 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-LINS: a Multi-Map LiDAR-Inertial System for Over-Degenerate Environments
Mar 25, 2025SLAM plays a crucial role in automation tasks, such as warehouse logistics, healthcare robotics, and restaurant delivery. These scenes come with various challenges, including navigating around crowds of people, dealing with flying plastic bags that can temporarily blind sensors, and addressing reduced LiDAR density caused by cooking smoke. Such scenarios can result in over-degeneracy, causing the map to drift. To address this issue, this paper presents a multi-map LiDAR-inertial system (MM-LINS) for the first time. The front-end employs an iterated error state Kalman filter for state estimation and introduces a reliable evaluation strategy for degeneracy detection. If over-degeneracy is detected, the active map will be stored into sleeping maps. Subsequently, the system continuously attempts to construct new maps using a dynamic initialization method to ensure successful initialization upon leaving the over-degeneracy. Regarding the back-end, the Scan Context descriptor is utilized to detect inter-map similarity. Upon successful recognition of a sleeping map that shares a common region with the active map, the overlapping trajectory region is utilized to constrain the positional transformation near the edge of the prior map. In response to this, a constraint-enhanced map fusion strategy is proposed to achieve high-precision positional and mapping results. Experiments have been conducted separately on both public datasets that exhibited over-degenerate conditions and in real-world environments. These tests demonstrated the effectiveness of MM-LINS in over-degeneracy environment. Our codes are open-sourced on Github.
DWM: A Decomposable Winograd Method for Convolution Acceleration
Feb 03, 2020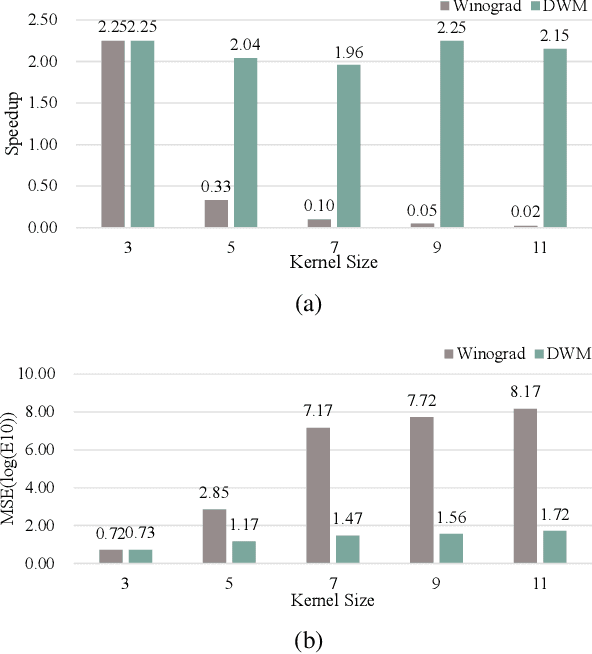
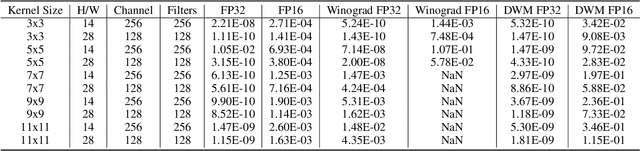
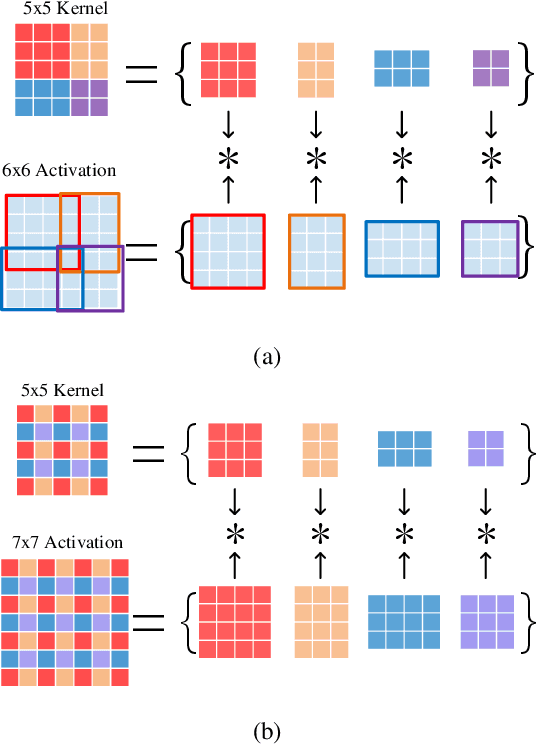

Winograd's minimal filtering algorithm has been widely used in Convolutional Neural Networks (CNNs) to reduce the number of multiplications for faster processing. However, it is only effective on convolutions with kernel size as 3x3 and stride as 1, because it suffers from significantly increased FLOPs and numerical accuracy problem for kernel size larger than 3x3 and fails on convolution with stride larger than 1. In this paper, we propose a novel Decomposable Winograd Method (DWM), which breaks through the limitation of original Winograd's minimal filtering algorithm to a wide and general convolutions. DWM decomposes kernels with large size or large stride to several small kernels with stride as 1 for further applying Winograd method, so that DWM can reduce the number of multiplications while keeping the numerical accuracy. It enables the fast exploring of larger kernel size and larger stride value in CNNs for high performance and accuracy and even the potential for new CNNs. Comparing against the original Winograd, the proposed DWM is able to support all kinds of convolutions with a speedup of ~2, without affecting the numerical accuracy.
COKE: Communication-Censored Kernel Learning for Decentralized Non-parametric Learning
Jan 28, 2020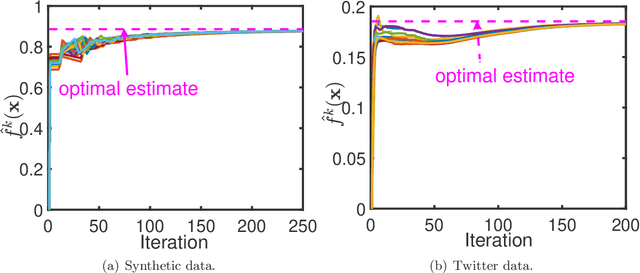
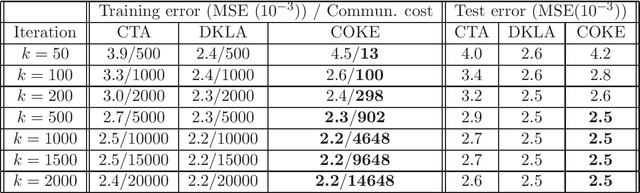
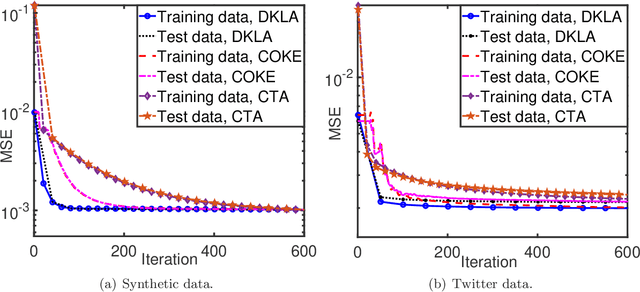
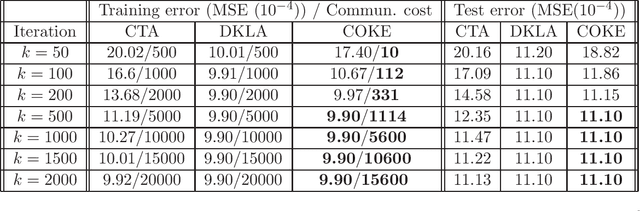
This paper studies the decentralized optimization and learning problem where multiple interconnected agents aim to learn an optimal decision function defined over a reproducing kernel Hilbert (RKH) space by jointly minimizing a global objective function, with access to locally observed data only. As a non-parametric approach, kernel learning faces a major challenge in distributed implementation: the decision variables of local objective functions are data-dependent with different sizes and thus cannot be optimized under the decentralized consensus framework without any raw data exchange among agents. To circumvent this major challenge and preserve data privacy, we leverage the random feature (RF) approximation approach to map the large-volume data represented in the RKH space into a smaller RF space, which facilitates the same-size parameter exchange and enables distributed agents to reach consensus on the function decided by the parameters in the RF space. For fast convergent implementation, we design an iterative algorithm for Decentralized Kernel Learning via Alternating direction method of multipliers (DKLA). Further, we develop a COmmunication-censored KErnel learning (COKE) algorithm to reduce the communication load in DKLA. To do so, we apply a communication-censoring strategy, which prevents an agent from transmitting at every iteration unless its local updates are deemed informative. Theoretical results in terms of linear convergence guarantee and generalization performance analysis of DKLA and COKE are provided. Comprehensive tests with both synthetic and real datasets are conducted to verify the communication efficiency and learning effectiveness of COKE.