 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Multi-Domain Benchmark for Micro-Action Recognition and Detection
Jun 12, 2026Micro-actions are short-duration, low-amplitude subtle body movements at the whole-body level that can reveal latent intentions, involuntary reactions, and fine-grained affective changes. Our previous MA-52 benchmark has provided an important foundation for micro-action recognition, but it remains limited in scale, scene diversity, task coverage, and evaluation protocols. To advance micro-action analysis toward more realistic and comprehensive settings, we introduce MMA-82, a large-scale multi-domain extension of MA-52. MMA-82 expands the label space from 52 to 82 fine-grained micro-action categories and covers four distinct domains, including laboratory interviews, street interviews, psychiatric patient interviews, and emotion-rich television videos, resulting in 77,856 annotated instances from 454 subjects. Built upon MMA-82, we establish two core tasks: Micro-Action Recognition and Multi-label Micro-Action Detection. For recognition, we further define in-domain and cross-domain protocols, including few-shot and zero-shot settings, to evaluate model robustness, transferability, and generalization. Extensive experiments show that current methods still struggle with realistic micro-action understanding, especially under domain shift, long-tailed category distributions, and complex temporal localization. Beyond benchmarking, we investigate the relationship between micro-actions and emotion, showing that micro-actions are strongly associated with emotional states and provide complementary cues to facial micro-expressions for improved emotion recognition. These results demonstrate that MMA-82 serves as a comprehensive and challenging benchmark for realistic micro-action analysis and a valuable resource for human-centered AI. MMA-82 is available at https://github.com/LpyNow/MMA-82.
A Multi-Modal Framework with Cross-Subject Pseudo-Labeling and Semantic Alignment for Micro-Gesture Recognition
Jun 11, 2026Micro-gestures (MGs) are spontaneous and subtle body movements that frequently convey hidden human emotions. Recognizing MGs in untrimmed videos remains highly challenging due to their extremely low signal-to-noise ratio, severe long-tailed class distribution, and the inherent domain shift encountered in cross-subject evaluation scenarios. In this paper, we propose a comprehensive multi-modal framework for Track 1 of the 4th MiGA-IJCAI Challenge. To capture fine-grained representations, we design a saliency-guided multi-modal extraction pipeline integrating 68-keypoint skeleton joint coordinates, 3D heatmap volumes, and high-resolution RGB visual features. We introduce a gentle square-root smoothed weighting mechanism paired with an Orthogonal Semantic Embedding Loss to protect tail classes without compromising overall recognition capabilities. More importantly, to bridge the cross-subject generalization gap, we propose a Cross-Modal Pseudo-Labeling (CMPL) strategy for unsupervised domain adaptation, which significantly boosts single-modal robustness. A temperature-scaled soft-voting mechanism is finally utilized to alleviate overconfidence during late fusion. Extensive experiments demonstrate that our framework achieves a competitive F1-score of 68.13\%, securing the 4th place.
Measuring language complexity from hierarchical reuse of recurring patterns
Jun 10, 2026We introduce the ladderpath index as a measure of language complexity grounded in algorithmic information theory. It counts the minimum steps needed to reconstruct a sequence through hierarchical reuse of repeated substructures, capturing an exactly computable but constrained form of algorithmic compressibility related to, but distinct from, Kolmogorov complexity. We apply the ladderpath approach to 21 parallel corpora from the Parallel Universal Dependencies dataset. The ladderpath index is approximately invariant across the languages, and varies much less than the corpus length. This is more pronounced when all corpora are mapped to a unified binary representation, providing evidence for the equi-complexity hypothesis from a representation-independent perspective. We also observe trade-offs between character inventory size and corpus length, and between vocabulary-level and corpus-level reconstruction complexity, supporting the trade-off hypothesis that total complexity is conserved and redistributed across linguistic levels. The reusable substructures identified by the ladderpath approach, without any linguistic input, overlap with words and morphological components attested in the natural vocabulary. The hierarchical reuse captured by the ladderpath approach parallels the chunking mechanisms proposed in cognitive science, where the human cognitive system compresses linguistic input into nested, reusable units under shared memory and processing constraints. This connection between cognitive chunking and the ladderpath approach provides a new interpretation for the equi-complexity and trade-off hypotheses, grounding both in the shared cognitive architecture that underlies language processing across human languages.
Motion Reinforces Appearance: RGB-Skeleton Gated Residual Fusion for Micro-Gesture Online Recognition
Jun 10, 2026Micro-gesture analysis attracts increasing attention for inferring spontaneous emotion from subtle body movements. Micro-gesture online recognition, which localizes and classifies each gesture instance in untrimmed videos, is a core task in the 4th EI-MiGA-IJCAI Challenge. Compared with typical temporal action detection, MGR emphasizes the localization and classification of actions, requiring the model to output the start time, end time, and category of each micro-gesture. Moreover, since micro-gestures are highly spontaneous, relying solely on a single modality makes it difficult to capture the complete and accurate multi-modal cues. In this work, we propose DyFADet+, which extends DyFADet into a dual-stream RGB-skeleton framework. In our model, both modalities are projected into shared multi-scale temporal embeddings and fused through a gated residual module, which adaptively injects skeleton motion into the RGB representation rather than using naive concatenation. Finally, these fused features are decoded by a Dynamic TAD head for online classification and boundary regression. On the SMG dataset, our method achieves an F1 score of 40.88, ranking 2nd in the Micro-gesture Online Recognition track.
DualSentinel: A Lightweight Framework for Detecting Targeted Attacks in Black-box LLM via Dual Entropy Lull Pattern
Mar 02, 2026Recent intelligent systems integrate powerful Large Language Models (LLMs) through APIs, but their trustworthiness may be critically undermined by targeted attacks like backdoor and prompt injection attacks, which secretly force LLMs to generate specific malicious sequences. Existing defensive approaches for such threats typically rely on high access rights, impose prohibitive costs, and hinder normal inference, rendering them impractical for real-world scenarios. To solve these limitations, we introduce DualSentinel, a lightweight and unified defense framework that can accurately and promptly detect the activation of targeted attacks alongside the LLM generation process. We first identify a characteristic of compromised LLMs, termed Entropy Lull: when a targeted attack successfully hijacks the generation process, the LLM exhibits a distinct period of abnormally low and stable token probability entropy, indicating it is following a fixed path rather than making creative choices. DualSentinel leverages this pattern by developing an innovative dual-check approach. It first employs a magnitude and trend-aware monitoring method to proactively and sensitively flag an entropy lull pattern at runtime. Upon such flagging, it triggers a lightweight yet powerful secondary verification based on task-flipping. An attack is confirmed only if the entropy lull pattern persists across both the original and the flipped task, proving that the LLM's output is coercively controlled. Extensive evaluations show that DualSentinel is both highly effective (superior detection accuracy with near-zero false positives) and remarkably efficient (negligible additional cost), offering a truly practical path toward securing deployed LLMs. The source code can be accessed at https://doi.org/10.5281/zenodo.18479273.
A Comparison of Polynomial-Based Tree Clustering Methods
Jan 13, 2026Tree structures appear in many fields of the life sciences, including phylogenetics, developmental biology and nucleic acid structures. Trees can be used to represent RNA secondary structures, which directly relate to the function of non-coding RNAs. Recent developments in sequencing technology and artificial intelligence have yielded numerous biological data that can be represented with tree structures. This requires novel methods for tree structure data analytics. Tree polynomials provide a computationally efficient, interpretable and comprehensive way to encode tree structures as matrices, which are compatible with most data analytics tools. Machine learning methods based on the Canberra distance between tree polynomials have been introduced to analyze phylogenies and nucleic acid structures. In this paper, we compare the performance of different distances in tree clustering methods based on a tree distinguishing polynomial. We also implement two basic autoencoder models for clustering trees using the polynomial. We find that the distance based methods with entry-level normalized distances have the highest clustering accuracy among the compared methods.
A Survey on fMRI-based Brain Decoding for Reconstructing Multimodal Stimuli
Mar 20, 2025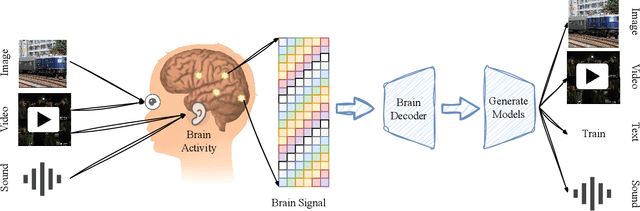
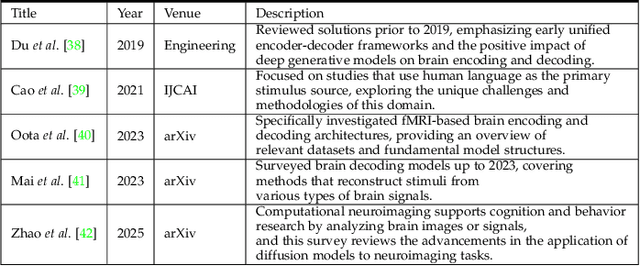
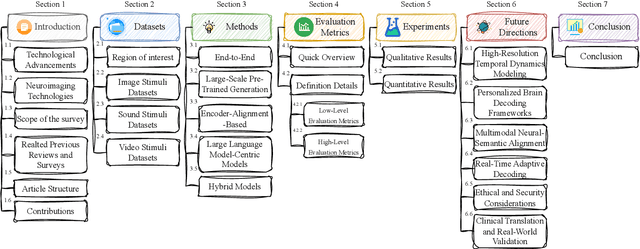
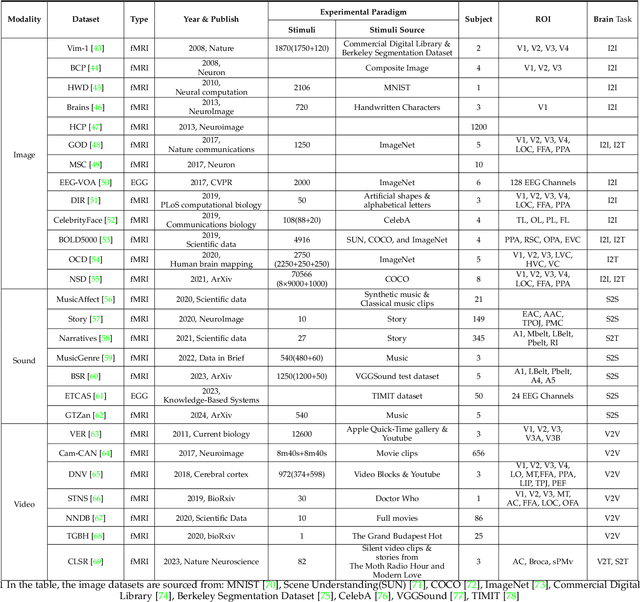
In daily life, we encounter diverse external stimuli, such as images, sounds, and videos. As research in multimodal stimuli and neuroscience advances, fMRI-based brain decoding has become a key tool for understanding brain perception and its complex cognitive processes. Decoding brain signals to reconstruct stimuli not only reveals intricate neural mechanisms but also drives progress in AI, disease treatment, and brain-computer interfaces. Recent advancements in neuroimaging and image generation models have significantly improved fMRI-based decoding. While fMRI offers high spatial resolution for precise brain activity mapping, its low temporal resolution and signal noise pose challenges. Meanwhile, techniques like GANs, VAEs, and Diffusion Models have enhanced reconstructed image quality, and multimodal pre-trained models have boosted cross-modal decoding tasks. This survey systematically reviews recent progress in fMRI-based brain decoding, focusing on stimulus reconstruction from passive brain signals. It summarizes datasets, relevant brain regions, and categorizes existing methods by model structure. Additionally, it evaluates model performance and discusses their effectiveness. Finally, it identifies key challenges and proposes future research directions, offering valuable insights for the field. For more information and resources related to this survey, visit https://github.com/LpyNow/BrainDecodingImage.
Timely reliable Bayesian decision-making enabled using memristors
Dec 07, 2024Brains perform timely reliable decision-making by Bayes theorem. Bayes theorem quantifies events as probabilities and, through probability rules, renders the decisions. Learning from this, applying Bayes theorem in practical problems can visualize the potential risks and decision confidence, thereby enabling efficient user-scene interactions. However, given the probabilistic nature, implementing Bayes theorem with the conventional deterministic computing can inevitably induce excessive computational cost and decision latency. Herein, we propose a probabilistic computing approach using memristors to implement Bayes theorem. We integrate volatile memristors with Boolean logics and, by exploiting the volatile stochastic switching of the memristors, realize Boolean operations with statistical probabilities and correlations, key for enabling Bayes theorem. To practically demonstrate the effectiveness of our memristor-enabled Bayes theorem approach in user-scene interactions, we design lightweight Bayesian inference and fusion operators using our probabilistic logics and apply the operators in road scene parsing for self-driving, including route planning and obstacle detection. The results show that our operators can achieve reliable decisions at a rate over 2,500 frames per second, outperforming human decision-making and the existing driving assistance systems.
MMAD: Multi-label Micro-Action Detection in Videos
Jul 07, 2024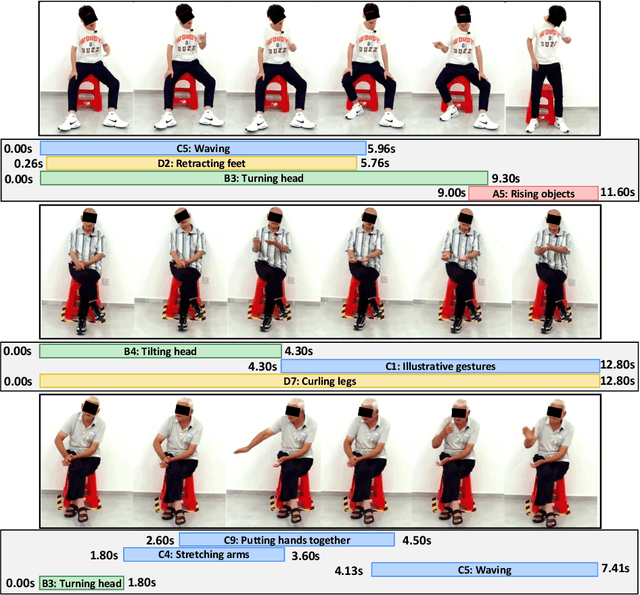

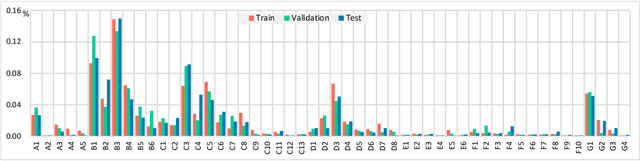
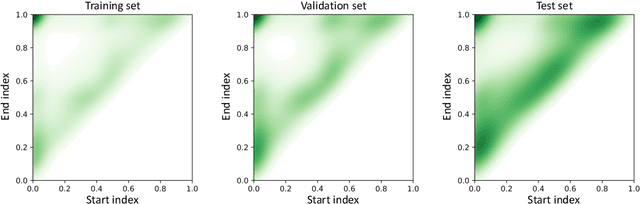
Human body actions are an important form of non-verbal communication in social interactions. This paper focuses on a specific subset of body actions known as micro-actions, which are subtle, low-intensity body movements that provide a deeper understanding of inner human feelings. In real-world scenarios, human micro-actions often co-occur, with multiple micro-actions overlapping in time, such as simultaneous head and hand movements. However, current research primarily focuses on recognizing individual micro-actions while overlooking their co-occurring nature. To narrow this gap, we propose a new task named Multi-label Micro-Action Detection (MMAD), which involves identifying all micro-actions in a given short video, determining their start and end times, and categorizing them. Achieving this requires a model capable of accurately capturing both long-term and short-term action relationships to locate and classify multiple micro-actions. To support the MMAD task, we introduce a new dataset named Multi-label Micro-Action-52 (MMA-52), specifically designed to facilitate the detailed analysis and exploration of complex human micro-actions. The proposed MMA-52 dataset is available at: https://github.com/VUT-HFUT/Micro-Action.
Micro-gesture Online Recognition using Learnable Query Points
Jul 05, 2024In this paper, we briefly introduce the solution developed by our team, HFUT-VUT, for the Micro-gesture Online Recognition track in the MiGA challenge at IJCAI 2024. The Micro-gesture Online Recognition task involves identifying the category and locating the start and end times of micro-gestures in video clips. Compared to the typical Temporal Action Detection task, the Micro-gesture Online Recognition task focuses more on distinguishing between micro-gestures and pinpointing the start and end times of actions. Our solution ranks 2nd in the Micro-gesture Online Recognition track.