 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Domain Generalization on Gaze Estimation via Branch-out Auxiliary Regularization
May 02, 2024Despite remarkable advancements, mainstream gaze estimation techniques, particularly appearance-based methods, often suffer from performance degradation in uncontrolled environments due to variations in illumination and individual facial attributes. Existing domain adaptation strategies, limited by their need for target domain samples, may fall short in real-world applications. This letter introduces Branch-out Auxiliary Regularization (BAR), an innovative method designed to boost gaze estimation's generalization capabilities without requiring direct access to target domain data. Specifically, BAR integrates two auxiliary consistency regularization branches: one that uses augmented samples to counteract environmental variations, and another that aligns gaze directions with positive source domain samples to encourage the learning of consistent gaze features. These auxiliary pathways strengthen the core network and are integrated in a smooth, plug-and-play manner, facilitating easy adaptation to various other models. Comprehensive experimental evaluations on four cross-dataset tasks demonstrate the superiority of our approach.
MAGIC: Multimodal relAtional Graph adversarIal inferenCe for Diverse and Unpaired Text-based Image Captioning
Dec 13, 2021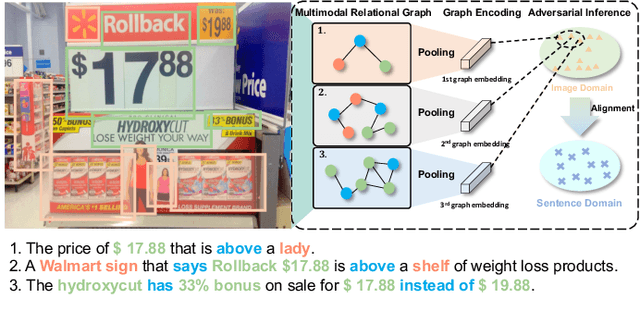
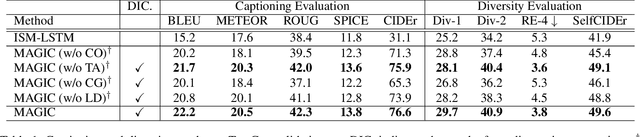
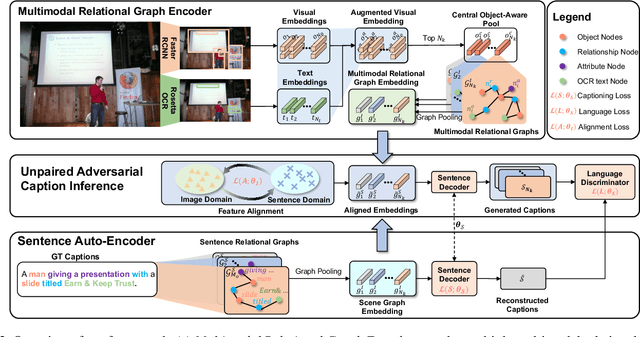
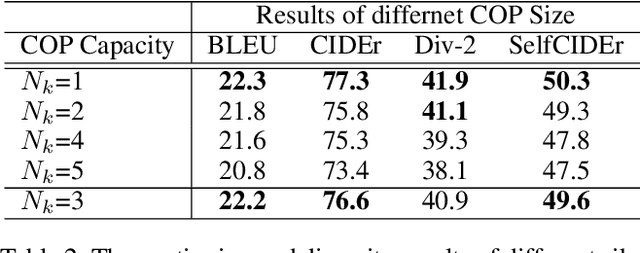
Text-based image captioning (TextCap) requires simultaneous comprehension of visual content and reading the text of images to generate a natural language description. Although a task can teach machines to understand the complex human environment further given that text is omnipresent in our daily surroundings, it poses additional challenges in normal captioning. A text-based image intuitively contains abundant and complex multimodal relational content, that is, image details can be described diversely from multiview rather than a single caption. Certainly, we can introduce additional paired training data to show the diversity of images' descriptions, this process is labor-intensive and time-consuming for TextCap pair annotations with extra texts. Based on the insight mentioned above, we investigate how to generate diverse captions that focus on different image parts using an unpaired training paradigm. We propose the Multimodal relAtional Graph adversarIal inferenCe (MAGIC) framework for diverse and unpaired TextCap. This framework can adaptively construct multiple multimodal relational graphs of images and model complex relationships among graphs to represent descriptive diversity. Moreover, a cascaded generative adversarial network is developed from modeled graphs to infer the unpaired caption generation in image-sentence feature alignment and linguistic coherence levels. We validate the effectiveness of MAGIC in generating diverse captions from different relational information items of an image. Experimental results show that MAGIC can generate very promising outcomes without using any image-caption training pairs.
Progressive Network Grafting for Few-Shot Knowledge Distillation
Dec 11, 2020

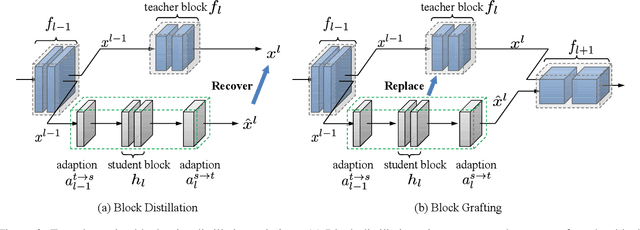

Knowledge distillation has demonstrated encouraging performances in deep model compression. Most existing approaches, however, require massive labeled data to accomplish the knowledge transfer, making the model compression a cumbersome and costly process. In this paper, we investigate the practical few-shot knowledge distillation scenario, where we assume only a few samples without human annotations are available for each category. To this end, we introduce a principled dual-stage distillation scheme tailored for few-shot data. In the first step, we graft the student blocks one by one onto the teacher, and learn the parameters of the grafted block intertwined with those of the other teacher blocks. In the second step, the trained student blocks are progressively connected and then together grafted onto the teacher network, allowing the learned student blocks to adapt themselves to each other and eventually replace the teacher network. Experiments demonstrate that our approach, with only a few unlabeled samples, achieves gratifying results on CIFAR10, CIFAR100, and ILSVRC-2012. On CIFAR10 and CIFAR100, our performances are even on par with those of knowledge distillation schemes that utilize the full datasets. The source code is available at https://github.com/zju-vipa/NetGraft.
Knowledge Amalgamation from Heterogeneous Networks by Common Feature Learning
Jun 24, 2019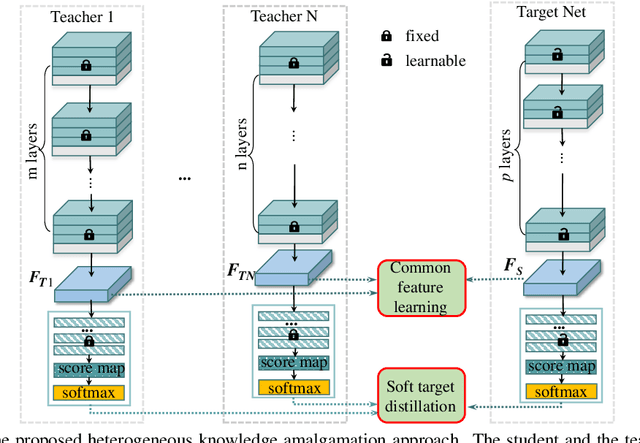

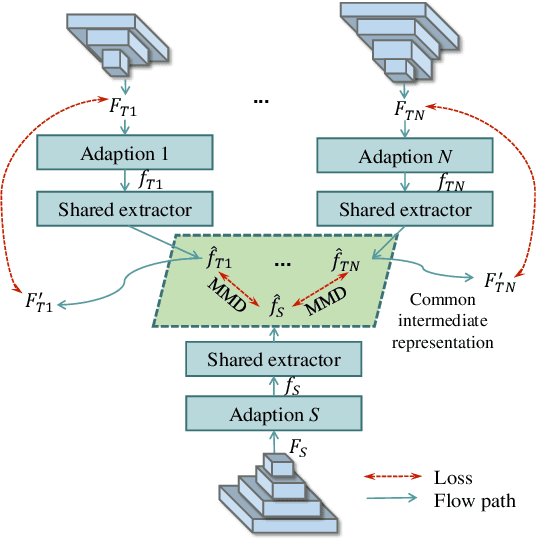
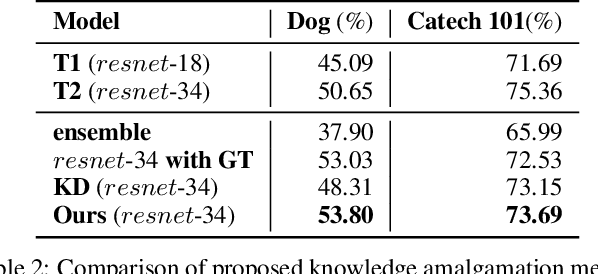
An increasing number of well-trained deep networks have been released online by researchers and developers, enabling the community to reuse them in a plug-and-play way without accessing the training annotations. However, due to the large number of network variants, such public-available trained models are often of different architectures, each of which being tailored for a specific task or dataset. In this paper, we study a deep-model reusing task, where we are given as input pre-trained networks of heterogeneous architectures specializing in distinct tasks, as teacher models. We aim to learn a multitalented and light-weight student model that is able to grasp the integrated knowledge from all such heterogeneous-structure teachers, again without accessing any human annotation. To this end, we propose a common feature learning scheme, in which the features of all teachers are transformed into a common space and the student is enforced to imitate them all so as to amalgamate the intact knowledge. We test the proposed approach on a list of benchmarks and demonstrate that the learned student is able to achieve very promising performance, superior to those of the teachers in their specialized tasks.
DeepSIC: Deep Semantic Image Compression
Jan 29, 2018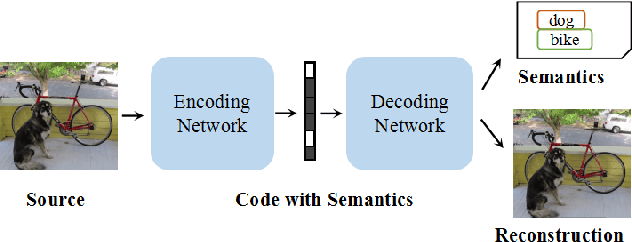
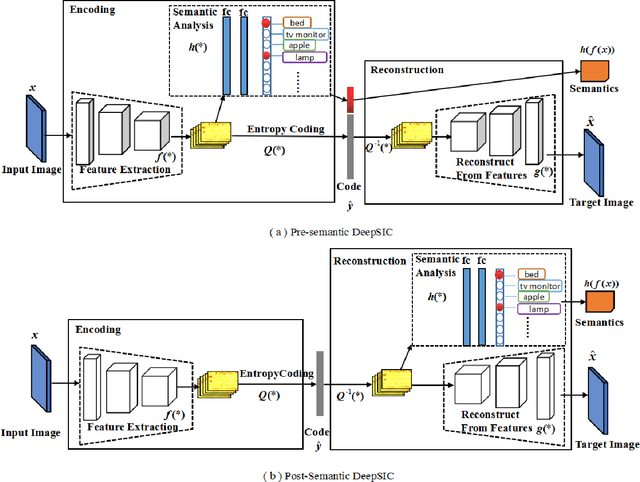
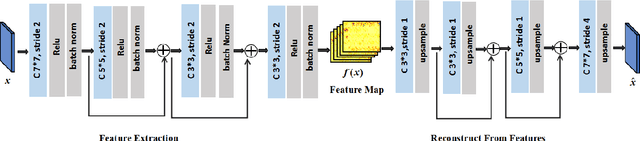
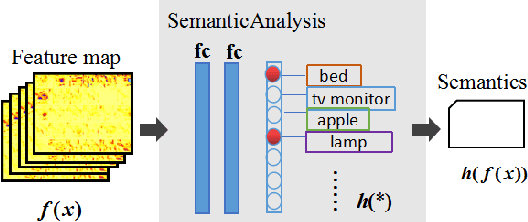
Incorporating semantic information into the codecs during image compression can significantly reduce the repetitive computation of fundamental semantic analysis (such as object recognition) in client-side applications. The same practice also enable the compressed code to carry the image semantic information during storage and transmission. In this paper, we propose a concept called Deep Semantic Image Compression (DeepSIC) and put forward two novel architectures that aim to reconstruct the compressed image and generate corresponding semantic representations at the same time. The first architecture performs semantic analysis in the encoding process by reserving a portion of the bits from the compressed code to store the semantic representations. The second performs semantic analysis in the decoding step with the feature maps that are embedded in the compressed code. In both architectures, the feature maps are shared by the compression and the semantic analytics modules. To validate our approaches, we conduct experiments on the publicly available benchmarking datasets and achieve promising results. We also provide a thorough analysis of the advantages and disadvantages of the proposed technique.