 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Calibrating Ambiguous Samples for Micro-Action Recognition
Dec 19, 2024



Micro-Action Recognition (MAR) has gained increasing attention due to its crucial role as a form of non-verbal communication in social interactions, with promising potential for applications in human communication and emotion analysis. However, current approaches often overlook the inherent ambiguity in micro-actions, which arises from the wide category range and subtle visual differences between categories. This oversight hampers the accuracy of micro-action recognition. In this paper, we propose a novel Prototypical Calibrating Ambiguous Network (\textbf{PCAN}) to unleash and mitigate the ambiguity of MAR. \textbf{Firstly}, we employ a hierarchical action-tree to identify the ambiguous sample, categorizing them into distinct sets of ambiguous samples of false negatives and false positives, considering both body- and action-level categories. \textbf{Secondly}, we implement an ambiguous contrastive refinement module to calibrate these ambiguous samples by regulating the distance between ambiguous samples and their corresponding prototypes. This calibration process aims to pull false negative ($\mathbb{FN}$) samples closer to their respective prototypes and push false positive ($\mathbb{FP}$) samples apart from their affiliated prototypes. In addition, we propose a new prototypical diversity amplification loss to strengthen the model's capacity by amplifying the differences between different prototypes. \textbf{Finally}, we propose a prototype-guided rectification to rectify prediction by incorporating the representability of prototypes. Extensive experiments conducted on the benchmark dataset demonstrate the superior performance of our method compared to existing approaches. The code is available at https://github.com/kunli-cs/PCAN.
Prototype Learning for Micro-gesture Classification
Aug 06, 2024In this paper, we briefly introduce the solution developed by our team, HFUT-VUT, for the track of Micro-gesture Classification in the MiGA challenge at IJCAI 2024. The task of micro-gesture classification task involves recognizing the category of a given video clip, which focuses on more fine-grained and subtle body movements compared to typical action recognition tasks. Given the inherent complexity of micro-gesture recognition, which includes large intra-class variability and minimal inter-class differences, we utilize two innovative modules, i.e., the cross-modal fusion module and prototypical refinement module, to improve the discriminative ability of MG features, thereby improving the classification accuracy. Our solution achieved significant success, ranking 1st in the track of Micro-gesture Classification. We surpassed the performance of last year's leading team by a substantial margin, improving Top-1 accuracy by 6.13%.
MMAD: Multi-label Micro-Action Detection in Videos
Jul 07, 2024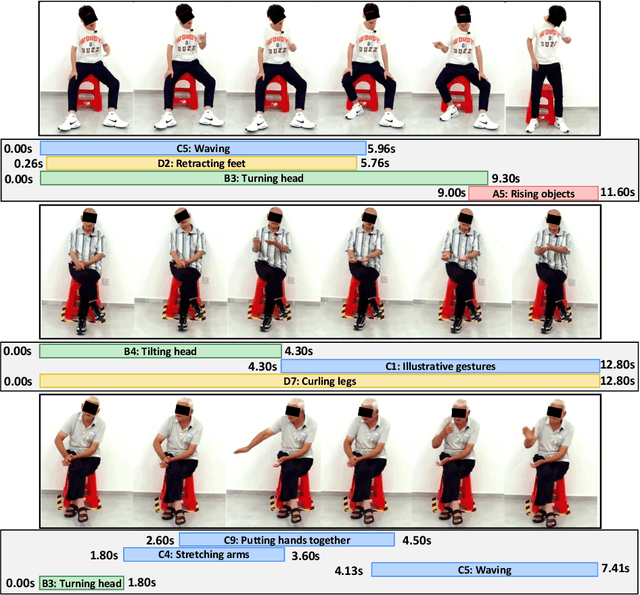

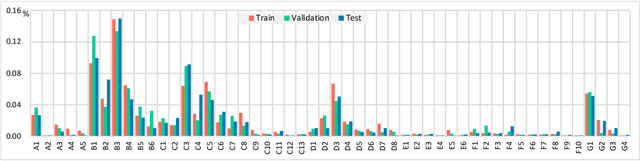
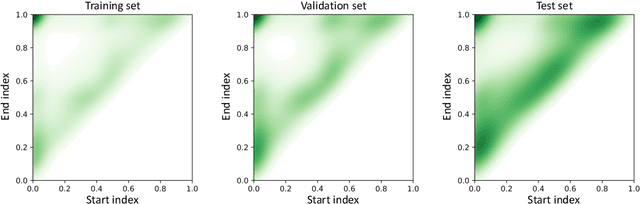
Human body actions are an important form of non-verbal communication in social interactions. This paper focuses on a specific subset of body actions known as micro-actions, which are subtle, low-intensity body movements that provide a deeper understanding of inner human feelings. In real-world scenarios, human micro-actions often co-occur, with multiple micro-actions overlapping in time, such as simultaneous head and hand movements. However, current research primarily focuses on recognizing individual micro-actions while overlooking their co-occurring nature. To narrow this gap, we propose a new task named Multi-label Micro-Action Detection (MMAD), which involves identifying all micro-actions in a given short video, determining their start and end times, and categorizing them. Achieving this requires a model capable of accurately capturing both long-term and short-term action relationships to locate and classify multiple micro-actions. To support the MMAD task, we introduce a new dataset named Multi-label Micro-Action-52 (MMA-52), specifically designed to facilitate the detailed analysis and exploration of complex human micro-actions. The proposed MMA-52 dataset is available at: https://github.com/VUT-HFUT/Micro-Action.
Micro-gesture Online Recognition using Learnable Query Points
Jul 05, 2024In this paper, we briefly introduce the solution developed by our team, HFUT-VUT, for the Micro-gesture Online Recognition track in the MiGA challenge at IJCAI 2024. The Micro-gesture Online Recognition task involves identifying the category and locating the start and end times of micro-gestures in video clips. Compared to the typical Temporal Action Detection task, the Micro-gesture Online Recognition task focuses more on distinguishing between micro-gestures and pinpointing the start and end times of actions. Our solution ranks 2nd in the Micro-gesture Online Recognition track.
SimPB: A Single Model for 2D and 3D Object Detection from Multiple Cameras
Mar 15, 2024



The field of autonomous driving has attracted considerable interest in approaches that directly infer 3D objects in the Bird's Eye View (BEV) from multiple cameras. Some attempts have also explored utilizing 2D detectors from single images to enhance the performance of 3D detection. However, these approaches rely on a two-stage process with separate detectors, where the 2D detection results are utilized only once for token selection or query initialization. In this paper, we present a single model termed SimPB, which simultaneously detects 2D objects in the perspective view and 3D objects in the BEV space from multiple cameras. To achieve this, we introduce a hybrid decoder consisting of several multi-view 2D decoder layers and several 3D decoder layers, specifically designed for their respective detection tasks. A Dynamic Query Allocation module and an Adaptive Query Aggregation module are proposed to continuously update and refine the interaction between 2D and 3D results, in a cyclic 3D-2D-3D manner. Additionally, Query-group Attention is utilized to strengthen the interaction among 2D queries within each camera group. In the experiments, we evaluate our method on the nuScenes dataset and demonstrate promising results for both 2D and 3D detection tasks. Our code is available at: https://github.com/nullmax-vision/SimPB.
Dual-Path Temporal Map Optimization for Make-up Temporal Video Grounding
Sep 12, 2023



Make-up temporal video grounding (MTVG) aims to localize the target video segment which is semantically related to a sentence describing a make-up activity, given a long video. Compared with the general video grounding task, MTVG focuses on meticulous actions and changes on the face. The make-up instruction step, usually involving detailed differences in products and facial areas, is more fine-grained than general activities (e.g, cooking activity and furniture assembly). Thus, existing general approaches cannot locate the target activity effectually. More specifically, existing proposal generation modules are not yet fully developed in providing semantic cues for the more fine-grained make-up semantic comprehension. To tackle this issue, we propose an effective proposal-based framework named Dual-Path Temporal Map Optimization Network (DPTMO) to capture fine-grained multimodal semantic details of make-up activities. DPTMO extracts both query-agnostic and query-guided features to construct two proposal sets and uses specific evaluation methods for the two sets. Different from the commonly used single structure in previous methods, our dual-path structure can mine more semantic information in make-up videos and distinguish fine-grained actions well. These two candidate sets represent the cross-modal makeup video-text similarity and multi-modal fusion relationship, complementing each other. Each set corresponds to its respective optimization perspective, and their joint prediction enhances the accuracy of video timestamp prediction. Comprehensive experiments on the YouMakeup dataset demonstrate our proposed dual structure excels in fine-grained semantic comprehension.
Data Augmentation for Human Behavior Analysis in Multi-Person Conversations
Aug 03, 2023



In this paper, we present the solution of our team HFUT-VUT for the MultiMediate Grand Challenge 2023 at ACM Multimedia 2023. The solution covers three sub-challenges: bodily behavior recognition, eye contact detection, and next speaker prediction. We select Swin Transformer as the baseline and exploit data augmentation strategies to address the above three tasks. Specifically, we crop the raw video to remove the noise from other parts. At the same time, we utilize data augmentation to improve the generalization of the model. As a result, our solution achieves the best results of 0.6262 for bodily behavior recognition in terms of mean average precision and the accuracy of 0.7771 for eye contact detection on the corresponding test set. In addition, our approach also achieves comparable results of 0.5281 for the next speaker prediction in terms of unweighted average recall.
Joint Skeletal and Semantic Embedding Loss for Micro-gesture Classification
Jul 20, 2023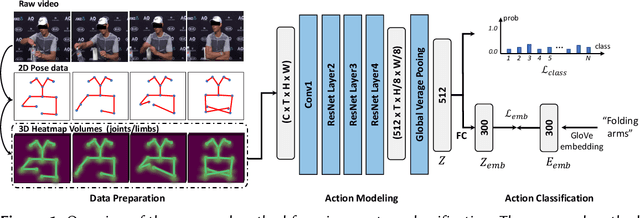

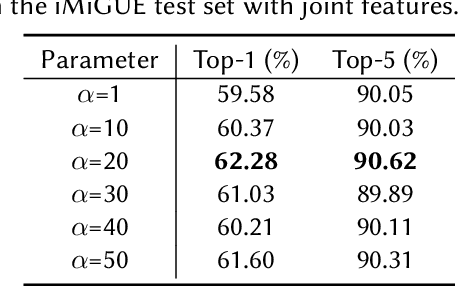
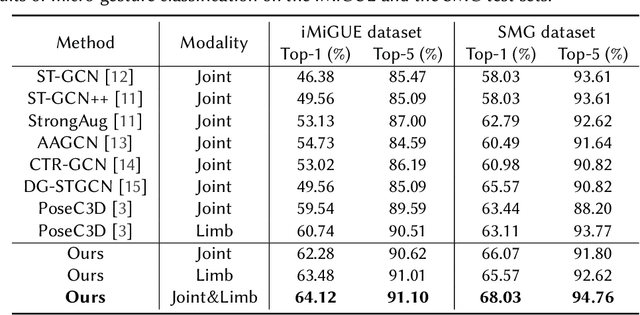
In this paper, we briefly introduce the solution of our team HFUT-VUT for the Micros-gesture Classification in the MiGA challenge at IJCAI 2023. The micro-gesture classification task aims at recognizing the action category of a given video based on the skeleton data. For this task, we propose a 3D-CNNs-based micro-gesture recognition network, which incorporates a skeletal and semantic embedding loss to improve action classification performance. Finally, we rank 1st in the Micro-gesture Classification Challenge, surpassing the second-place team in terms of Top-1 accuracy by 1.10%.
A Large Population Size Can Be Unhelpful in Evolutionary Algorithms
Aug 11, 2012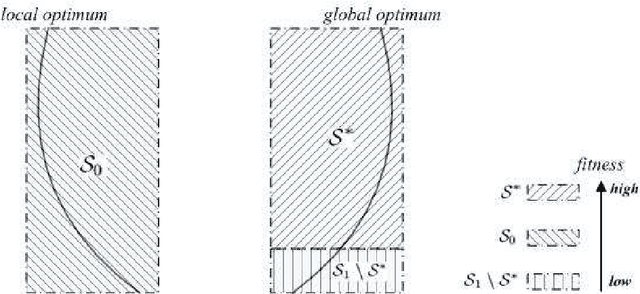
The utilization of populations is one of the most important features of evolutionary algorithms (EAs). There have been many studies analyzing the impact of different population sizes on the performance of EAs. However, most of such studies are based computational experiments, except for a few cases. The common wisdom so far appears to be that a large population would increase the population diversity and thus help an EA. Indeed, increasing the population size has been a commonly used strategy in tuning an EA when it did not perform as well as expected for a given problem. He and Yao (2002) showed theoretically that for some problem instance classes, a population can help to reduce the runtime of an EA from exponential to polynomial time. This paper analyzes the role of population further in EAs and shows rigorously that large populations may not always be useful. Conditions, under which large populations can be harmful, are discussed in this paper. Although the theoretical analysis was carried out on one multi-modal problem using a specific type of EAs, it has much wider implications. The analysis has revealed certain problem characteristics, which can be either the problem considered here or other problems, that lead to the disadvantages of large population sizes. The analytical approach developed in this paper can also be applied to analyzing EAs on other problems.
* 25 pages, 1 figure
The Impact of Mutation Rate on the Computation Time of Evolutionary Dynamic Optimization
Jun 03, 2011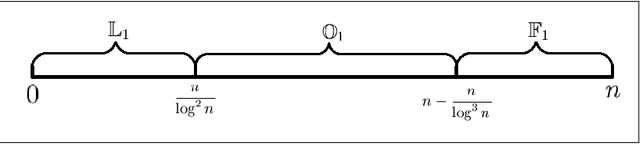
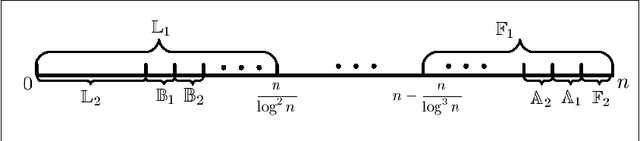
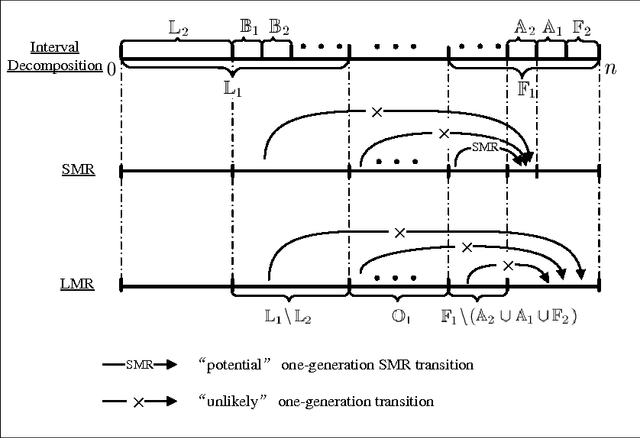
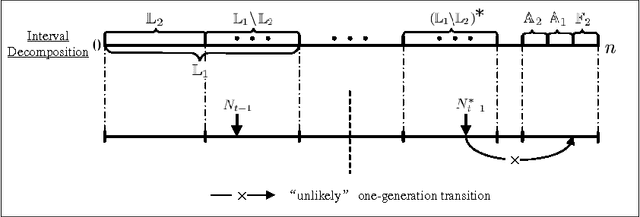
Mutation has traditionally been regarded as an important operator in evolutionary algorithms. In particular, there have been many experimental studies which showed the effectiveness of adapting mutation rates for various static optimization problems. Given the perceived effectiveness of adaptive and self-adaptive mutation for static optimization problems, there have been speculations that adaptive and self-adaptive mutation can benefit dynamic optimization problems even more since adaptation and self-adaptation are capable of following a dynamic environment. However, few theoretical results are available in analyzing rigorously evolutionary algorithms for dynamic optimization problems. It is unclear when adaptive and self-adaptive mutation rates are likely to be useful for evolutionary algorithms in solving dynamic optimization problems. This paper provides the first rigorous analysis of adaptive mutation and its impact on the computation times of evolutionary algorithms in solving certain dynamic optimization problems. More specifically, for both individual-based and population-based EAs, we have shown that any time-variable mutation rate scheme will not significantly outperform a fixed mutation rate on some dynamic optimization problem instances. The proofs also offer some insights into conditions under which any time-variable mutation scheme is unlikely to be useful and into the relationships between the problem characteristics and algorithmic features (e.g., different mutation schemes).