 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiMeng-Xpiler: Transcompiling Tensor Programs for Deep Learning Systems with a Neural-Symbolic Approach
May 04, 2025Heterogeneous deep learning systems (DLS) such as GPUs and ASICs have been widely deployed in industrial data centers, which requires to develop multiple low-level tensor programs for different platforms. An attractive solution to relieve the programming burden is to transcompile the legacy code of one platform to others. However, current transcompilation techniques struggle with either tremendous manual efforts or functional incorrectness, rendering "Write Once, Run Anywhere" of tensor programs an open question. We propose a novel transcompiler, i.e., QiMeng-Xpiler, for automatically translating tensor programs across DLS via both large language models (LLMs) and symbolic program synthesis, i.e., neural-symbolic synthesis. The key insight is leveraging the powerful code generation ability of LLM to make costly search-based symbolic synthesis computationally tractable. Concretely, we propose multiple LLM-assisted compilation passes via pre-defined meta-prompts for program transformation. During each program transformation, efficient symbolic program synthesis is employed to repair incorrect code snippets with a limited scale. To attain high performance, we propose a hierarchical auto-tuning approach to systematically explore both the parameters and sequences of transformation passes. Experiments on 4 DLS with distinct programming interfaces, i.e., Intel DL Boost with VNNI, NVIDIA GPU with CUDA, AMD MI with HIP, and Cambricon MLU with BANG, demonstrate that QiMeng-Xpiler correctly translates different tensor programs at the accuracy of 95% on average, and the performance of translated programs achieves up to 2.0x over vendor-provided manually-optimized libraries. As a result, the programming productivity of DLS is improved by up to 96.0x via transcompiling legacy tensor programs.
Temporal Self-Ensembling Teacher for Semi-Supervised Object Detection
Jul 14, 2020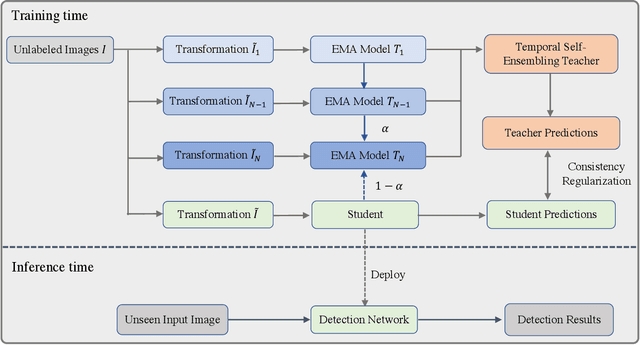
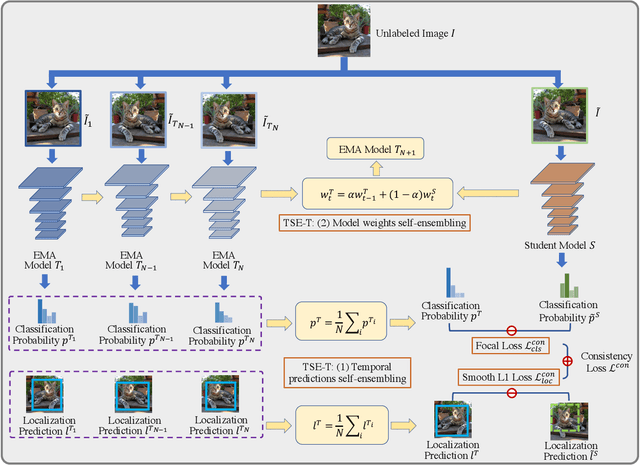

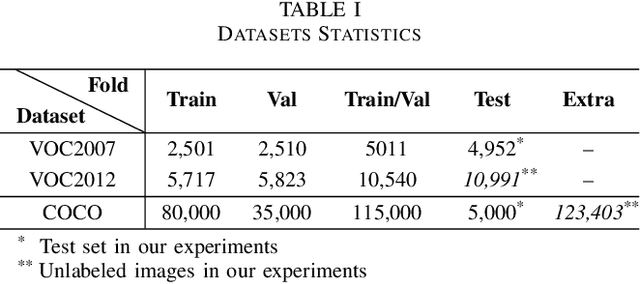
This paper focuses on the problem of Semi-Supervised Object Detection (SSOD). In the field of Semi-Supervised Learning (SSL), the Knowledge Distillation (KD) framework which consists of a teacher model and a student model is widely used to make good use of the unlabeled images. Given unlabeled images, the teacher is supposed to yield meaningful targets (e.g. well-posed logits) to regularize the training of the student. However, directly applying the KD framework in SSOD has the following obstacles. (1) Teacher and student predictions may be very close which limits the upper-bound of the student, and (2) the data imbalance dilemma caused by dense prediction from object detection hinders an efficient consistency regularization between the teacher and student. To solve these problems, we propose the Temporal Self-Ensembling Teacher (TSE-T) model on top of the KD framework. Differently from the conventional KD methods, we devise a temporally updated teacher model. First, our teacher model ensembles its temporal predictions for unlabeled images under varying perturbations. Second, our teacher model ensembles its temporal model weights by Exponential Moving Average (EMA) which allows it gradually learn from student. The above self-ensembling strategies collaboratively yield better teacher predictions for unblabeled images. Finally, we use focal loss to formulate the consistency regularization to handle the data imbalance problem. Evaluated on the widely used VOC and COCO benchmarks, our method has achieved 80.73% and 40.52% (mAP) on the VOC2007 test set and the COCO2012 test-dev set respectively, which outperforms the fully-supervised detector by 2.37% and 1.49%. Furthermore, our method sets the new state state of the art in SSOD on VOC benchmark which outperforms the baseline SSOD method by 1.44%. The source code of this work is publicly available at http://github.com/SYangDong/tse-t.