 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALEX:A Light Editing-knowledge Extractor
Nov 18, 2025


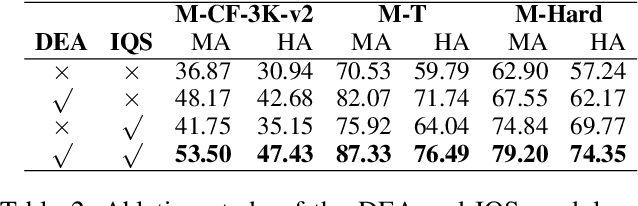
The static nature of knowledge within Large Language Models (LLMs) makes it difficult for them to adapt to evolving information, rendering knowledge editing a critical task. However, existing methods struggle with challenges of scalability and retrieval efficiency, particularly when handling complex, multi-hop questions that require multi-step reasoning. To address these challenges, this paper introduces ALEX (A Light Editing-knowledge Extractor), a lightweight knowledge editing framework. The core innovation of ALEX is its hierarchical memory architecture, which organizes knowledge updates (edits) into semantic clusters. This design fundamentally reduces retrieval complexity from a linear O(N) to a highly scalable O(K+N/C). Furthermore, the framework integrates an Inferential Query Synthesis (IQS) module to bridge the semantic gap between queries and facts , and a Dynamic Evidence Adjudication (DEA) engine that executes an efficient two-stage retrieval process. Experiments on the MQUAKE benchmark demonstrate that ALEX significantly improves both the accuracy of multi-hop answers (MultiHop-ACC) and the reliability of reasoning paths (HopWise-ACC). It also reduces the required search space by over 80% , presenting a promising path toward building scalable, efficient, and accurate knowledge editing systems.
Jointly Recognizing Speech and Singing Voices Based on Multi-Task Audio Source Separation
Apr 17, 2024In short video and live broadcasts, speech, singing voice, and background music often overlap and obscure each other. This complexity creates difficulties in structuring and recognizing the audio content, which may impair subsequent ASR and music understanding applications. This paper proposes a multi-task audio source separation (MTASS) based ASR model called JRSV, which Jointly Recognizes Speech and singing Voices. Specifically, the MTASS module separates the mixed audio into distinct speech and singing voice tracks while removing background music. The CTC/attention hybrid recognition module recognizes both tracks. Online distillation is proposed to improve the robustness of recognition further. To evaluate the proposed methods, a benchmark dataset is constructed and released. Experimental results demonstrate that JRSV can significantly improve recognition accuracy on each track of the mixed audio.
Apollonion: Profile-centric Dialog Agent
Apr 10, 2024



The emergence of Large Language Models (LLMs) has innovated the development of dialog agents. Specially, a well-trained LLM, as a central process unit, is capable of providing fluent and reasonable response for user's request. Besides, auxiliary tools such as external knowledge retrieval, personalized character for vivid response, short/long-term memory for ultra long context management are developed, completing the usage experience for LLM-based dialog agents. However, the above-mentioned techniques does not solve the issue of \textbf{personalization from user perspective}: agents response in a same fashion to different users, without consideration of their features, such as habits, interests and past experience. In another words, current implementation of dialog agents fail in ``knowing the user''. The capacity of well-description and representation of user is under development. In this work, we proposed a framework for dialog agent to incorporate user profiling (initialization, update): user's query and response is analyzed and organized into a structural user profile, which is latter served to provide personal and more precise response. Besides, we proposed a series of evaluation protocols for personalization: to what extend the response is personal to the different users. The framework is named as \method{}, inspired by inscription of ``Know Yourself'' in the temple of Apollo (also known as \method{}) in Ancient Greek. Few works have been conducted on incorporating personalization into LLM, \method{} is a pioneer work on guiding LLM's response to meet individuation via the application of dialog agents, with a set of evaluation methods for measurement in personalization.
Experts' cognition-driven ensemble deep learning for external validation of predicting pathological complete response to neoadjuvant chemotherapy from histological images in breast cancer
Jun 19, 2023In breast cancer imaging, there has been a trend to directly predict pathological complete response (pCR) to neoadjuvant chemotherapy (NAC) from histological images based on deep learning (DL). However, it has been a commonly known problem that the constructed DL-based models numerically have better performances in internal validation than in external validation. The primary reason for this situation lies in that the distribution of the external data for validation is different from the distribution of the training data for the construction of the predictive model. In this paper, we aim to alleviate this situation with a more intrinsic approach. We propose an experts' cognition-driven ensemble deep learning (ECDEDL) approach for external validation of predicting pCR to NAC from histological images in breast cancer. The proposed ECDEDL, which takes the cognition of both pathology and artificial intelligence experts into consideration to improve the generalization of the predictive model to the external validation, more intrinsically approximates the working paradigm of a human being which will refer to his various working experiences to make decisions. The proposed ECDEDL approach was validated with 695 WSIs collected from the same center as the primary dataset to develop the predictive model and perform the internal validation, and 340 WSIs collected from other three centers as the external dataset to perform the external validation. In external validation, the proposed ECDEDL approach improves the AUCs of pCR prediction from 61.52(59.80-63.26) to 67.75(66.74-68.80) and the Accuracies of pCR prediction from 56.09(49.39-62.79) to 71.01(69.44-72.58). The proposed ECDEDL was quite effective for external validation, numerically more approximating the internal validation.
Few-shot Multi-domain Knowledge Rearming for Context-aware Defence against Advanced Persistent Threats
Jun 14, 2023Advanced persistent threats (APTs) have novel features such as multi-stage penetration, highly-tailored intention, and evasive tactics. APTs defense requires fusing multi-dimensional Cyber threat intelligence data to identify attack intentions and conducts efficient knowledge discovery strategies by data-driven machine learning to recognize entity relationships. However, data-driven machine learning lacks generalization ability on fresh or unknown samples, reducing the accuracy and practicality of the defense model. Besides, the private deployment of these APT defense models on heterogeneous environments and various network devices requires significant investment in context awareness (such as known attack entities, continuous network states, and current security strategies). In this paper, we propose a few-shot multi-domain knowledge rearming (FMKR) scheme for context-aware defense against APTs. By completing multiple small tasks that are generated from different network domains with meta-learning, the FMKR firstly trains a model with good discrimination and generalization ability for fresh and unknown APT attacks. In each FMKR task, both threat intelligence and local entities are fused into the support/query sets in meta-learning to identify possible attack stages. Secondly, to rearm current security strategies, an finetuning-based deployment mechanism is proposed to transfer learned knowledge into the student model, while minimizing the defense cost. Compared to multiple model replacement strategies, the FMKR provides a faster response to attack behaviors while consuming less scheduling cost. Based on the feedback from multiple real users of the Industrial Internet of Things (IIoT) over 2 months, we demonstrate that the proposed scheme can improve the defense satisfaction rate.
DHBE: Data-free Holistic Backdoor Erasing in Deep Neural Networks via Restricted Adversarial Distillation
Jun 13, 2023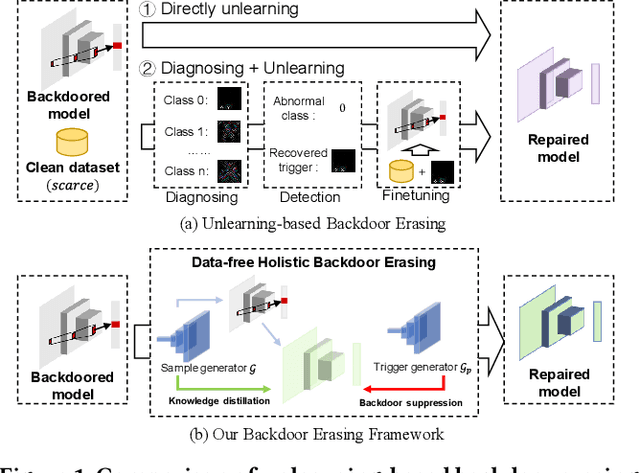
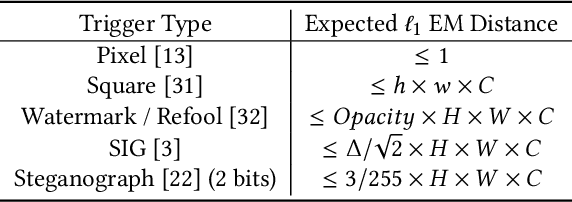
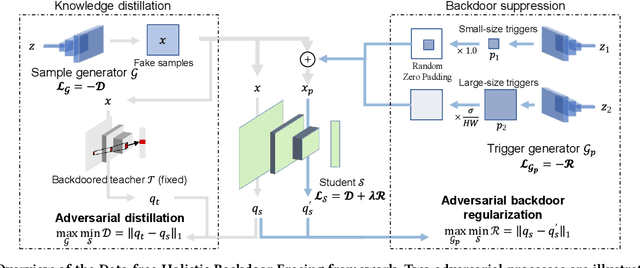

Backdoor attacks have emerged as an urgent threat to Deep Neural Networks (DNNs), where victim DNNs are furtively implanted with malicious neurons that could be triggered by the adversary. To defend against backdoor attacks, many works establish a staged pipeline to remove backdoors from victim DNNs: inspecting, locating, and erasing. However, in a scenario where a few clean data can be accessible, such pipeline is fragile and cannot erase backdoors completely without sacrificing model accuracy. To address this issue, in this paper, we propose a novel data-free holistic backdoor erasing (DHBE) framework. Instead of the staged pipeline, the DHBE treats the backdoor erasing task as a unified adversarial procedure, which seeks equilibrium between two different competing processes: distillation and backdoor regularization. In distillation, the backdoored DNN is distilled into a proxy model, transferring its knowledge about clean data, yet backdoors are simultaneously transferred. In backdoor regularization, the proxy model is holistically regularized to prevent from infecting any possible backdoor transferred from distillation. These two processes jointly proceed with data-free adversarial optimization until a clean, high-accuracy proxy model is obtained. With the novel adversarial design, our framework demonstrates its superiority in three aspects: 1) minimal detriment to model accuracy, 2) high tolerance for hyperparameters, and 3) no demand for clean data. Extensive experiments on various backdoor attacks and datasets are performed to verify the effectiveness of the proposed framework. Code is available at \url{https://github.com/yanzhicong/DHBE}
CATFL: Certificateless Authentication-based Trustworthy Federated Learning for 6G Semantic Communications
Feb 01, 2023Federated learning (FL) provides an emerging approach for collaboratively training semantic encoder/decoder models of semantic communication systems, without private user data leaving the devices. Most existing studies on trustworthy FL aim to eliminate data poisoning threats that are produced by malicious clients, but in many cases, eliminating model poisoning attacks brought by fake servers is also an important objective. In this paper, a certificateless authentication-based trustworthy federated learning (CATFL) framework is proposed, which mutually authenticates the identity of clients and server. In CATFL, each client verifies the server's signature information before accepting the delivered global model to ensure that the global model is not delivered by false servers. On the contrary, the server also verifies the server's signature information before accepting the delivered model updates to ensure that they are submitted by authorized clients. Compared to PKI-based methods, the CATFL can avoid too high certificate management overheads. Meanwhile, the anonymity of clients shields data poisoning attacks, while real-name registration may suffer from user-specific privacy leakage risks. Therefore, a pseudonym generation strategy is also presented in CATFL to achieve a trade-off between identity traceability and user anonymity, which is essential to conditionally prevent from user-specific privacy leakage. Theoretical security analysis and evaluation results validate the superiority of CATFL.
A deep learning approach to solve forward differential problems on graphs
Oct 07, 2022
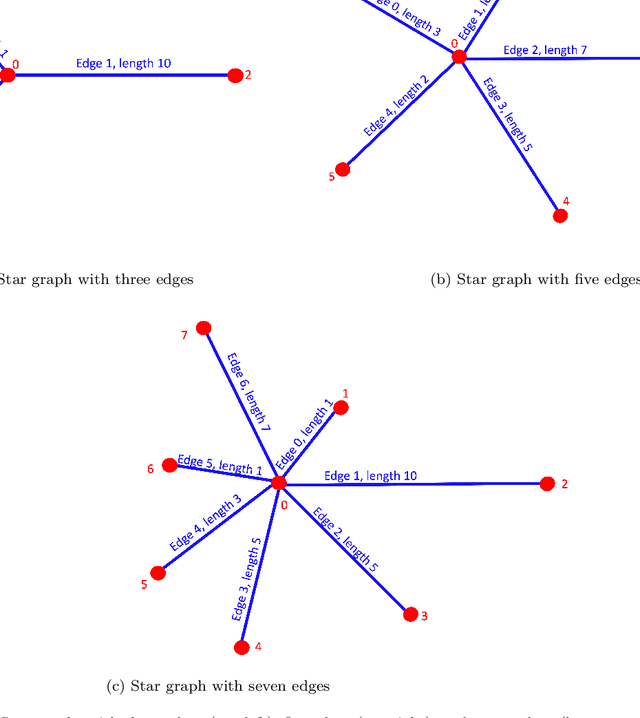
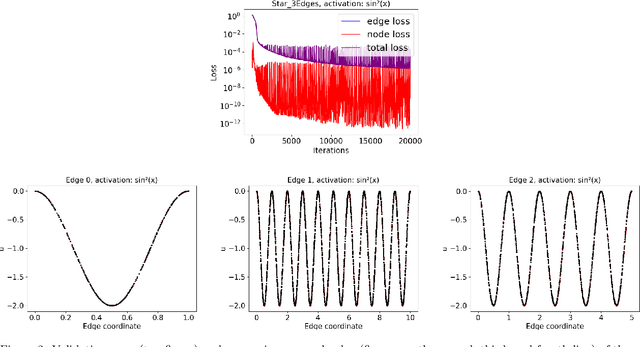
We propose a novel deep learning (DL) approach to solve one-dimensional non-linear elliptic, parabolic, and hyperbolic problems on graphs. A system of physics-informed neural network (PINN) models is used to solve the differential equations, by assigning each PINN model to a specific edge of the graph. Kirkhoff-Neumann (KN) nodal conditions are imposed in a weak form by adding a penalization term to the training loss function. Through the penalization term that imposes the KN conditions, PINN models associated with edges that share a node coordinate with each other to ensure continuity of the solution and of its directional derivatives computed along the respective edges. Using individual PINN models for each edge of the graph allows our approach to fulfill necessary requirements for parallelization by enabling different PINN models to be trained on distributed compute resources. Numerical results show that the system of PINN models accurately approximate the solutions of the differential problems across the entire graph for a broad set of graph topologies.
Constructing a Family Tree of Ten Indo-European Languages with Delexicalized Cross-linguistic Transfer Patterns
Jul 17, 2020
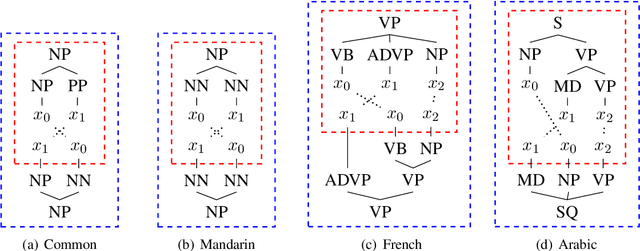


It is reasonable to hypothesize that the divergence patterns formulated by historical linguists and typologists reflect constraints on human languages, and are thus consistent with Second Language Acquisition (SLA) in a certain way. In this paper, we validate this hypothesis on ten Indo-European languages. We formalize the delexicalized transfer as interpretable tree-to-string and tree-to-tree patterns which can be automatically induced from web data by applying neural syntactic parsing and grammar induction technologies. This allows us to quantitatively probe cross-linguistic transfer and extend inquiries of SLA. We extend existing works which utilize mixed features and support the agreement between delexicalized cross-linguistic transfer and the phylogenetic structure resulting from the historical-comparative paradigm.
Semantic Role Labeling for Learner Chinese: the Importance of Syntactic Parsing and L2-L1 Parallel Data
Aug 29, 2018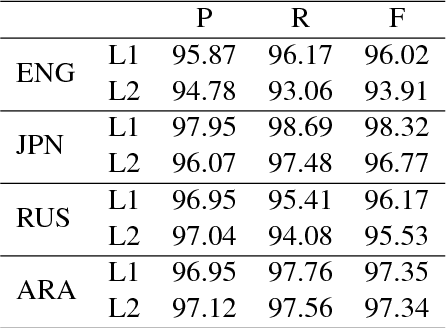
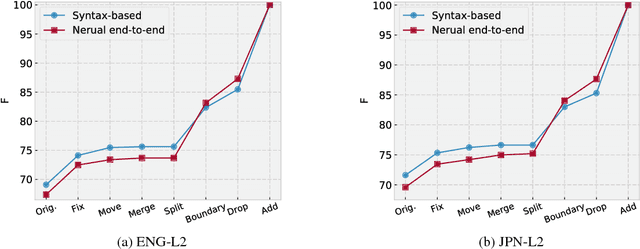
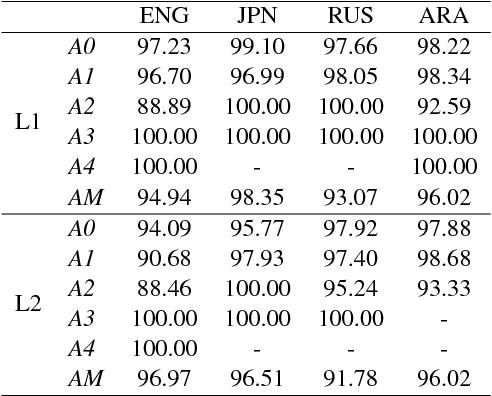

This paper studies semantic parsing for interlanguage (L2), taking semantic role labeling (SRL) as a case task and learner Chinese as a case language. We first manually annotate the semantic roles for a set of learner texts to derive a gold standard for automatic SRL. Based on the new data, we then evaluate three off-the-shelf SRL systems, i.e., the PCFGLA-parser-based, neural-parser-based and neural-syntax-agnostic systems, to gauge how successful SRL for learner Chinese can be. We find two non-obvious facts: 1) the L1-sentence-trained systems performs rather badly on the L2 data; 2) the performance drop from the L1 data to the L2 data of the two parser-based systems is much smaller, indicating the importance of syntactic parsing in SRL for interlanguages. Finally, the paper introduces a new agreement-based model to explore the semantic coherency information in the large-scale L2-L1 parallel data. We then show such information is very effective to enhance SRL for learner texts. Our model achieves an F-score of 72.06, which is a 2.02 point improvement over the best baseline.