 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Self-Ensembling Teacher for Semi-Supervised Object Detection
Jul 14, 2020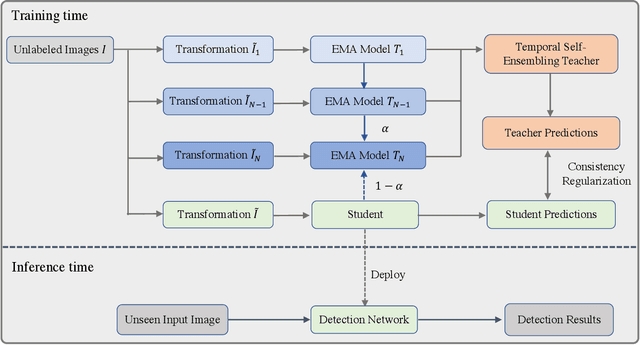
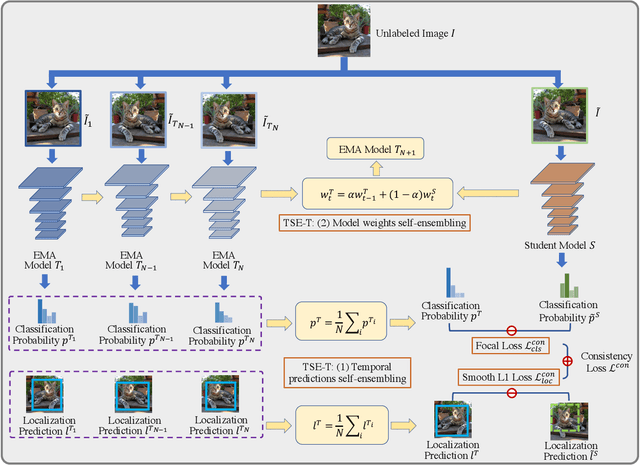

This paper focuses on the problem of Semi-Supervised Object Detection (SSOD). In the field of Semi-Supervised Learning (SSL), the Knowledge Distillation (KD) framework which consists of a teacher model and a student model is widely used to make good use of the unlabeled images. Given unlabeled images, the teacher is supposed to yield meaningful targets (e.g. well-posed logits) to regularize the training of the student. However, directly applying the KD framework in SSOD has the following obstacles. (1) Teacher and student predictions may be very close which limits the upper-bound of the student, and (2) the data imbalance dilemma caused by dense prediction from object detection hinders an efficient consistency regularization between the teacher and student. To solve these problems, we propose the Temporal Self-Ensembling Teacher (TSE-T) model on top of the KD framework. Differently from the conventional KD methods, we devise a temporally updated teacher model. First, our teacher model ensembles its temporal predictions for unlabeled images under varying perturbations. Second, our teacher model ensembles its temporal model weights by Exponential Moving Average (EMA) which allows it gradually learn from student. The above self-ensembling strategies collaboratively yield better teacher predictions for unblabeled images. Finally, we use focal loss to formulate the consistency regularization to handle the data imbalance problem. Evaluated on the widely used VOC and COCO benchmarks, our method has achieved 80.73% and 40.52% (mAP) on the VOC2007 test set and the COCO2012 test-dev set respectively, which outperforms the fully-supervised detector by 2.37% and 1.49%. Furthermore, our method sets the new state state of the art in SSOD on VOC benchmark which outperforms the baseline SSOD method by 1.44%. The source code of this work is publicly available at http://github.com/SYangDong/tse-t.
DeepCenterline: a Multi-task Fully Convolutional Network for Centerline Extraction
Mar 25, 2019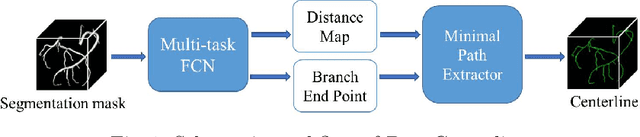

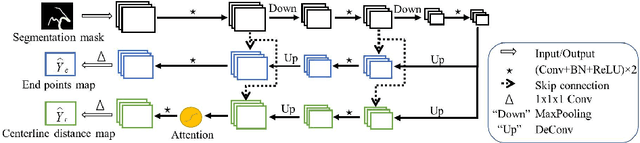
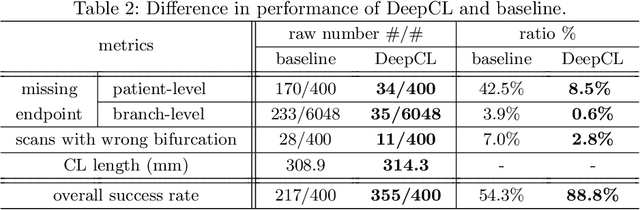
A novel centerline extraction framework is reported which combines an end-to-end trainable multi-task fully convolutional network (FCN) with a minimal path extractor. The FCN simultaneously computes centerline distance maps and detects branch endpoints. The method generates single-pixel-wide centerlines with no spurious branches. It handles arbitrary tree-structured object with no prior assumption regarding depth of the tree or its bifurcation pattern. It is also robust to substantial scale changes across different parts of the target object and minor imperfections of the object's segmentation mask. To the best of our knowledge, this is the first deep-learning based centerline extraction method that guarantees single-pixel-wide centerline for a complex tree-structured object. The proposed method is validated in coronary artery centerline extraction on a dataset of 620 patients (400 of which used as test set). This application is challenging due to the large number of coronary branches, branch tortuosity, and large variations in length, thickness, shape, etc. The proposed method generates well-positioned centerlines, exhibiting lower number of missing branches and is more robust in the presence of minor imperfections of the object segmentation mask. Compared to a state-of-the-art traditional minimal path approach, our method improves patient-level success rate of centerline extraction from 54.3% to 88.8% according to independent human expert review.
Residual Attention based Network for Hand Bone Age Assessment
Dec 21, 2018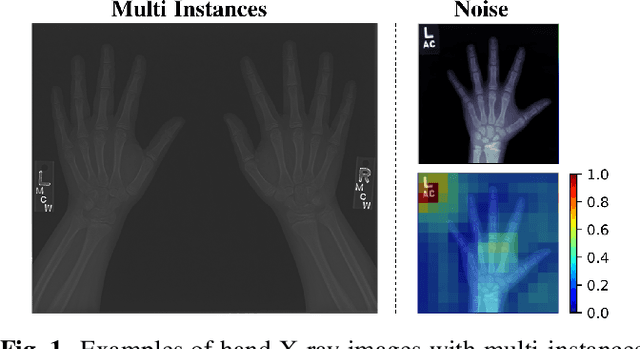

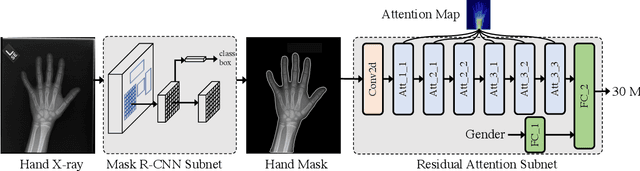

Computerized automatic methods have been employed to boost the productivity as well as objectiveness of hand bone age assessment. These approaches make predictions according to the whole X-ray images, which include other objects that may introduce distractions. Instead, our framework is inspired by the clinical workflow (Tanner-Whitehouse) of hand bone age assessment, which focuses on the key components of the hand. The proposed framework is composed of two components: a Mask R-CNN subnet of pixelwise hand segmentation and a residual attention network for hand bone age assessment. The Mask R-CNN subnet segments the hands from X-ray images to avoid the distractions of other objects (e.g., X-ray tags). The hierarchical attention components of the residual attention subnet force our network to focus on the key components of the X-ray images and generate the final predictions as well as the associated visual supports, which is similar to the assessment procedure of clinicians. We evaluate the performance of the proposed pipeline on the RSNA pediatric bone age dataset and the results demonstrate its superiority over the previous methods.
Risk Stratification of Lung Nodules Using 3D CNN-Based Multi-task Learning
Apr 28, 2017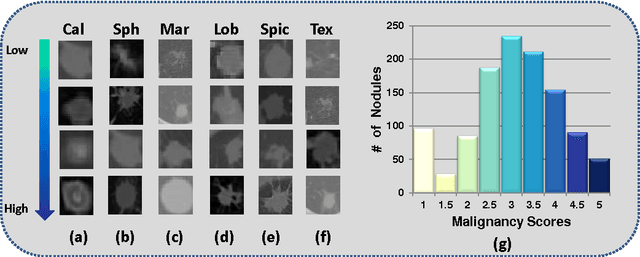

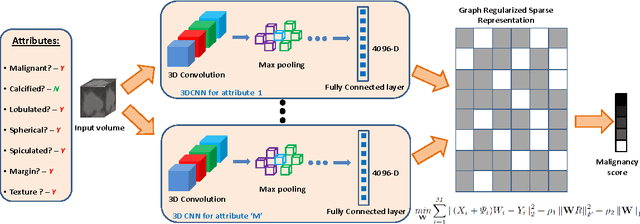
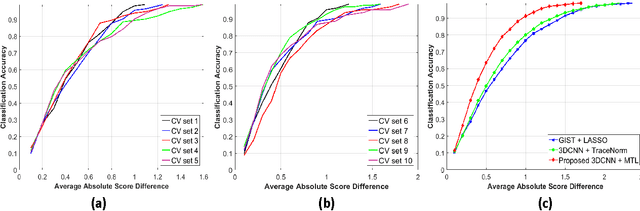
Risk stratification of lung nodules is a task of primary importance in lung cancer diagnosis. Any improvement in robust and accurate nodule characterization can assist in identifying cancer stage, prognosis, and improving treatment planning. In this study, we propose a 3D Convolutional Neural Network (CNN) based nodule characterization strategy. With a completely 3D approach, we utilize the volumetric information from a CT scan which would be otherwise lost in the conventional 2D CNN based approaches. In order to address the need for a large amount for training data for CNN, we resort to transfer learning to obtain highly discriminative features. Moreover, we also acquire the task dependent feature representation for six high-level nodule attributes and fuse this complementary information via a Multi-task learning (MTL) framework. Finally, we propose to incorporate potential disagreement among radiologists while scoring different nodule attributes in a graph regularized sparse multi-task learning. We evaluated our proposed approach on one of the largest publicly available lung nodule datasets comprising 1018 scans and obtained state-of-the-art results in regressing the malignancy scores.
* Accepted for publication at Information Processing in Medical Imaging (IPMI) 2017
TumorNet: Lung Nodule Characterization Using Multi-View Convolutional Neural Network with Gaussian Process
Mar 02, 2017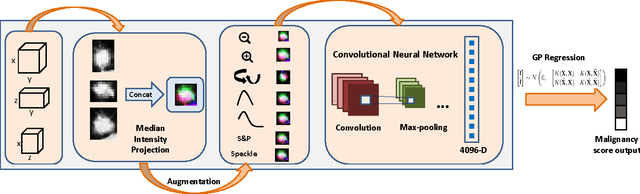



Characterization of lung nodules as benign or malignant is one of the most important tasks in lung cancer diagnosis, staging and treatment planning. While the variation in the appearance of the nodules remains large, there is a need for a fast and robust computer aided system. In this work, we propose an end-to-end trainable multi-view deep Convolutional Neural Network (CNN) for nodule characterization. First, we use median intensity projection to obtain a 2D patch corresponding to each dimension. The three images are then concatenated to form a tensor, where the images serve as different channels of the input image. In order to increase the number of training samples, we perform data augmentation by scaling, rotating and adding noise to the input image. The trained network is used to extract features from the input image followed by a Gaussian Process (GP) regression to obtain the malignancy score. We also empirically establish the significance of different high level nodule attributes such as calcification, sphericity and others for malignancy determination. These attributes are found to be complementary to the deep multi-view CNN features and a significant improvement over other methods is obtained.