 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimely reliable Bayesian decision-making enabled using memristors
Dec 07, 2024Brains perform timely reliable decision-making by Bayes theorem. Bayes theorem quantifies events as probabilities and, through probability rules, renders the decisions. Learning from this, applying Bayes theorem in practical problems can visualize the potential risks and decision confidence, thereby enabling efficient user-scene interactions. However, given the probabilistic nature, implementing Bayes theorem with the conventional deterministic computing can inevitably induce excessive computational cost and decision latency. Herein, we propose a probabilistic computing approach using memristors to implement Bayes theorem. We integrate volatile memristors with Boolean logics and, by exploiting the volatile stochastic switching of the memristors, realize Boolean operations with statistical probabilities and correlations, key for enabling Bayes theorem. To practically demonstrate the effectiveness of our memristor-enabled Bayes theorem approach in user-scene interactions, we design lightweight Bayesian inference and fusion operators using our probabilistic logics and apply the operators in road scene parsing for self-driving, including route planning and obstacle detection. The results show that our operators can achieve reliable decisions at a rate over 2,500 frames per second, outperforming human decision-making and the existing driving assistance systems.
Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
Jan 18, 2024
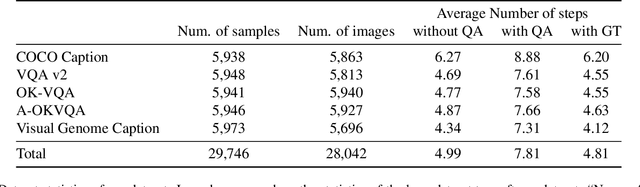


The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of Large Multi-Modal Models (LMMs) that are not only accurate but also have explicit reasoning capabilities. This paper presents a novel approach to imbue an LMM with the ability to conduct explicit reasoning based on visual content and textual instructions. We introduce a system that can ask a question to acquire necessary knowledge, thereby enhancing the robustness and explicability of the reasoning process. Our method comprises the development of a novel dataset generated by a Large Language Model (LLM), designed to promote chain-of-thought reasoning combined with a question-asking mechanism. We designed an LMM, which has high capabilities on region awareness to address the intricate requirements of image-text alignment. The model undergoes a three-stage training phase, starting with large-scale image-text alignment using a large-scale datasets, followed by instruction tuning, and fine-tuning with a focus on chain-of-thought reasoning. The results demonstrate a stride toward a more robust, accurate, and interpretable LMM, capable of reasoning explicitly and seeking information proactively when confronted with ambiguous visual input.