 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOR-NeRF: Object Removing from 3D Scenes Guided by Multiview Segmentation with Neural Radiance Fields
May 24, 2023



The emergence of Neural Radiance Fields (NeRF) for novel view synthesis has led to increased interest in 3D scene editing. One important task in editing is removing objects from a scene while ensuring visual reasonability and multiview consistency. However, current methods face challenges such as time-consuming object labelling, limited capability to remove specific targets, and compromised rendering quality after removal. This paper proposes a novel object-removing pipeline, named OR-NeRF, that can remove objects from 3D scenes with either point or text prompts on a single view, achieving better performance in less time than previous works. Our method uses a points projection strategy to rapidly spread user annotations to all views, significantly reducing the processing burden. This algorithm allows us to leverage the recent 2D segmentation model Segment-Anything (SAM) to predict masks with improved precision and efficiency. Additionally, we obtain colour and depth priors through 2D inpainting methods. Finally, our algorithm employs depth supervision and perceptual loss for scene reconstruction to maintain consistency in geometry and appearance after object removal. Experimental results demonstrate that our method achieves better editing quality with less time than previous works, considering both quality and quantity.
Training Generative Adversarial Networks in One Stage
Mar 04, 2021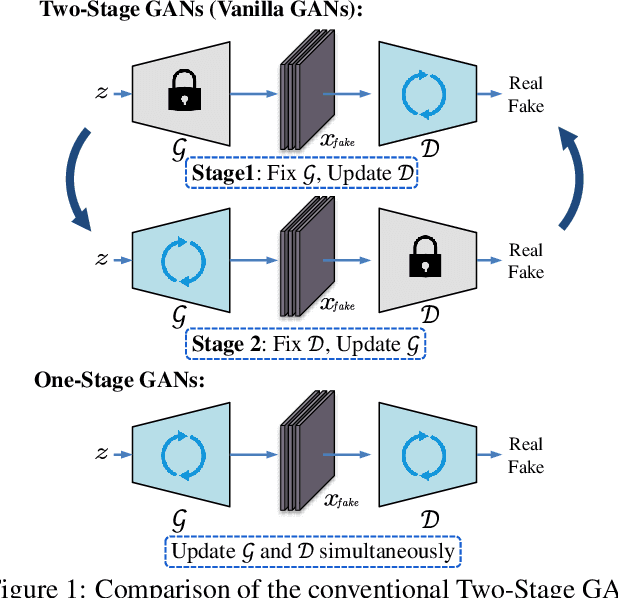



Generative Adversarial Networks (GANs) have demonstrated unprecedented success in various image generation tasks. The encouraging results, however, come at the price of a cumbersome training process, during which the generator and discriminator are alternately updated in two stages. In this paper, we investigate a general training scheme that enables training GANs efficiently in only one stage. Based on the adversarial losses of the generator and discriminator, we categorize GANs into two classes, Symmetric GANs and Asymmetric GANs, and introduce a novel gradient decomposition method to unify the two, allowing us to train both classes in one stage and hence alleviate the training effort. Computational analysis and experimental results on several datasets and various network architectures demonstrate that, the proposed one-stage training scheme yields a solid 1.5$\times$ acceleration over conventional training schemes, regardless of the network architectures of the generator and discriminator. Furthermore, we show that the proposed method is readily applicable to other adversarial-training scenarios, such as data-free knowledge distillation. Our source code will be published soon.
Progressive Network Grafting for Few-Shot Knowledge Distillation
Dec 11, 2020

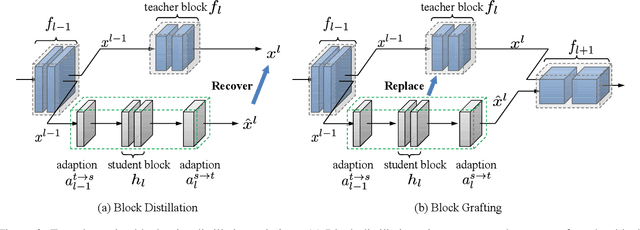

Knowledge distillation has demonstrated encouraging performances in deep model compression. Most existing approaches, however, require massive labeled data to accomplish the knowledge transfer, making the model compression a cumbersome and costly process. In this paper, we investigate the practical few-shot knowledge distillation scenario, where we assume only a few samples without human annotations are available for each category. To this end, we introduce a principled dual-stage distillation scheme tailored for few-shot data. In the first step, we graft the student blocks one by one onto the teacher, and learn the parameters of the grafted block intertwined with those of the other teacher blocks. In the second step, the trained student blocks are progressively connected and then together grafted onto the teacher network, allowing the learned student blocks to adapt themselves to each other and eventually replace the teacher network. Experiments demonstrate that our approach, with only a few unlabeled samples, achieves gratifying results on CIFAR10, CIFAR100, and ILSVRC-2012. On CIFAR10 and CIFAR100, our performances are even on par with those of knowledge distillation schemes that utilize the full datasets. The source code is available at https://github.com/zju-vipa/NetGraft.