 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMPL Normal Map Is All You Need for Single-view Textured Human Reconstruction
Jun 15, 2025Single-view textured human reconstruction aims to reconstruct a clothed 3D digital human by inputting a monocular 2D image. Existing approaches include feed-forward methods, limited by scarce 3D human data, and diffusion-based methods, prone to erroneous 2D hallucinations. To address these issues, we propose a novel SMPL normal map Equipped 3D Human Reconstruction (SEHR) framework, integrating a pretrained large 3D reconstruction model with human geometry prior. SEHR performs single-view human reconstruction without using a preset diffusion model in one forward propagation. Concretely, SEHR consists of two key components: SMPL Normal Map Guidance (SNMG) and SMPL Normal Map Constraint (SNMC). SNMG incorporates SMPL normal maps into an auxiliary network to provide improved body shape guidance. SNMC enhances invisible body parts by constraining the model to predict an extra SMPL normal Gaussians. Extensive experiments on two benchmark datasets demonstrate that SEHR outperforms existing state-of-the-art methods.
ADHMR: Aligning Diffusion-based Human Mesh Recovery via Direct Preference Optimization
May 15, 2025Human mesh recovery (HMR) from a single image is inherently ill-posed due to depth ambiguity and occlusions. Probabilistic methods have tried to solve this by generating numerous plausible 3D human mesh predictions, but they often exhibit misalignment with 2D image observations and weak robustness to in-the-wild images. To address these issues, we propose ADHMR, a framework that Aligns a Diffusion-based HMR model in a preference optimization manner. First, we train a human mesh prediction assessment model, HMR-Scorer, capable of evaluating predictions even for in-the-wild images without 3D annotations. We then use HMR-Scorer to create a preference dataset, where each input image has a pair of winner and loser mesh predictions. This dataset is used to finetune the base model using direct preference optimization. Moreover, HMR-Scorer also helps improve existing HMR models by data cleaning, even with fewer training samples. Extensive experiments show that ADHMR outperforms current state-of-the-art methods. Code is available at: https://github.com/shenwenhao01/ADHMR.
Unify3D: An Augmented Holistic End-to-end Monocular 3D Human Reconstruction via Anatomy Shaping and Twins Negotiating
Apr 25, 2025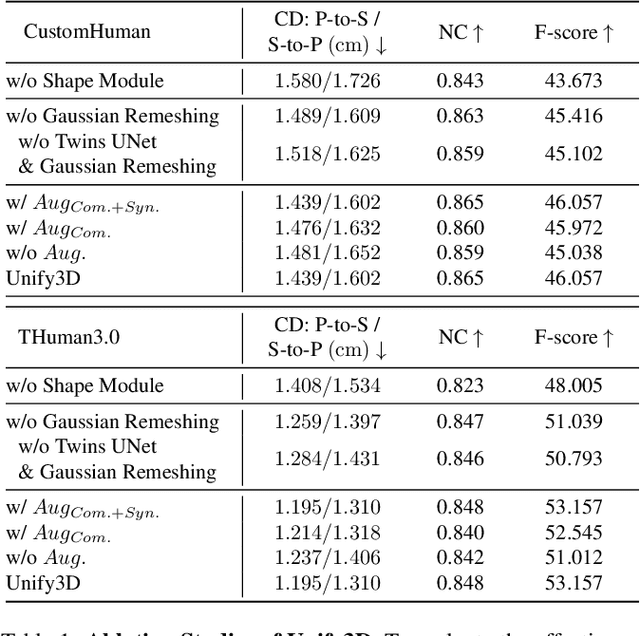
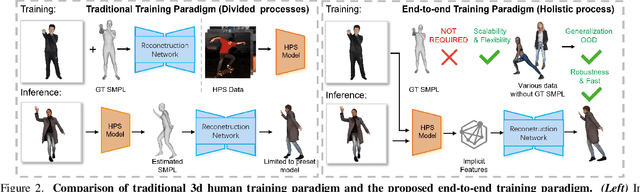
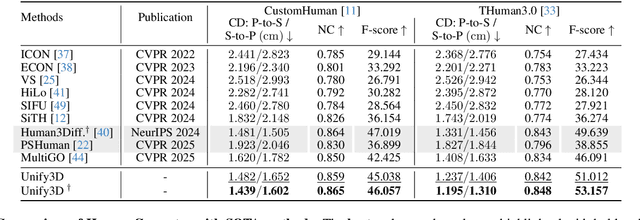
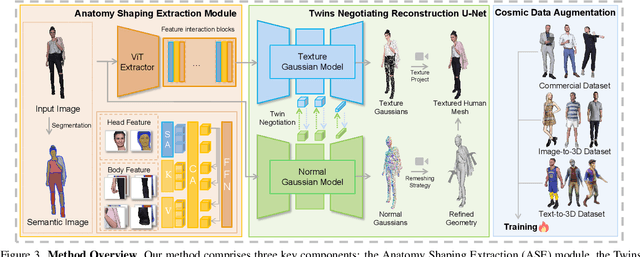
Monocular 3D clothed human reconstruction aims to create a complete 3D avatar from a single image. To tackle the human geometry lacking in one RGB image, current methods typically resort to a preceding model for an explicit geometric representation. For the reconstruction itself, focus is on modeling both it and the input image. This routine is constrained by the preceding model, and overlooks the integrity of the reconstruction task. To address this, this paper introduces a novel paradigm that treats human reconstruction as a holistic process, utilizing an end-to-end network for direct prediction from 2D image to 3D avatar, eliminating any explicit intermediate geometry display. Based on this, we further propose a novel reconstruction framework consisting of two core components: the Anatomy Shaping Extraction module, which captures implicit shape features taking into account the specialty of human anatomy, and the Twins Negotiating Reconstruction U-Net, which enhances reconstruction through feature interaction between two U-Nets of different modalities. Moreover, we propose a Comic Data Augmentation strategy and construct 15k+ 3D human scans to bolster model performance in more complex case input. Extensive experiments on two test sets and many in-the-wild cases show the superiority of our method over SOTA methods. Our demos can be found in : https://e2e3dgsrecon.github.io/e2e3dgsrecon/.
Image Quality Assessment: Investigating Causal Perceptual Effects with Abductive Counterfactual Inference
Dec 22, 2024Existing full-reference image quality assessment (FR-IQA) methods often fail to capture the complex causal mechanisms that underlie human perceptual responses to image distortions, limiting their ability to generalize across diverse scenarios. In this paper, we propose an FR-IQA method based on abductive counterfactual inference to investigate the causal relationships between deep network features and perceptual distortions. First, we explore the causal effects of deep features on perception and integrate causal reasoning with feature comparison, constructing a model that effectively handles complex distortion types across different IQA scenarios. Second, the analysis of the perceptual causal correlations of our proposed method is independent of the backbone architecture and thus can be applied to a variety of deep networks. Through abductive counterfactual experiments, we validate the proposed causal relationships, confirming the model's superior perceptual relevance and interpretability of quality scores. The experimental results demonstrate the robustness and effectiveness of the method, providing competitive quality predictions across multiple benchmarks. The source code is available at https://anonymous.4open.science/r/DeepCausalQuality-25BC.
Sync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
May 27, 2024



In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.