 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBronchovascular Tree-Guided Weakly Supervised Learning Method for Pulmonary Segment Segmentation
May 20, 2025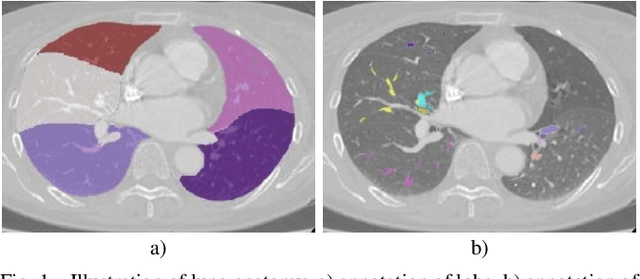
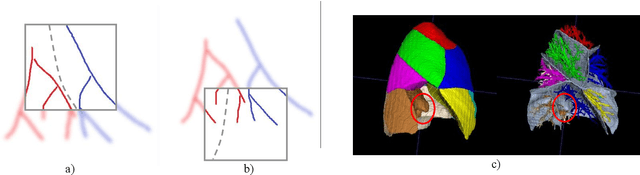
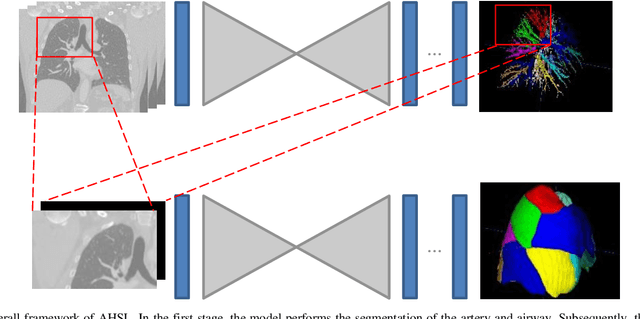
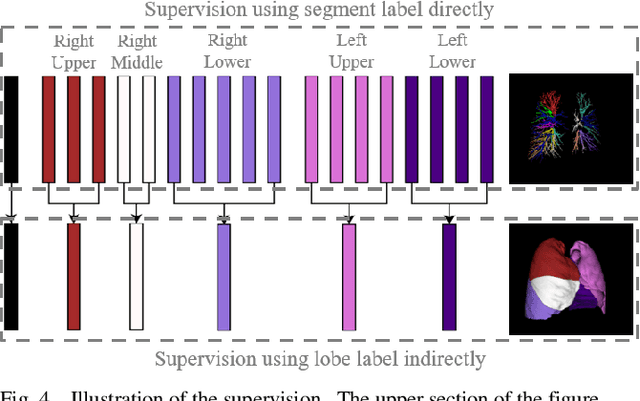
Pulmonary segment segmentation is crucial for cancer localization and surgical planning. However, the pixel-wise annotation of pulmonary segments is laborious, as the boundaries between segments are indistinguishable in medical images. To this end, we propose a weakly supervised learning (WSL) method, termed Anatomy-Hierarchy Supervised Learning (AHSL), which consults the precise clinical anatomical definition of pulmonary segments to perform pulmonary segment segmentation. Since pulmonary segments reside within the lobes and are determined by the bronchovascular tree, i.e., artery, airway and vein, the design of the loss function is founded on two principles. First, segment-level labels are utilized to directly supervise the output of the pulmonary segments, ensuring that they accurately encompass the appropriate bronchovascular tree. Second, lobe-level supervision indirectly oversees the pulmonary segment, ensuring their inclusion within the corresponding lobe. Besides, we introduce a two-stage segmentation strategy that incorporates bronchovascular priori information. Furthermore, a consistency loss is proposed to enhance the smoothness of segment boundaries, along with an evaluation metric designed to measure the smoothness of pulmonary segment boundaries. Visual inspection and evaluation metrics from experiments conducted on a private dataset demonstrate the effectiveness of our method.
Improving Domain Generalization on Gaze Estimation via Branch-out Auxiliary Regularization
May 02, 2024Despite remarkable advancements, mainstream gaze estimation techniques, particularly appearance-based methods, often suffer from performance degradation in uncontrolled environments due to variations in illumination and individual facial attributes. Existing domain adaptation strategies, limited by their need for target domain samples, may fall short in real-world applications. This letter introduces Branch-out Auxiliary Regularization (BAR), an innovative method designed to boost gaze estimation's generalization capabilities without requiring direct access to target domain data. Specifically, BAR integrates two auxiliary consistency regularization branches: one that uses augmented samples to counteract environmental variations, and another that aligns gaze directions with positive source domain samples to encourage the learning of consistent gaze features. These auxiliary pathways strengthen the core network and are integrated in a smooth, plug-and-play manner, facilitating easy adaptation to various other models. Comprehensive experimental evaluations on four cross-dataset tasks demonstrate the superiority of our approach.
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
Jan 18, 2024



Large language models (LLMs) have exhibited great potential in autonomously completing tasks across real-world applications. Despite this, these LLM agents introduce unexpected safety risks when operating in interactive environments. Instead of centering on LLM-generated content safety in most prior studies, this work addresses the imperative need for benchmarking the behavioral safety of LLM agents within diverse environments. We introduce R-Judge, a benchmark crafted to evaluate the proficiency of LLMs in judging safety risks given agent interaction records. R-Judge comprises 162 agent interaction records, encompassing 27 key risk scenarios among 7 application categories and 10 risk types. It incorporates human consensus on safety with annotated safety risk labels and high-quality risk descriptions. Utilizing R-Judge, we conduct a comprehensive evaluation of 8 prominent LLMs commonly employed as the backbone for agents. The best-performing model, GPT-4, achieves 72.29% in contrast to the human score of 89.38%, showing considerable room for enhancing the risk awareness of LLMs. Notably, leveraging risk descriptions as environment feedback significantly improves model performance, revealing the importance of salient safety risk feedback. Furthermore, we design an effective chain of safety analysis technique to help the judgment of safety risks and conduct an in-depth case study to facilitate future research. R-Judge is publicly available at https://github.com/Lordog/R-Judge.
DHBE: Data-free Holistic Backdoor Erasing in Deep Neural Networks via Restricted Adversarial Distillation
Jun 13, 2023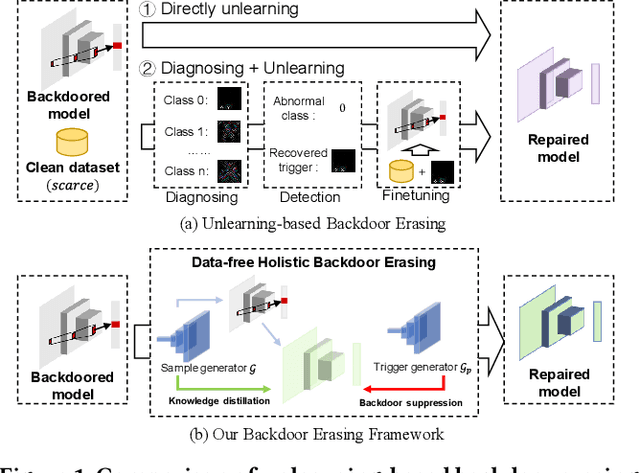
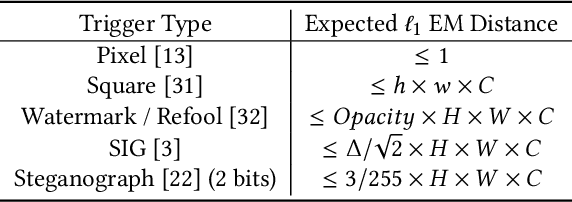
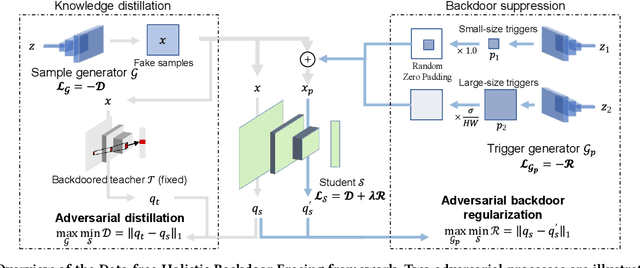

Backdoor attacks have emerged as an urgent threat to Deep Neural Networks (DNNs), where victim DNNs are furtively implanted with malicious neurons that could be triggered by the adversary. To defend against backdoor attacks, many works establish a staged pipeline to remove backdoors from victim DNNs: inspecting, locating, and erasing. However, in a scenario where a few clean data can be accessible, such pipeline is fragile and cannot erase backdoors completely without sacrificing model accuracy. To address this issue, in this paper, we propose a novel data-free holistic backdoor erasing (DHBE) framework. Instead of the staged pipeline, the DHBE treats the backdoor erasing task as a unified adversarial procedure, which seeks equilibrium between two different competing processes: distillation and backdoor regularization. In distillation, the backdoored DNN is distilled into a proxy model, transferring its knowledge about clean data, yet backdoors are simultaneously transferred. In backdoor regularization, the proxy model is holistically regularized to prevent from infecting any possible backdoor transferred from distillation. These two processes jointly proceed with data-free adversarial optimization until a clean, high-accuracy proxy model is obtained. With the novel adversarial design, our framework demonstrates its superiority in three aspects: 1) minimal detriment to model accuracy, 2) high tolerance for hyperparameters, and 3) no demand for clean data. Extensive experiments on various backdoor attacks and datasets are performed to verify the effectiveness of the proposed framework. Code is available at \url{https://github.com/yanzhicong/DHBE}