 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-PTQ: Drift-Aware Post-Training Quantization for Efficient Vision-Language-Action Models
Apr 13, 2026Vision-Language-Action models (VLAs) have demonstrated strong potential for embodied AI, yet their deployment on resource-limited robots remains challenging due to high memory and computational demands. While Post-Training Quantization (PTQ) provides an efficient solution, directly applying PTQ to VLAs often results in severe performance degradation during sequential control. We identify temporal error accumulation as a key factor, where quantization perturbations at the vision-language-to-action interface are progressively amplified, leading to kinematic drift in executed trajectories. To address this issue, we propose Drift-Aware Post-Training Quantization (DA-PTQ), which formulates quantization as a drift-aware optimization problem over sequential decision processes. DA-PTQ consists of two components: (1) Cross-Space Representation Compensation, which mitigates structured distortions between multimodal representations and action space to improve action consistency, and (2) Motion-Driven Mixed-Precision Allocation, which assigns bit-widths by minimizing trajectory-level motion errors. Extensive experiments show that DA-PTQ significantly reduces kinematic drift and achieves comparable performance to full-precision models under low-bit settings, enabling practical deployment of VLAs on resource-limited robotic platforms.
Non-Markovian Long-Horizon Robot Manipulation via Keyframe Chaining
Mar 02, 2026Existing Vision-Language-Action (VLA) models often struggle to generalize to long-horizon tasks due to their heavy reliance on immediate observations. While recent studies incorporate retrieval mechanisms or extend context windows to handle procedural tasks, they often struggle to capture Non-Markovian dependencies, where optimal actions rely solely on specific past states rather than the current observation. To address this, we introduce Keyframe-Chaining VLA, a framework that extracts and links key historical frames to model long-horizon dependencies. Specifically, we propose an automatic keyframe selector that learns a discriminative embedding space, effectively identifying distinct state transitions. To capture task-critical information, we design a progress-aware query mechanism that dynamically retrieves historical frames based on their temporal relevance to the current execution phase. These selected keyframes are integrated into the VLA as interleaved visual tokens, explicitly grounding the policy in the long-horizon temporal context. Finally, we introduce a suite of four Non-Markovian manipulation tasks built upon the ManiSkill simulator to measure task success rates. Experimental results demonstrate that our method achieves superior performance, effectively tackling robot manipulation tasks characterized by long-horizon temporal dependencies. Code is available at https://github.com/cytoplastm/KC-VLA.
Self-Correcting VLA: Online Action Refinement via Sparse World Imagination
Feb 25, 2026Standard vision-language-action (VLA) models rely on fitting statistical data priors, limiting their robust understanding of underlying physical dynamics. Reinforcement learning enhances physical grounding through exploration yet typically relies on external reward signals that remain isolated from the agent's internal states. World action models have emerged as a promising paradigm that integrates imagination and control to enable predictive planning. However, they rely on implicit context modeling, lacking explicit mechanisms for self-improvement. To solve these problems, we propose Self-Correcting VLA (SC-VLA), which achieve self-improvement by intrinsically guiding action refinement through sparse imagination. We first design sparse world imagination by integrating auxiliary predictive heads to forecast current task progress and future trajectory trends, thereby constraining the policy to encode short-term physical evolution. Then we introduce the online action refinement module to reshape progress-dependent dense rewards, adjusting trajectory orientation based on the predicted sparse future states. Evaluations on challenging robot manipulation tasks from simulation benchmarks and real-world settings demonstrate that SC-VLA achieve state-of-the-art performance, yielding the highest task throughput with 16% fewer steps and a 9% higher success rate than the best-performing baselines, alongside a 14% gain in real-world experiments. Code is available at https://github.com/Kisaragi0/SC-VLA.
MOTIF: Learning Action Motifs for Few-shot Cross-Embodiment Transfer
Feb 14, 2026While vision-language-action (VLA) models have advanced generalist robotic learning, cross-embodiment transfer remains challenging due to kinematic heterogeneity and the high cost of collecting sufficient real-world demonstrations to support fine-tuning. Existing cross-embodiment policies typically rely on shared-private architectures, which suffer from limited capacity of private parameters and lack explicit adaptation mechanisms. To address these limitations, we introduce MOTIF for efficient few-shot cross-embodiment transfer that decouples embodiment-agnostic spatiotemporal patterns, termed action motifs, from heterogeneous action data. Specifically, MOTIF first learns unified motifs via vector quantization with progress-aware alignment and embodiment adversarial constraints to ensure temporal and cross-embodiment consistency. We then design a lightweight predictor that predicts these motifs from real-time inputs to guide a flow-matching policy, fusing them with robot-specific states to enable action generation on new embodiments. Evaluations across both simulation and real-world environments validate the superiority of MOTIF, which significantly outperforms strong baselines in few-shot transfer scenarios by 6.5% in simulation and 43.7% in real-world settings. Code is available at https://github.com/buduz/MOTIF.
AC^2-VLA: Action-Context-Aware Adaptive Computation in Vision-Language-Action Models for Efficient Robotic Manipulation
Jan 27, 2026Vision-Language-Action (VLA) models have demonstrated strong performance in robotic manipulation, yet their closed-loop deployment is hindered by the high latency and compute cost of repeatedly running large vision-language backbones at every timestep. We observe that VLA inference exhibits structured redundancies across temporal, spatial, and depth dimensions, and that most existing efficiency methods ignore action context, despite its central role in embodied tasks. To address this gap, we propose Action-Context-aware Adaptive Computation for VLA models (AC^2-VLA), a unified framework that conditions computation on current visual observations, language instructions, and previous action states. Based on this action-centric context, AC^2-VLA adaptively performs cognition reuse across timesteps, token pruning, and selective execution of model components within a unified mechanism. To train the adaptive policy, we introduce an action-guided self-distillation scheme that preserves the behavior of the dense VLA policy while enabling structured sparsification that transfers across tasks and settings. Extensive experiments on robotic manipulation benchmarks show that AC^2-VLA achieves up to a 1.79\times speedup while reducing FLOPs to 29.4% of the dense baseline, with comparable task success.
A Survey on fMRI-based Brain Decoding for Reconstructing Multimodal Stimuli
Mar 20, 2025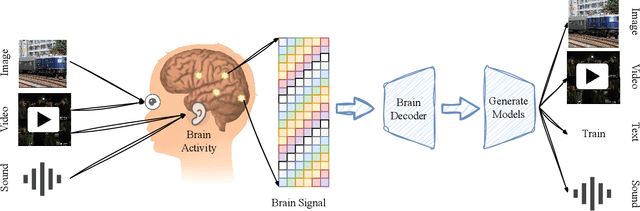
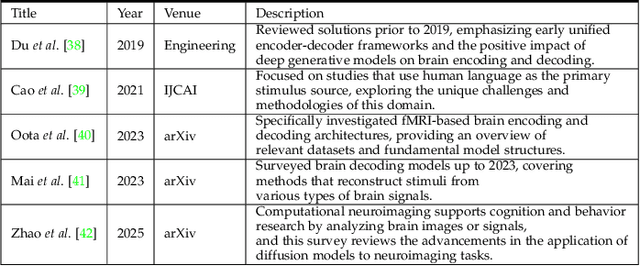
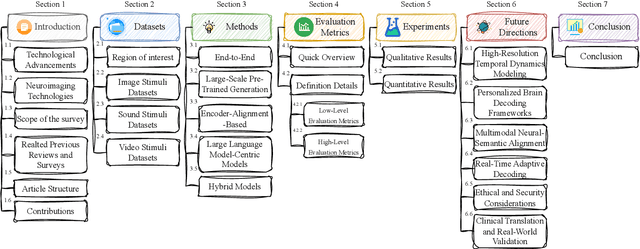
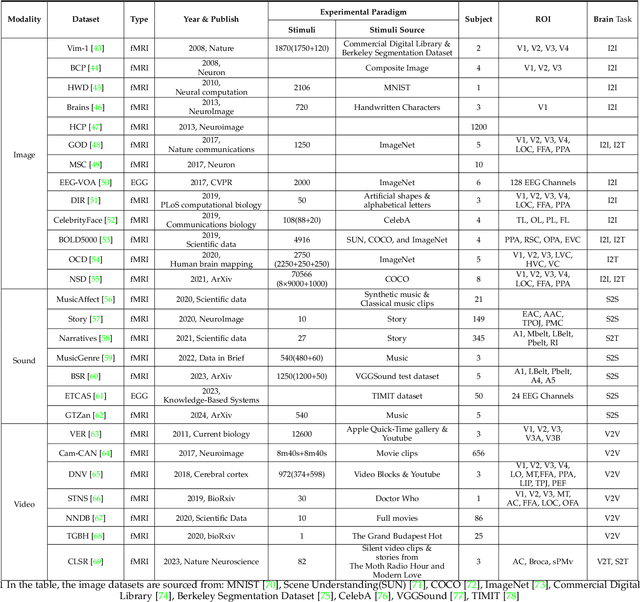
In daily life, we encounter diverse external stimuli, such as images, sounds, and videos. As research in multimodal stimuli and neuroscience advances, fMRI-based brain decoding has become a key tool for understanding brain perception and its complex cognitive processes. Decoding brain signals to reconstruct stimuli not only reveals intricate neural mechanisms but also drives progress in AI, disease treatment, and brain-computer interfaces. Recent advancements in neuroimaging and image generation models have significantly improved fMRI-based decoding. While fMRI offers high spatial resolution for precise brain activity mapping, its low temporal resolution and signal noise pose challenges. Meanwhile, techniques like GANs, VAEs, and Diffusion Models have enhanced reconstructed image quality, and multimodal pre-trained models have boosted cross-modal decoding tasks. This survey systematically reviews recent progress in fMRI-based brain decoding, focusing on stimulus reconstruction from passive brain signals. It summarizes datasets, relevant brain regions, and categorizes existing methods by model structure. Additionally, it evaluates model performance and discusses their effectiveness. Finally, it identifies key challenges and proposes future research directions, offering valuable insights for the field. For more information and resources related to this survey, visit https://github.com/LpyNow/BrainDecodingImage.
Split to Merge: Unifying Separated Modalities for Unsupervised Domain Adaptation
Mar 11, 2024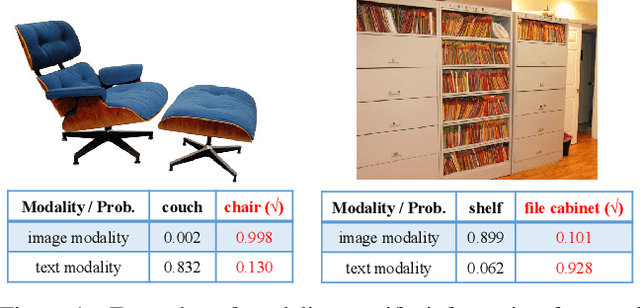
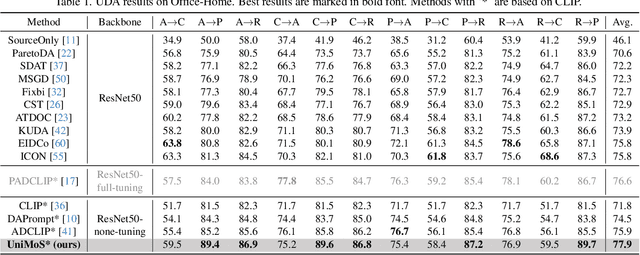
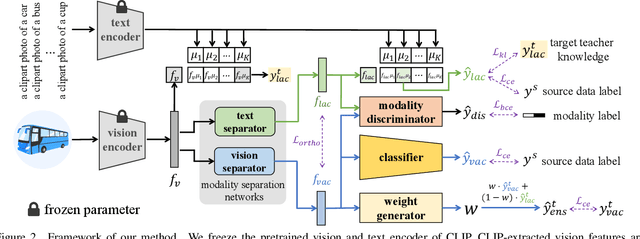
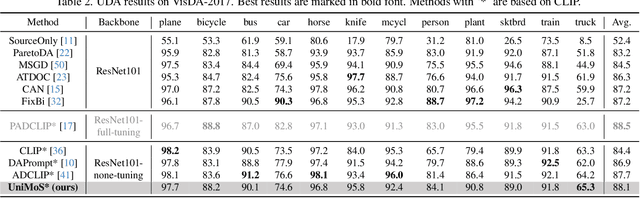
Large vision-language models (VLMs) like CLIP have demonstrated good zero-shot learning performance in the unsupervised domain adaptation task. Yet, most transfer approaches for VLMs focus on either the language or visual branches, overlooking the nuanced interplay between both modalities. In this work, we introduce a Unified Modality Separation (UniMoS) framework for unsupervised domain adaptation. Leveraging insights from modality gap studies, we craft a nimble modality separation network that distinctly disentangles CLIP's features into language-associated and vision-associated components. Our proposed Modality-Ensemble Training (MET) method fosters the exchange of modality-agnostic information while maintaining modality-specific nuances. We align features across domains using a modality discriminator. Comprehensive evaluations on three benchmarks reveal our approach sets a new state-of-the-art with minimal computational costs. Code: https://github.com/TL-UESTC/UniMoS
Agile Multi-Source-Free Domain Adaptation
Mar 08, 2024



Efficiently utilizing rich knowledge in pretrained models has become a critical topic in the era of large models. This work focuses on adaptively utilizing knowledge from multiple source-pretrained models to an unlabeled target domain without accessing the source data. Despite being a practically useful setting, existing methods require extensive parameter tuning over each source model, which is computationally expensive when facing abundant source domains or larger source models. To address this challenge, we propose a novel approach which is free of the parameter tuning over source backbones. Our technical contribution lies in the Bi-level ATtention ENsemble (Bi-ATEN) module, which learns both intra-domain weights and inter-domain ensemble weights to achieve a fine balance between instance specificity and domain consistency. By slightly tuning source bottlenecks, we achieve comparable or even superior performance on a challenging benchmark DomainNet with less than 3% trained parameters and 8 times of throughput compared with SOTA method. Furthermore, with minor modifications, the proposed module can be easily equipped to existing methods and gain more than 4% performance boost. Code is available at https://github.com/TL-UESTC/Bi-ATEN.
Domain-Agnostic Mutual Prompting for Unsupervised Domain Adaptation
Mar 05, 2024Conventional Unsupervised Domain Adaptation (UDA) strives to minimize distribution discrepancy between domains, which neglects to harness rich semantics from data and struggles to handle complex domain shifts. A promising technique is to leverage the knowledge of large-scale pre-trained vision-language models for more guided adaptation. Despite some endeavors, current methods often learn textual prompts to embed domain semantics for source and target domains separately and perform classification within each domain, limiting cross-domain knowledge transfer. Moreover, prompting only the language branch lacks flexibility to adapt both modalities dynamically. To bridge this gap, we propose Domain-Agnostic Mutual Prompting (DAMP) to exploit domain-invariant semantics by mutually aligning visual and textual embeddings. Specifically, the image contextual information is utilized to prompt the language branch in a domain-agnostic and instance-conditioned way. Meanwhile, visual prompts are imposed based on the domain-agnostic textual prompt to elicit domain-invariant visual embeddings. These two branches of prompts are learned mutually with a cross-attention module and regularized with a semantic-consistency loss and an instance-discrimination contrastive loss. Experiments on three UDA benchmarks demonstrate the superiority of DAMP over state-of-the-art approaches.
Cross-Modal Retrieval: A Systematic Review of Methods and Future Directions
Aug 28, 2023



With the exponential surge in diverse multi-modal data, traditional uni-modal retrieval methods struggle to meet the needs of users demanding access to data from various modalities. To address this, cross-modal retrieval has emerged, enabling interaction across modalities, facilitating semantic matching, and leveraging complementarity and consistency between different modal data. Although prior literature undertook a review of the cross-modal retrieval field, it exhibits numerous deficiencies pertaining to timeliness, taxonomy, and comprehensiveness. This paper conducts a comprehensive review of cross-modal retrieval's evolution, spanning from shallow statistical analysis techniques to vision-language pre-training models. Commencing with a comprehensive taxonomy grounded in machine learning paradigms, mechanisms, and models, the paper then delves deeply into the principles and architectures underpinning existing cross-modal retrieval methods. Furthermore, it offers an overview of widely used benchmarks, metrics, and performances. Lastly, the paper probes the prospects and challenges that confront contemporary cross-modal retrieval, while engaging in a discourse on potential directions for further progress in the field. To facilitate the research on cross-modal retrieval, we develop an open-source code repository at https://github.com/BMC-SDNU/Cross-Modal-Retrieval.