 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMigGPT: Harnessing Large Language Models for Automated Migration of Out-of-Tree Linux Kernel Patches Across Versions
Apr 13, 2025Out-of-tree kernel patches are essential for adapting the Linux kernel to new hardware or enabling specific functionalities. Maintaining and updating these patches across different kernel versions demands significant effort from experienced engineers. Large language models (LLMs) have shown remarkable progress across various domains, suggesting their potential for automating out-of-tree kernel patch migration. However, our findings reveal that LLMs, while promising, struggle with incomplete code context understanding and inaccurate migration point identification. In this work, we propose MigGPT, a framework that employs a novel code fingerprint structure to retain code snippet information and incorporates three meticulously designed modules to improve the migration accuracy and efficiency of out-of-tree kernel patches. Furthermore, we establish a robust benchmark using real-world out-of-tree kernel patch projects to evaluate LLM capabilities. Evaluations show that MigGPT significantly outperforms the direct application of vanilla LLMs, achieving an average completion rate of 72.59% (50.74% improvement) for migration tasks.
DiffZOO: A Purely Query-Based Black-Box Attack for Red-teaming Text-to-Image Generative Model via Zeroth Order Optimization
Aug 18, 2024



Current text-to-image (T2I) synthesis diffusion models raise misuse concerns, particularly in creating prohibited or not-safe-for-work (NSFW) images. To address this, various safety mechanisms and red teaming attack methods are proposed to enhance or expose the T2I model's capability to generate unsuitable content. However, many red teaming attack methods assume knowledge of the text encoders, limiting their practical usage. In this work, we rethink the case of \textit{purely black-box} attacks without prior knowledge of the T2l model. To overcome the unavailability of gradients and the inability to optimize attacks within a discrete prompt space, we propose DiffZOO which applies Zeroth Order Optimization to procure gradient approximations and harnesses both C-PRV and D-PRV to enhance attack prompts within the discrete prompt domain. We evaluated our method across multiple safety mechanisms of the T2I diffusion model and online servers. Experiments on multiple state-of-the-art safety mechanisms show that DiffZOO attains an 8.5% higher average attack success rate than previous works, hence its promise as a practical red teaming tool for T2l models.
Flew Over Learning Trap: Learn Unlearnable Samples by Progressive Staged Training
Jun 03, 2023



Unlearning techniques are proposed to prevent third parties from exploiting unauthorized data, which generate unlearnable samples by adding imperceptible perturbations to data for public publishing. These unlearnable samples effectively misguide model training to learn perturbation features but ignore image semantic features. We make the in-depth analysis and observe that models can learn both image features and perturbation features of unlearnable samples at an early stage, but rapidly go to the overfitting stage since the shallow layers tend to overfit on perturbation features and make models fall into overfitting quickly. Based on the observations, we propose Progressive Staged Training to effectively prevent models from overfitting in learning perturbation features. We evaluated our method on multiple model architectures over diverse datasets, e.g., CIFAR-10, CIFAR-100, and ImageNet-mini. Our method circumvents the unlearnability of all state-of-the-art methods in the literature and provides a reliable baseline for further evaluation of unlearnable techniques.
Real-Time Robust Video Object Detection System Against Physical-World Adversarial Attacks
Aug 19, 2022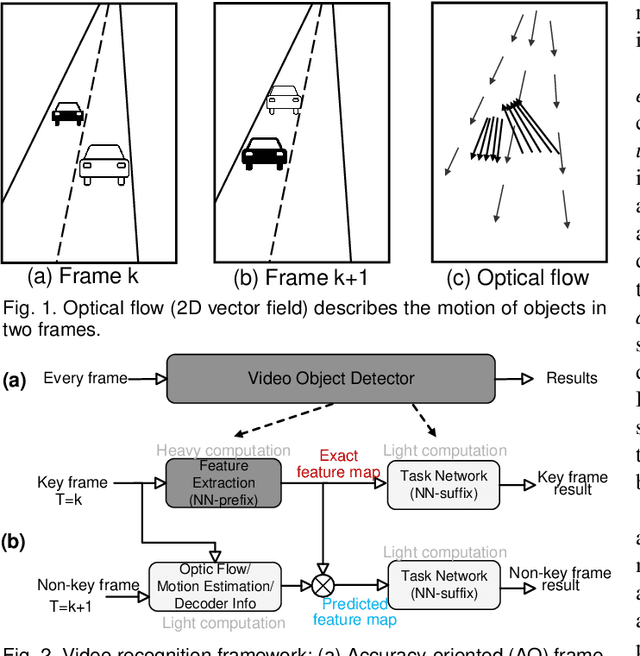

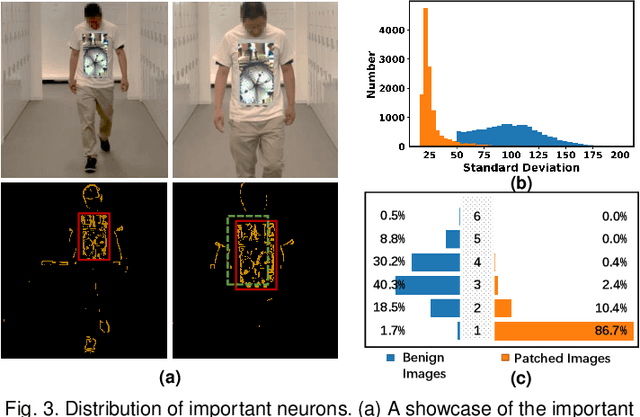
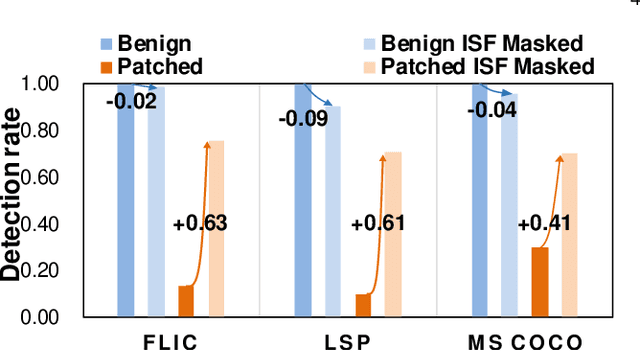
DNN-based video object detection (VOD) powers autonomous driving and video surveillance industries with rising importance and promising opportunities. However, adversarial patch attack yields huge concern in live vision tasks because of its practicality, feasibility, and powerful attack effectiveness. This work proposes Themis, a software/hardware system to defend against adversarial patches for real-time robust video object detection. We observe that adversarial patches exhibit extremely localized superficial feature importance in a small region with non-robust predictions, and thus propose the adversarial region detection algorithm for adversarial effect elimination. Themis also proposes a systematic design to efficiently support the algorithm by eliminating redundant computations and memory traffics. Experimental results show that the proposed methodology can effectively recover the system from the adversarial attack with negligible hardware overhead.