 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
Apr 08, 2026Reinforcement-Learning-based post-training has recently emerged as a promising paradigm for aligning text-to-image diffusion models with human preferences. In recent studies, increasing the rollout group size yields pronounced performance improvements, indicating substantial room for further alignment gains. However, scaling rollouts on large-scale foundational diffusion models (e.g., FLUX.1-12B) imposes a heavy computational burden. To alleviate this bottleneck, we explore the integration of FP4 quantization into Diffusion RL rollouts. Yet, we identify that naive quantized pipelines inherently introduce risks of performance degradation. To overcome this dilemma between efficiency and training integrity, we propose Sol-RL (Speed-of-light RL), a novel FP4-empowered Two-stage Reinforcement Learning framework. First, we utilize high-throughput NVFP4 rollouts to generate a massive candidate pool and extract a highly contrastive subset. Second, we regenerate these selected samples in BF16 precision and optimize the policy exclusively on them. By decoupling candidate exploration from policy optimization, Sol-RL integrates the algorithmic mechanisms of rollout scaling with the system-level throughput gains of NVFP4. This synergistic algorithm-hardware design effectively accelerates the rollout phase while reserving high-fidelity samples for optimization. We empirically demonstrate that our framework maintains the training integrity of BF16 precision pipeline while fully exploiting the throughput gains enabled by FP4 arithmetic. Extensive experiments across SANA, FLUX.1, and SD3.5-L substantiate that our approach delivers superior alignment performance across multiple metrics while accelerating training convergence by up to $4.64\times$, unlocking the power of massive rollout scaling at a fraction of the cost.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Mar 07, 2024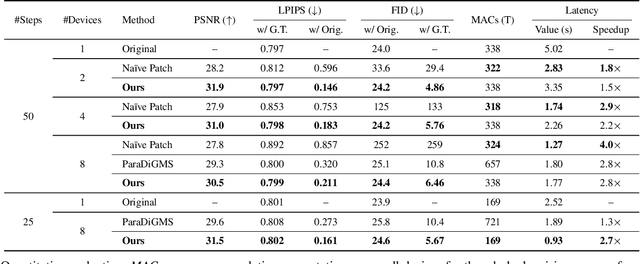
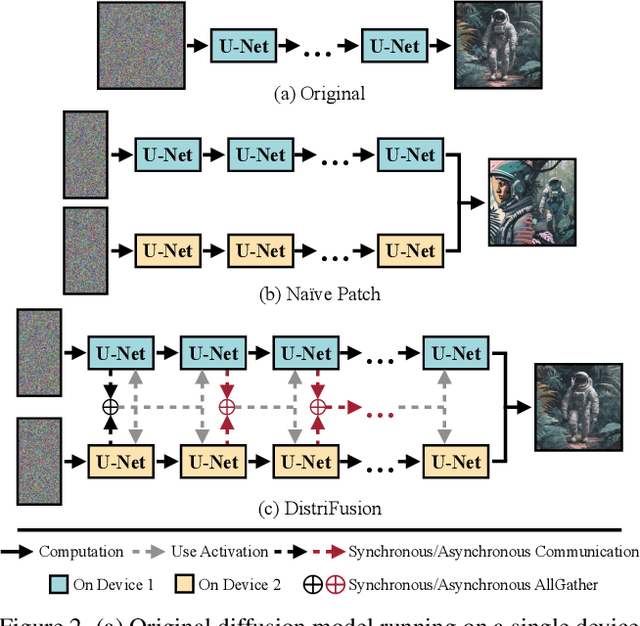
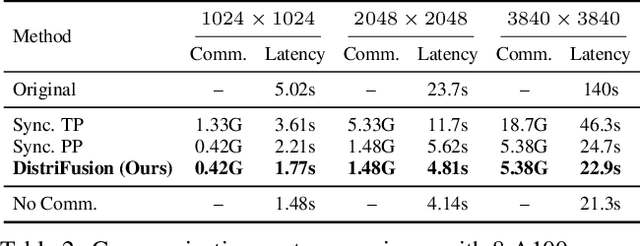
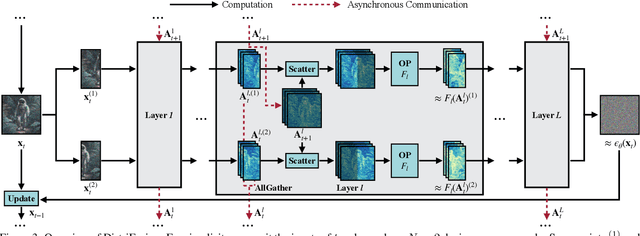
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
OmniMotionGPT: Animal Motion Generation with Limited Data
Nov 30, 2023



Our paper aims to generate diverse and realistic animal motion sequences from textual descriptions, without a large-scale animal text-motion dataset. While the task of text-driven human motion synthesis is already extensively studied and benchmarked, it remains challenging to transfer this success to other skeleton structures with limited data. In this work, we design a model architecture that imitates Generative Pretraining Transformer (GPT), utilizing prior knowledge learned from human data to the animal domain. We jointly train motion autoencoders for both animal and human motions and at the same time optimize through the similarity scores among human motion encoding, animal motion encoding, and text CLIP embedding. Presenting the first solution to this problem, we are able to generate animal motions with high diversity and fidelity, quantitatively and qualitatively outperforming the results of training human motion generation baselines on animal data. Additionally, we introduce AnimalML3D, the first text-animal motion dataset with 1240 animation sequences spanning 36 different animal identities. We hope this dataset would mediate the data scarcity problem in text-driven animal motion generation, providing a new playground for the research community.
Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
May 23, 2022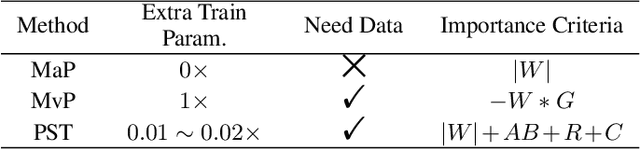
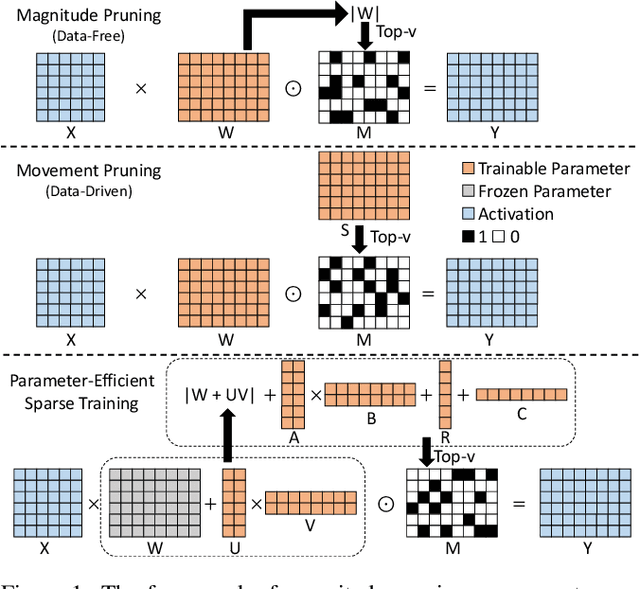
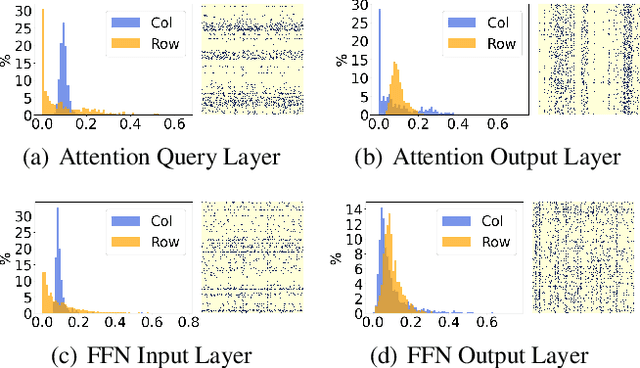
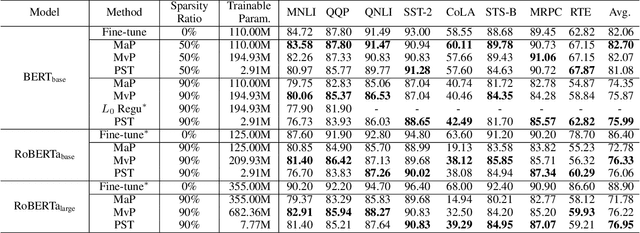
With the dramatically increased number of parameters in language models, sparsity methods have received ever-increasing research focus to compress and accelerate the models. While most research focuses on how to accurately retain appropriate weights while maintaining the performance of the compressed model, there are challenges in the computational overhead and memory footprint of sparse training when compressing large-scale language models. To address this problem, we propose a Parameter-efficient Sparse Training (PST) method to reduce the number of trainable parameters during sparse-aware training in downstream tasks. Specifically, we first combine the data-free and data-driven criteria to efficiently and accurately measure the importance of weights. Then we investigate the intrinsic redundancy of data-driven weight importance and derive two obvious characteristics i.e., low-rankness and structuredness. Based on that, two groups of small matrices are introduced to compute the data-driven importance of weights, instead of using the original large importance score matrix, which therefore makes the sparse training resource-efficient and parameter-efficient. Experiments with diverse networks (i.e., BERT, RoBERTa and GPT-2) on dozens of datasets demonstrate PST performs on par or better than previous sparsity methods, despite only training a small number of parameters. For instance, compared with previous sparsity methods, our PST only requires 1.5% trainable parameters to achieve comparable performance on BERT.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019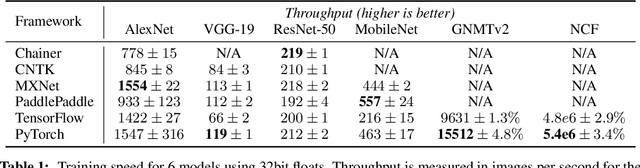

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
DeepCenterline: a Multi-task Fully Convolutional Network for Centerline Extraction
Mar 25, 2019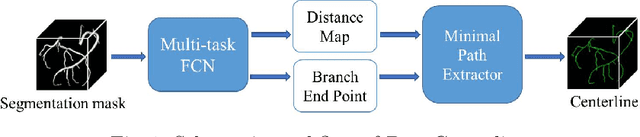

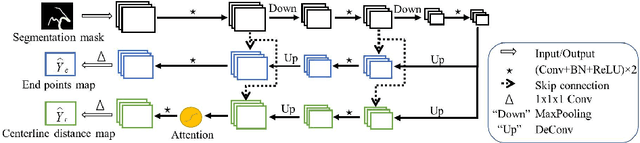
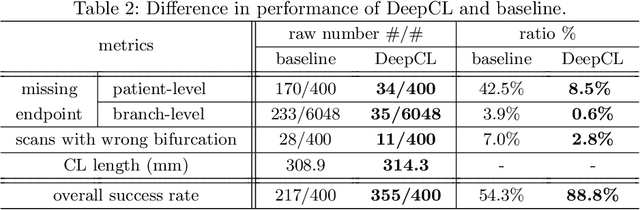
A novel centerline extraction framework is reported which combines an end-to-end trainable multi-task fully convolutional network (FCN) with a minimal path extractor. The FCN simultaneously computes centerline distance maps and detects branch endpoints. The method generates single-pixel-wide centerlines with no spurious branches. It handles arbitrary tree-structured object with no prior assumption regarding depth of the tree or its bifurcation pattern. It is also robust to substantial scale changes across different parts of the target object and minor imperfections of the object's segmentation mask. To the best of our knowledge, this is the first deep-learning based centerline extraction method that guarantees single-pixel-wide centerline for a complex tree-structured object. The proposed method is validated in coronary artery centerline extraction on a dataset of 620 patients (400 of which used as test set). This application is challenging due to the large number of coronary branches, branch tortuosity, and large variations in length, thickness, shape, etc. The proposed method generates well-positioned centerlines, exhibiting lower number of missing branches and is more robust in the presence of minor imperfections of the object segmentation mask. Compared to a state-of-the-art traditional minimal path approach, our method improves patient-level success rate of centerline extraction from 54.3% to 88.8% according to independent human expert review.
Residual Attention based Network for Hand Bone Age Assessment
Dec 21, 2018

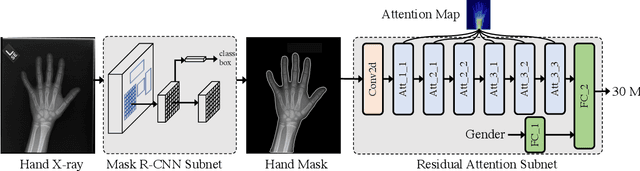

Computerized automatic methods have been employed to boost the productivity as well as objectiveness of hand bone age assessment. These approaches make predictions according to the whole X-ray images, which include other objects that may introduce distractions. Instead, our framework is inspired by the clinical workflow (Tanner-Whitehouse) of hand bone age assessment, which focuses on the key components of the hand. The proposed framework is composed of two components: a Mask R-CNN subnet of pixelwise hand segmentation and a residual attention network for hand bone age assessment. The Mask R-CNN subnet segments the hands from X-ray images to avoid the distractions of other objects (e.g., X-ray tags). The hierarchical attention components of the residual attention subnet force our network to focus on the key components of the X-ray images and generate the final predictions as well as the associated visual supports, which is similar to the assessment procedure of clinicians. We evaluate the performance of the proposed pipeline on the RSNA pediatric bone age dataset and the results demonstrate its superiority over the previous methods.
Optimal Multi-Object Segmentation with Novel Gradient Vector Flow Based Shape Priors
May 22, 2017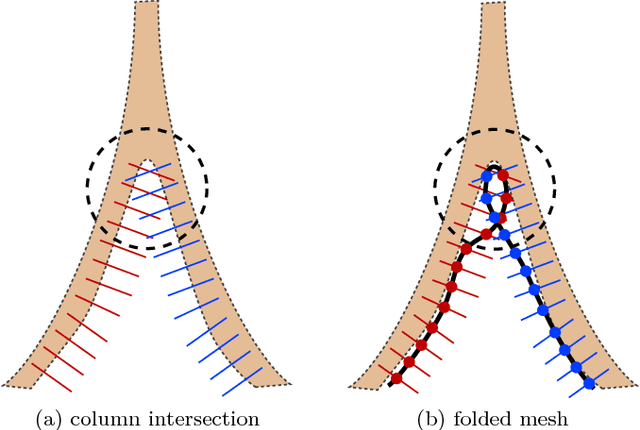
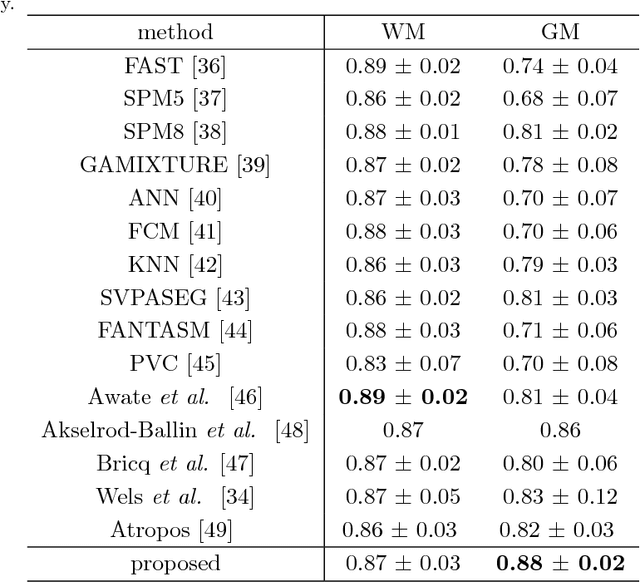
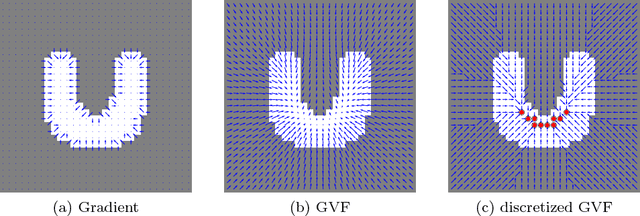
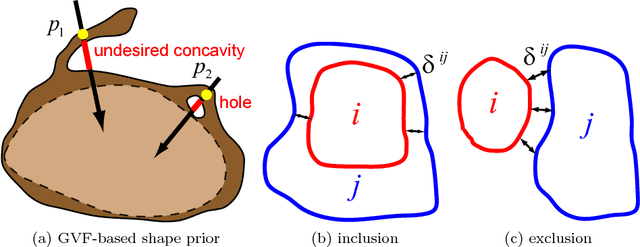
Shape priors have been widely utilized in medical image segmentation to improve segmentation accuracy and robustness. A major way to encode such a prior shape model is to use a mesh representation, which is prone to causing self-intersection or mesh folding. Those problems require complex and expensive algorithms to mitigate. In this paper, we propose a novel shape prior directly embedded in the voxel grid space, based on gradient vector flows of a pre-segmentation. The flexible and powerful prior shape representation is ready to be extended to simultaneously segmenting multiple interacting objects with minimum separation distance constraint. The problem is formulated as a Markov random field problem whose exact solution can be efficiently computed with a single minimum s-t cut in an appropriately constructed graph. The proposed algorithm is validated on two multi-object segmentation applications: the brain tissue segmentation in MRI images, and the bladder/prostate segmentation in CT images. Both sets of experiments show superior or competitive performance of the proposed method to other state-of-the-art methods.
Optimal Multiple Surface Segmentation with Convex Priors in Irregularly Sampled Space
May 16, 2017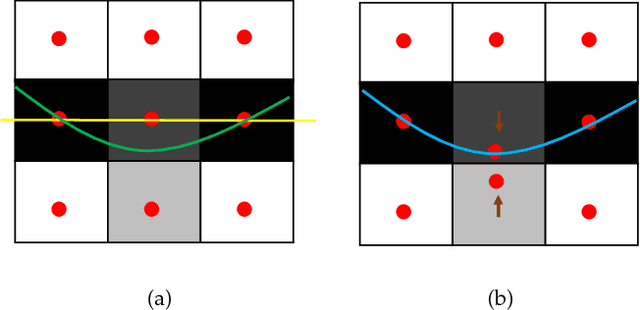
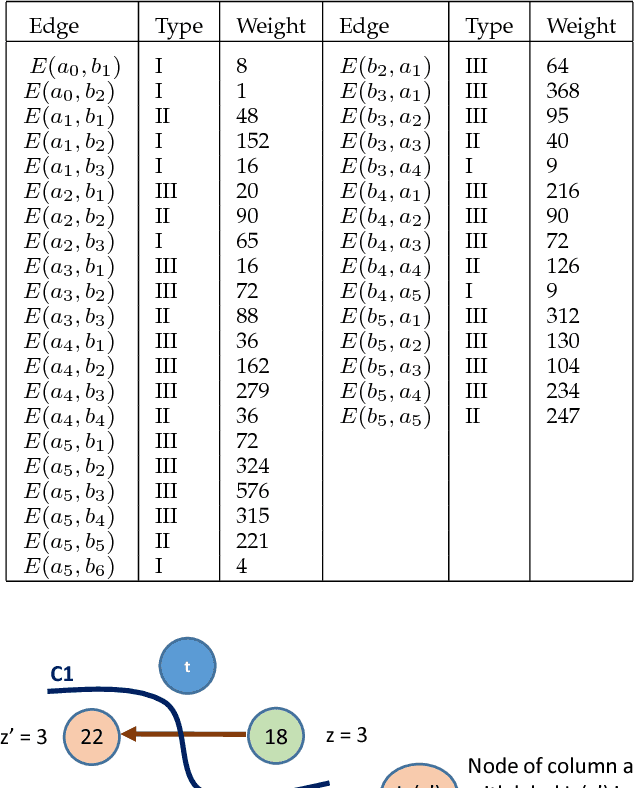
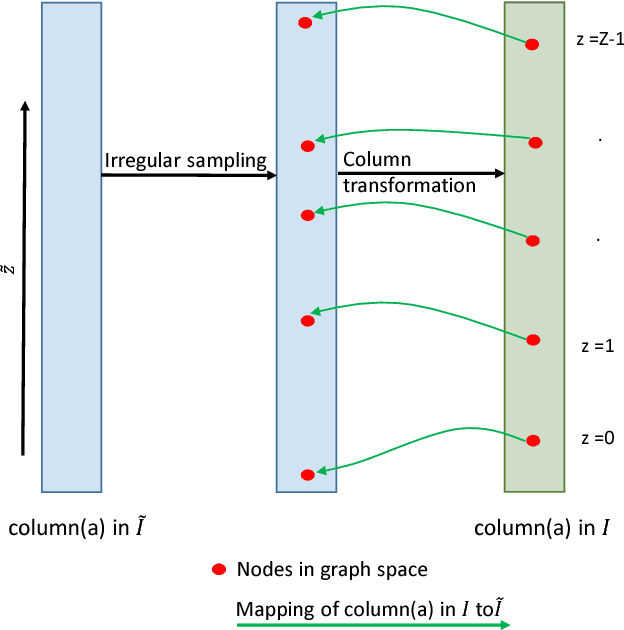
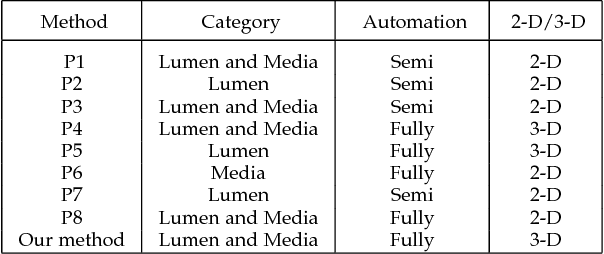
Optimal surface segmentation is widely used in numerous medical image segmentation applications. However, nodes in the graph based optimal surface segmentation method typically encode uniformly distributed orthogonal voxels of the volume. Thus the segmentation cannot attain an accuracy greater than a single unit voxel, i.e. the distance between two adjoining nodes in graph space. Segmentation accuracy higher than a unit voxel is achievable by exploiting partial volume information in the voxels which shall result in non-equidistant spacing between adjoining graph nodes. This paper reports a generalized graph based optimal multiple surface segmentation method with convex priors which segments the target surfaces in irregularly sampled space. The proposed method allows non-equidistant spacing between the adjoining graph nodes to achieve subvoxel accurate segmentation by utilizing the partial volume information in the voxels. The partial volume information in the voxels is exploited by computing a displacement field from the original volume data to identify the subvoxel accurate centers within each voxel resulting in non-equidistant spacing between the adjoining graph nodes. The smoothness of each surface modelled as a convex constraint governs the connectivity and regularity of the surface. We employ an edge-based graph representation to incorporate the necessary constraints and the globally optimal solution is obtained by computing a minimum s-t cut. The proposed method was validated on 25 optical coherence tomography image volumes of the retina and 10 intravascular multi-frame ultrasound image datasets for subvoxel and super resolution segmentation accuracy. In all cases, the approach yielded highly accurate results. Our approach can be readily extended to higher-dimensional segmentations.