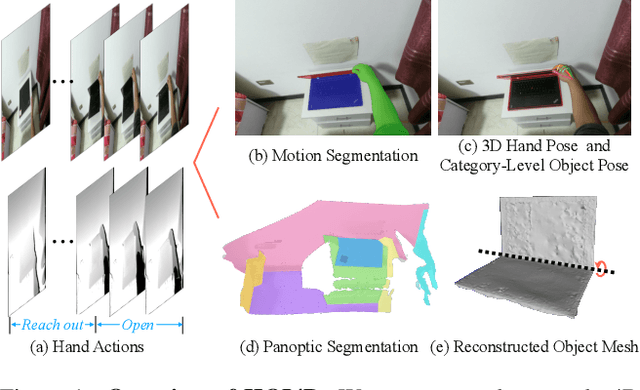

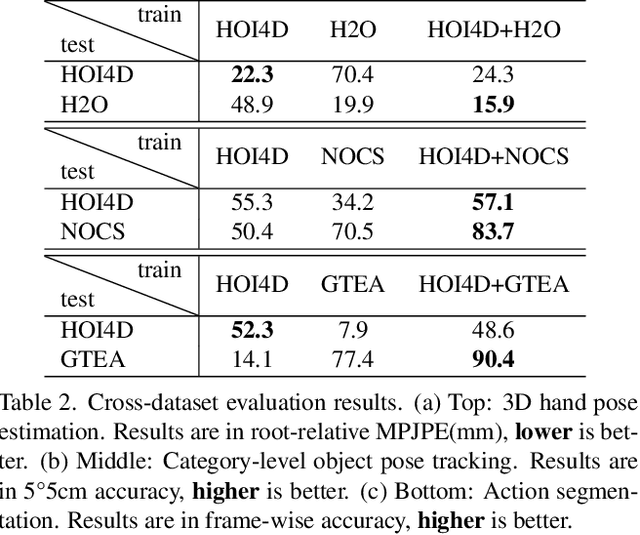
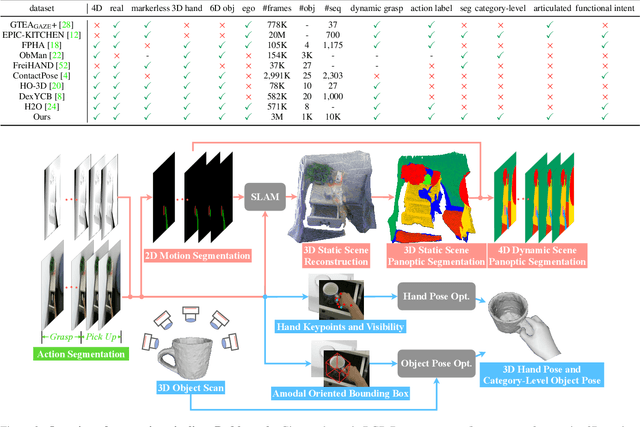
We present HOI4D, a large-scale 4D egocentric dataset with rich annotations, to catalyze the research of category-level human-object interaction. HOI4D consists of 2.4M RGB-D egocentric video frames over 4000 sequences collected by 4 participants interacting with 800 different object instances from 16 categories over 610 different indoor rooms. Frame-wise annotations for panoptic segmentation, motion segmentation, 3D hand pose, category-level object pose and hand action have also been provided, together with reconstructed object meshes and scene point clouds. With HOI4D, we establish three benchmarking tasks to promote category-level HOI from 4D visual signals including semantic segmentation of 4D dynamic point cloud sequences, category-level object pose tracking, and egocentric action segmentation with diverse interaction targets. In-depth analysis shows HOI4D poses great challenges to existing methods and produces great research opportunities.