 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiMeng-Xpiler: Transcompiling Tensor Programs for Deep Learning Systems with a Neural-Symbolic Approach
May 04, 2025Heterogeneous deep learning systems (DLS) such as GPUs and ASICs have been widely deployed in industrial data centers, which requires to develop multiple low-level tensor programs for different platforms. An attractive solution to relieve the programming burden is to transcompile the legacy code of one platform to others. However, current transcompilation techniques struggle with either tremendous manual efforts or functional incorrectness, rendering "Write Once, Run Anywhere" of tensor programs an open question. We propose a novel transcompiler, i.e., QiMeng-Xpiler, for automatically translating tensor programs across DLS via both large language models (LLMs) and symbolic program synthesis, i.e., neural-symbolic synthesis. The key insight is leveraging the powerful code generation ability of LLM to make costly search-based symbolic synthesis computationally tractable. Concretely, we propose multiple LLM-assisted compilation passes via pre-defined meta-prompts for program transformation. During each program transformation, efficient symbolic program synthesis is employed to repair incorrect code snippets with a limited scale. To attain high performance, we propose a hierarchical auto-tuning approach to systematically explore both the parameters and sequences of transformation passes. Experiments on 4 DLS with distinct programming interfaces, i.e., Intel DL Boost with VNNI, NVIDIA GPU with CUDA, AMD MI with HIP, and Cambricon MLU with BANG, demonstrate that QiMeng-Xpiler correctly translates different tensor programs at the accuracy of 95% on average, and the performance of translated programs achieves up to 2.0x over vendor-provided manually-optimized libraries. As a result, the programming productivity of DLS is improved by up to 96.0x via transcompiling legacy tensor programs.
Ex3: Automatic Novel Writing by Extracting, Excelsior and Expanding
Aug 16, 2024



Generating long-term texts such as novels using artificial intelligence has always been a challenge. A common approach is to use large language models (LLMs) to construct a hierarchical framework that first plans and then writes. Despite the fact that the generated novels reach a sufficient length, they exhibit poor logical coherence and appeal in their plots and deficiencies in character and event depiction, ultimately compromising the overall narrative quality. In this paper, we propose a method named Extracting Excelsior and Expanding. Ex3 initially extracts structure information from raw novel data. By combining this structure information with the novel data, an instruction-following dataset is meticulously crafted. This dataset is then utilized to fine-tune the LLM, aiming for excelsior generation performance. In the final stage, a tree-like expansion method is deployed to facilitate the generation of arbitrarily long novels. Evaluation against previous methods showcases Ex3's ability to produce higher-quality long-form novels.
Pushing the Limits of Machine Design: Automated CPU Design with AI
Jun 27, 2023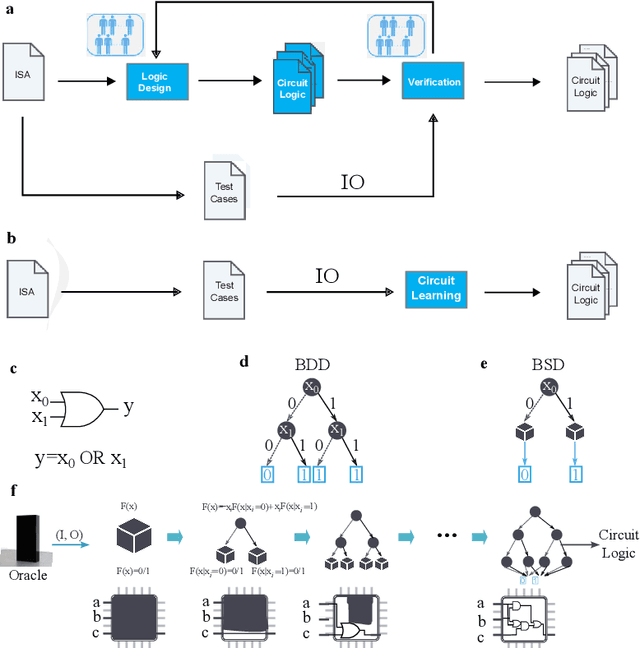
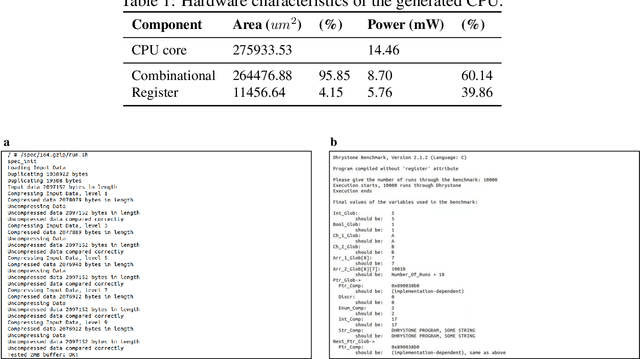
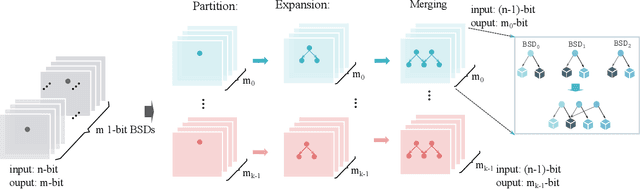

Design activity -- constructing an artifact description satisfying given goals and constraints -- distinguishes humanity from other animals and traditional machines, and endowing machines with design abilities at the human level or beyond has been a long-term pursuit. Though machines have already demonstrated their abilities in designing new materials, proteins, and computer programs with advanced artificial intelligence (AI) techniques, the search space for designing such objects is relatively small, and thus, "Can machines design like humans?" remains an open question. To explore the boundary of machine design, here we present a new AI approach to automatically design a central processing unit (CPU), the brain of a computer, and one of the world's most intricate devices humanity have ever designed. This approach generates the circuit logic, which is represented by a graph structure called Binary Speculation Diagram (BSD), of the CPU design from only external input-output observations instead of formal program code. During the generation of BSD, Monte Carlo-based expansion and the distance of Boolean functions are used to guarantee accuracy and efficiency, respectively. By efficiently exploring a search space of unprecedented size 10^{10^{540}}, which is the largest one of all machine-designed objects to our best knowledge, and thus pushing the limits of machine design, our approach generates an industrial-scale RISC-V CPU within only 5 hours. The taped-out CPU successfully runs the Linux operating system and performs comparably against the human-designed Intel 80486SX CPU. In addition to learning the world's first CPU only from input-output observations, which may reform the semiconductor industry by significantly reducing the design cycle, our approach even autonomously discovers human knowledge of the von Neumann architecture.
Real-Time Robust Video Object Detection System Against Physical-World Adversarial Attacks
Aug 19, 2022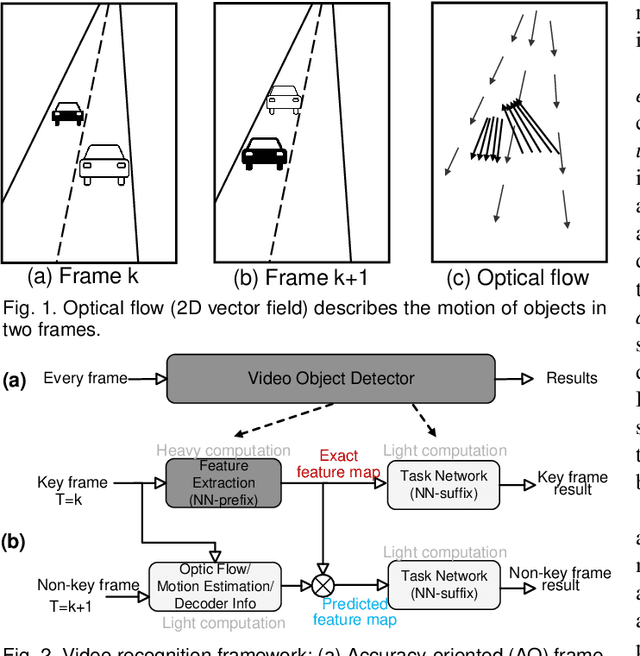

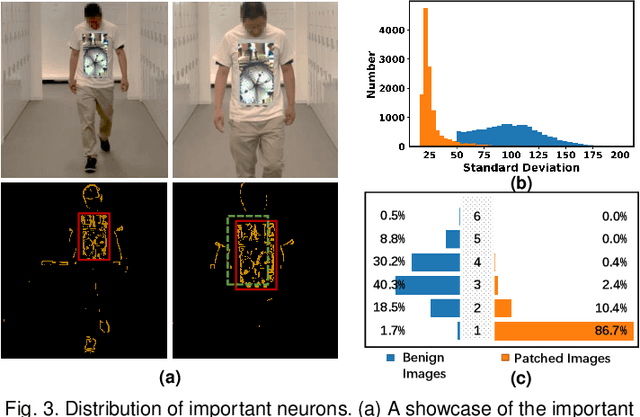
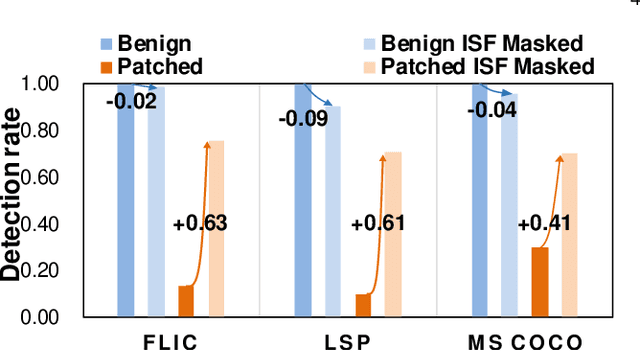
DNN-based video object detection (VOD) powers autonomous driving and video surveillance industries with rising importance and promising opportunities. However, adversarial patch attack yields huge concern in live vision tasks because of its practicality, feasibility, and powerful attack effectiveness. This work proposes Themis, a software/hardware system to defend against adversarial patches for real-time robust video object detection. We observe that adversarial patches exhibit extremely localized superficial feature importance in a small region with non-robust predictions, and thus propose the adversarial region detection algorithm for adversarial effect elimination. Themis also proposes a systematic design to efficiently support the algorithm by eliminating redundant computations and memory traffics. Experimental results show that the proposed methodology can effectively recover the system from the adversarial attack with negligible hardware overhead.
Distilling Object Detectors with Feature Richness
Nov 02, 2021
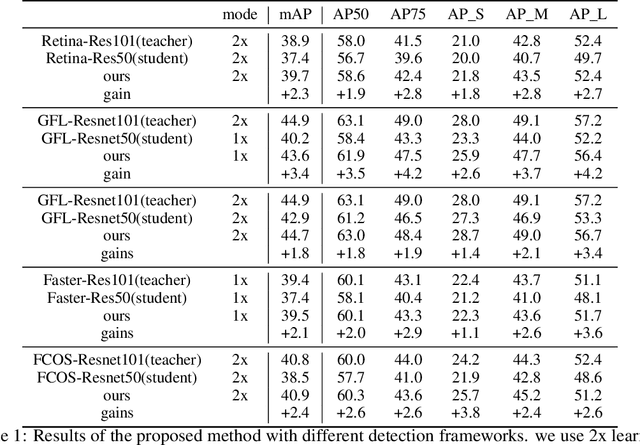

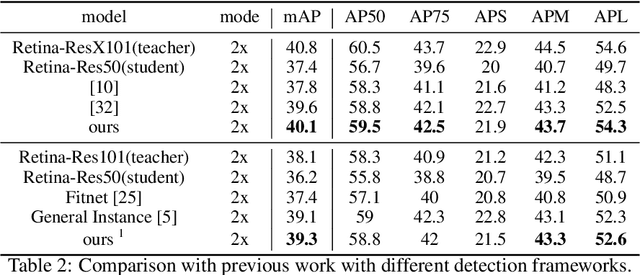
In recent years, large-scale deep models have achieved great success, but the huge computational complexity and massive storage requirements make it a great challenge to deploy them in resource-limited devices. As a model compression and acceleration method, knowledge distillation effectively improves the performance of small models by transferring the dark knowledge from the teacher detector. However, most of the existing distillation-based detection methods mainly imitating features near bounding boxes, which suffer from two limitations. First, they ignore the beneficial features outside the bounding boxes. Second, these methods imitate some features which are mistakenly regarded as the background by the teacher detector. To address the above issues, we propose a novel Feature-Richness Score (FRS) method to choose important features that improve generalized detectability during distilling. The proposed method effectively retrieves the important features outside the bounding boxes and removes the detrimental features within the bounding boxes. Extensive experiments show that our methods achieve excellent performance on both anchor-based and anchor-free detectors. For example, RetinaNet with ResNet-50 achieves 39.7% in mAP on the COCO2017 dataset, which even surpasses the ResNet-101 based teacher detector 38.9% by 0.8%.
Accelerated Sparse Bayesian Learning via Screening Test and Its Applications
Jul 08, 2020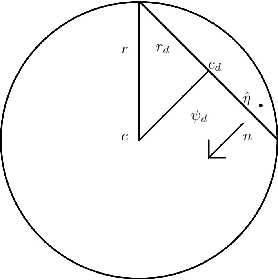
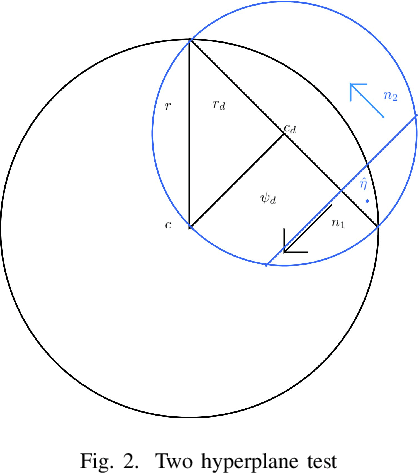
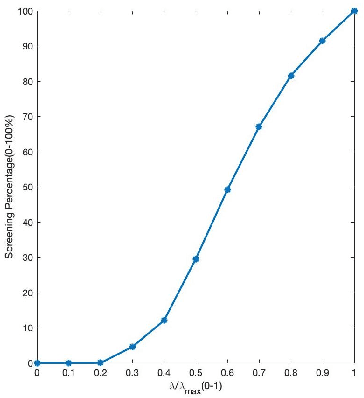
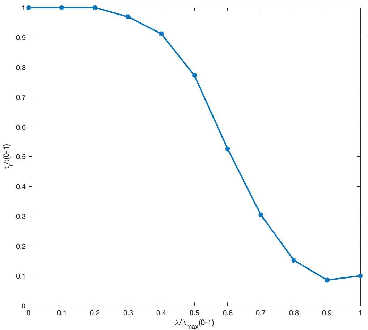
In high-dimensional settings, sparse structures are critical for efficiency in term of memory and computation complexity. For a linear system, to find the sparsest solution provided with an over-complete dictionary of features directly is typically NP-hard, and thus alternative approximate methods should be considered. In this paper, our choice for alternative method is sparse Bayesian learning, which, as empirical Bayesian approaches, uses a parameterized prior to encourage sparsity in solution, rather than the other methods with fixed priors such as LASSO. Screening test, however, aims at quickly identifying a subset of features whose coefficients are guaranteed to be zero in the optimal solution, and then can be safely removed from the complete dictionary to obtain a smaller, more easily solved problem. Next, we solve the smaller problem, after which the solution of the original problem can be recovered by padding the smaller solution with zeros. The performance of the proposed method will be examined on various data sets and applications.
DWM: A Decomposable Winograd Method for Convolution Acceleration
Feb 03, 2020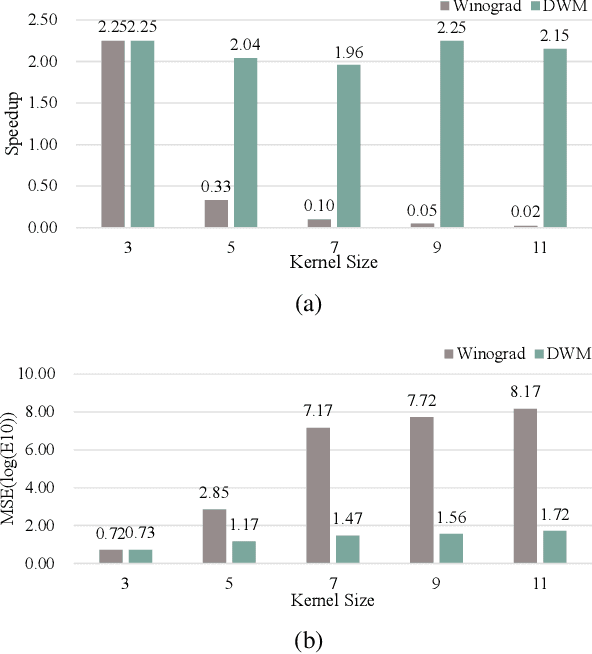
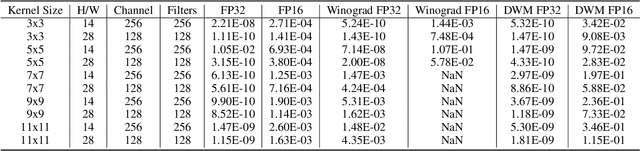
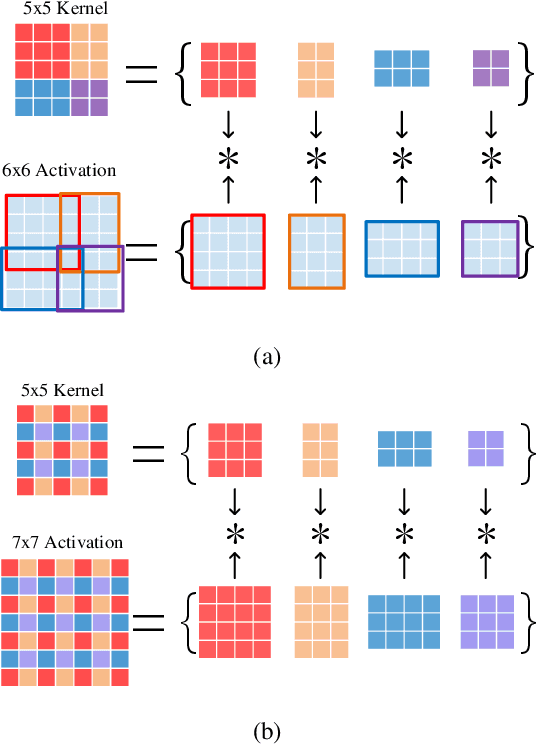

Winograd's minimal filtering algorithm has been widely used in Convolutional Neural Networks (CNNs) to reduce the number of multiplications for faster processing. However, it is only effective on convolutions with kernel size as 3x3 and stride as 1, because it suffers from significantly increased FLOPs and numerical accuracy problem for kernel size larger than 3x3 and fails on convolution with stride larger than 1. In this paper, we propose a novel Decomposable Winograd Method (DWM), which breaks through the limitation of original Winograd's minimal filtering algorithm to a wide and general convolutions. DWM decomposes kernels with large size or large stride to several small kernels with stride as 1 for further applying Winograd method, so that DWM can reduce the number of multiplications while keeping the numerical accuracy. It enables the fast exploring of larger kernel size and larger stride value in CNNs for high performance and accuracy and even the potential for new CNNs. Comparing against the original Winograd, the proposed DWM is able to support all kinds of convolutions with a speedup of ~2, without affecting the numerical accuracy.
Linear Multiple Low-Rank Kernel Based Stationary Gaussian Processes Regression for Time Series
Apr 21, 2019
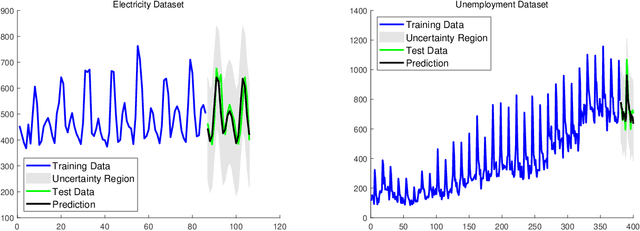
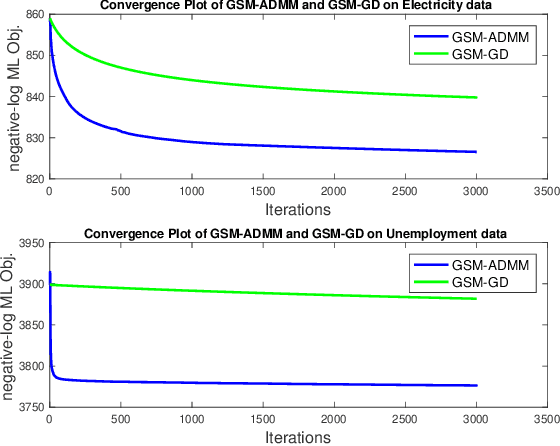
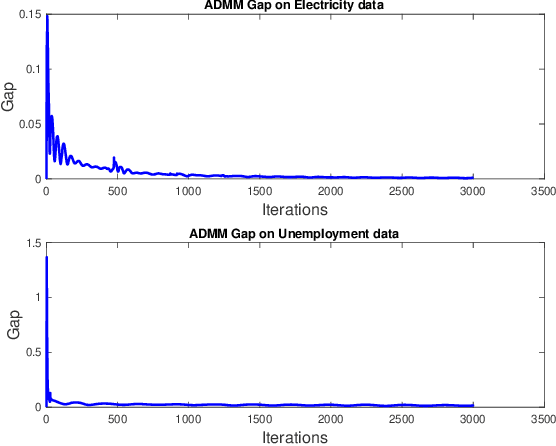
Gaussian processes (GP) for machine learning have been studied systematically over the past two decades and they are by now widely used in a number of diverse applications. However, GP kernel design and the associated hyper-parameter optimization are still hard and to a large extend open problems. In this paper, we consider the task of GP regression for time series modeling and analysis. The underlying stationary kernel can be approximated arbitrarily close by a new proposed grid spectral mixture (GSM) kernel, which turns out to be a linear combination of low-rank sub-kernels. In the case where a large number of the sub-kernels are used, either the Nystr\"{o}m or the random Fourier feature approximations can be adopted to deal efficiently with the computational demands. The unknown GP hyper-parameters consist of the non-negative weights of all sub-kernels as well as the noise variance; their estimation is performed via the maximum-likelihood (ML) estimation framework. Two efficient numerical optimization methods for solving the unknown hyper-parameters are derived, including a sequential majorization-minimization (MM) method and a non-linearly constrained alternating direction of multiplier method (ADMM). The MM matches perfectly with the proven low-rank property of the proposed GSM sub-kernels and turns out to be a part of efficiency, stable, and efficient solver, while the ADMM has the potential to generate better local minimum in terms of the test MSE. Experimental results, based on various classic time series data sets, corroborate that the proposed GSM kernel-based GP regression model outperforms several salient competitors of similar kind in terms of prediction mean-squared-error and numerical stability.
BENCHIP: Benchmarking Intelligence Processors
Nov 25, 2017
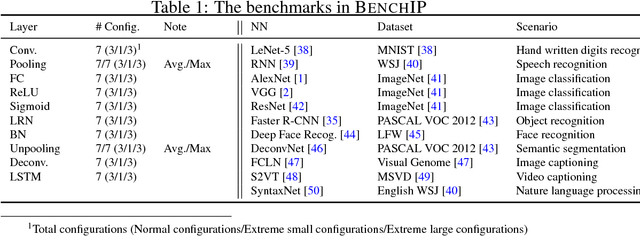
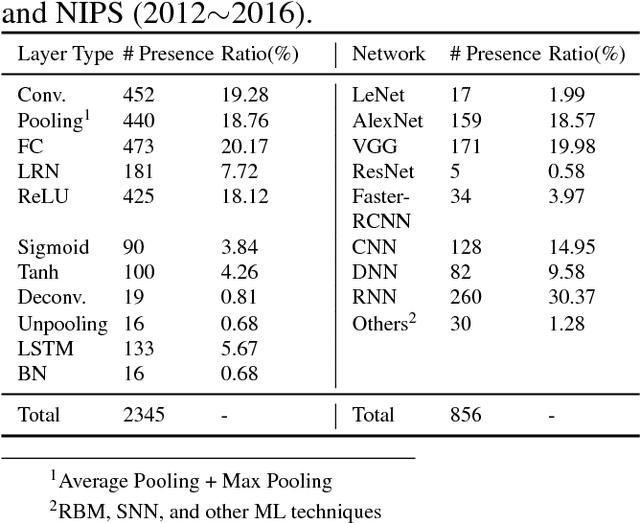
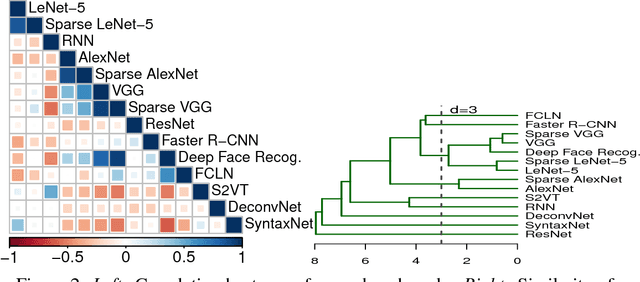
The increasing attention on deep learning has tremendously spurred the design of intelligence processing hardware. The variety of emerging intelligence processors requires standard benchmarks for fair comparison and system optimization (in both software and hardware). However, existing benchmarks are unsuitable for benchmarking intelligence processors due to their non-diversity and nonrepresentativeness. Also, the lack of a standard benchmarking methodology further exacerbates this problem. In this paper, we propose BENCHIP, a benchmark suite and benchmarking methodology for intelligence processors. The benchmark suite in BENCHIP consists of two sets of benchmarks: microbenchmarks and macrobenchmarks. The microbenchmarks consist of single-layer networks. They are mainly designed for bottleneck analysis and system optimization. The macrobenchmarks contain state-of-the-art industrial networks, so as to offer a realistic comparison of different platforms. We also propose a standard benchmarking methodology built upon an industrial software stack and evaluation metrics that comprehensively reflect the various characteristics of the evaluated intelligence processors. BENCHIP is utilized for evaluating various hardware platforms, including CPUs, GPUs, and accelerators. BENCHIP will be open-sourced soon.
Maximum Entropy Kernels for System Identification
Jan 15, 2016A new nonparametric approach for system identification has been recently proposed where the impulse response is modeled as the realization of a zero-mean Gaussian process whose covariance (kernel) has to be estimated from data. In this scheme, quality of the estimates crucially depends on the parametrization of the covariance of the Gaussian process. A family of kernels that have been shown to be particularly effective in the system identification framework is the family of Diagonal/Correlated (DC) kernels. Maximum entropy properties of a related family of kernels, the Tuned/Correlated (TC) kernels, have been recently pointed out in the literature. In this paper we show that maximum entropy properties indeed extend to the whole family of DC kernels. The maximum entropy interpretation can be exploited in conjunction with results on matrix completion problems in the graphical models literature to shed light on the structure of the DC kernel. In particular, we prove that the DC kernel admits a closed-form factorization, inverse and determinant. These results can be exploited both to improve the numerical stability and to reduce the computational complexity associated with the computation of the DC estimator.